
Artificial Neural Networks
Mid-term Homework:Facial Expression Recognition (FER)
Student ID: 21307381 Student Name: LJW
Date: 2024.5.1
Lectured by: Xiaojun Quan
Machine Learning and Data Mining Course
Sun Yat-sen University
实验任务
任务定义及数据集
任务定义:对于给定的人脸图片,输出其表情标签(图像分类任务);
一共包含五种表情: Angry, Happy, Neutral, Sad, Surprise,已经进行了训练集和测试集的划分,数据规模如下(数据集中存在一定的不平衡);
| 情绪标签 | 训练集样本数 | 测试集样本数 |
|---|---|---|
| Angry | 500 | 100 |
| Happy | 1500 | 100 |
| Neutral | 1000 | 100 |
| Sad | 1500 | 100 |
| Surprise | 500 | 100 |
作业要求
- python 环境
- 深度学习框架使用 pytorch;
- 请提交 requirement.txt,包含必要的第三方包即可;
- 模型的构建和训练
- 自行设计卷积神经网络对人脸特征进行抽取,并通过全连接层进行分类;
- 不允许加载现成的预训练模型或图像分类包;
- 可以参考经典 CNN 结构(AlexNet、 VGG、 Resnet 等);
- 可以自行探索网络结构对性能的影响;
- 模型测试
- 使用已经划分的测试集对训练好的模型进行测试,计算准确率,和每个类别的召回率、精准率, Macro-F1 等;
- 请勿使用测试集进行训练(作弊);
提交内容
- 代码 +requirement.txt
- 训练好的 checkpoint
- README:使用指南(如何进行训练、评测)
- 文档:对你所实现的内容进行详细阐述;包括但不限于:
- 数据预处理的操作
- 超参数的设置
- 模型的架构设计
- 验证方法(划分验证集进行验证)
- 结果分析- 自己的探索和心得体会;
数据预处理
- 图像变换:
- 使用
torchvision.transforms模块进行图像预处理,包括:- 随机裁剪:
RandomResizedCrop(224): 随机调整并裁剪图像到指定大小(224x224),保持图像内容的同时适应网络输入尺寸。 - 随机水平翻转
RandomHorizontalFlip(): 随机水平翻转图像,增加了数据集的多样性,有助于模型泛化。 - 转换为张量:
ToTensor(): 将PIL图像或numpy数组转换为PyTorch的Tensor,并将颜色通道从[H, W, C]调整为[C, H, W],同时将像素值从0-255范围归一化到0-1范围。 - 归一化:使用
transforms.Normalize对图像张量进行归一化处理,即每个通道减去均值后除以标准差。代码中将均值和标准差分别设置为(0.5, 0.5, 0.5)
- 随机裁剪:
- 使用
- 数据集划分:
- 通过
ImageFolder函数加载数据集,自动将数据分为训练集和验证集(基于提供的“train”和“test”目录),这是数据集成的一部分,确保模型在未见过的数据上进行验证。
- 通过
- 批量处理和数据加载器:
- 使用
DataLoader创建数据加载器,其中shuffle=True是为了在训练时随机打乱数据顺序,减少模型学习到的顺序相关性,提高泛化能力。同时,num_workers参数指定了用于数据加载的子进程数量,可以加速数据预处理和加载过程。
- 使用
AlexNet
模型的架构设计
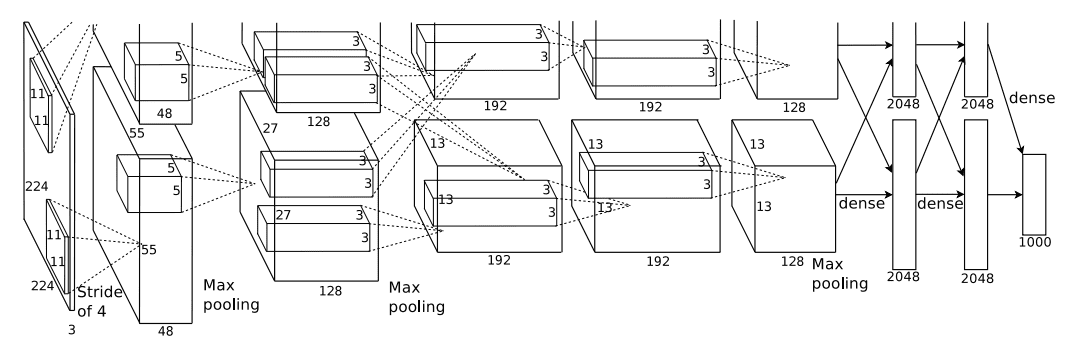
-
输入层:模型接受输入图像的尺寸是[3, 224, 224],即具有3个颜色通道的224x224像素图像。
-
卷积层序列:模型包含多个卷积层,每个卷积层后面紧跟一个ReLU激活函数,除了最后一个卷积层后面没有ReLU,因为它后面紧跟一个池化层。
- 第一个卷积层
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2):输入通道数为3,输出通道数为96,使用11x11的卷积核,步长为4,填充为2。这会将图像尺寸减小到[96, 55, 55]。
- 第一个卷积层
-
接着是最大池化层
nn.MaxPool2d(kernel_size=3, stride=2):使用3x3的池化核,步长为2,这会进一步将图像尺寸减小到[96, 27, 27]。 -
后续是三个卷积层,分别将通道数从96增加到256,再增加到384,然后是两次384到384,最后减少到256。这些层的卷积核大小逐渐从5x5变为3x3,步长大多为1,填充为2或1。
-
最后一个最大池化层将图像尺寸减小到[256, 6, 6]。
-
全连接层:在卷积层之后,模型包含三个全连接层。第一个全连接层
nn.Linear(256 * 6 * 6, 4096)将卷积层的输出特征图展平后,映射到4096维的空间。接下来的两个全连接层都是4096维的,最后一个全连接层将特征映射到num_classes的类别数。 -
Dropout正则化:在前两个全连接层之间,模型使用了Dropout正则化,丢弃率为0.5,以减少过拟合。
超参数设置
| 超参数 | 意义 | 数值 |
|---|---|---|
| init_weights | 用什么方式初始化权重 | 用Kaiming初始化方法初始化卷积层的权重,并使用正态分布初始化全连接层的权重 |
| batch_size | 每个训练批次中的样本数量 | 32 |
| optimizer | 用于模型参数优化的算法 | Adam优化器 |
| lr (learning rate) | 学习率,控制着在每次迭代中更新模型权重的大小 | 0.0002 |
| epochs | 训练模型的轮数,即整个数据集被遍历的次数。 | 100 |
| loss_function | 计算模型预测和真实标签之间差异的函数 | 交叉熵损失(CrossEntropyLoss) |
AlexNet结果
最好结果
1
2
3
4
5
6
7
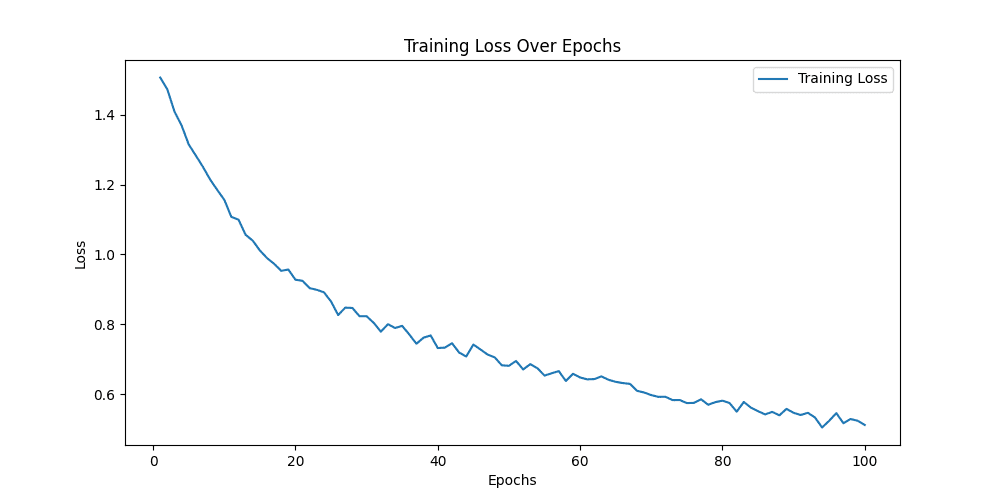
train epoch[87/100] loss:0.334: 100%|██████████| 157/157 [00:33<00:00, 4.72it/s]
100%|██████████| 125/125 [00:24<00:00, 5.13it/s]
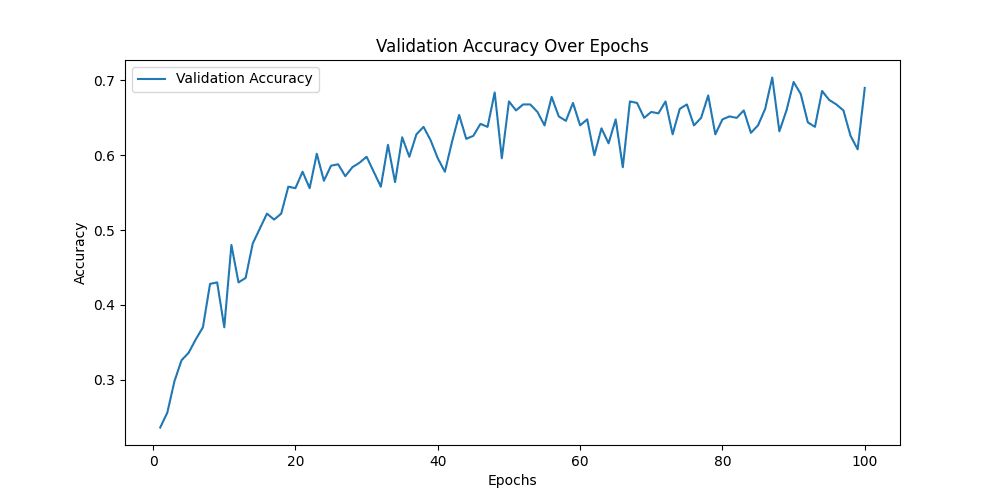
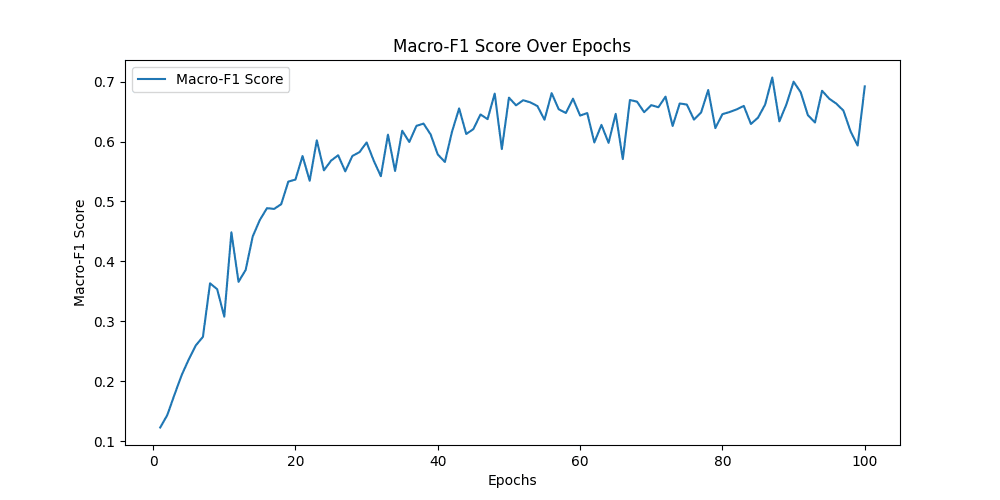
[epoch 87] train_loss: 0.562 val_accuracy: 0.704
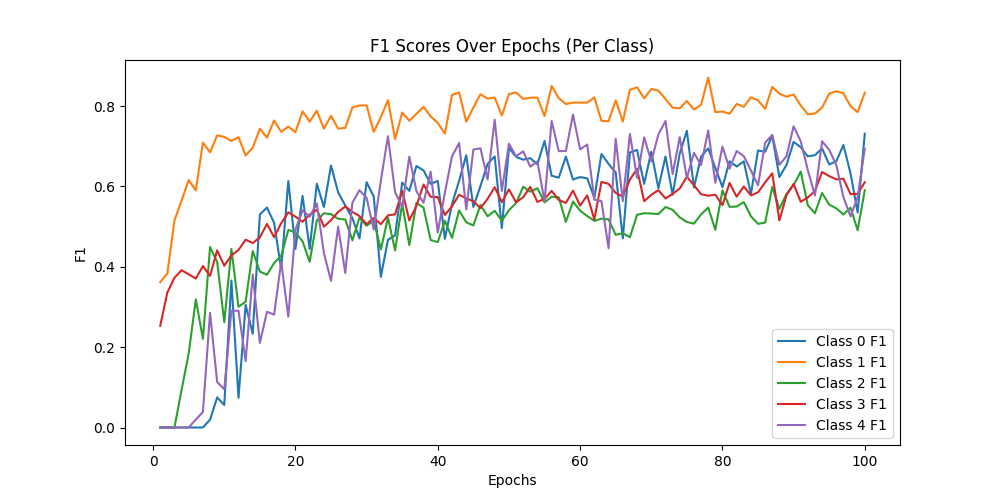
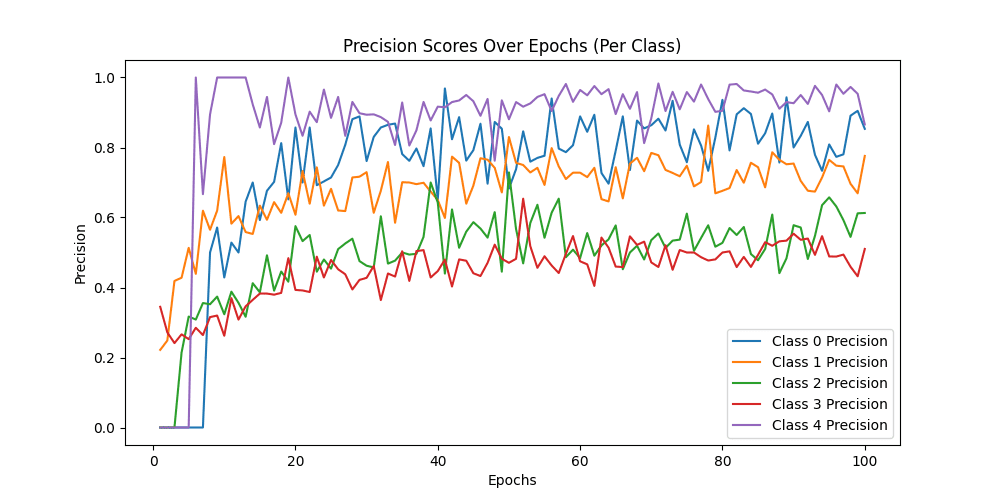
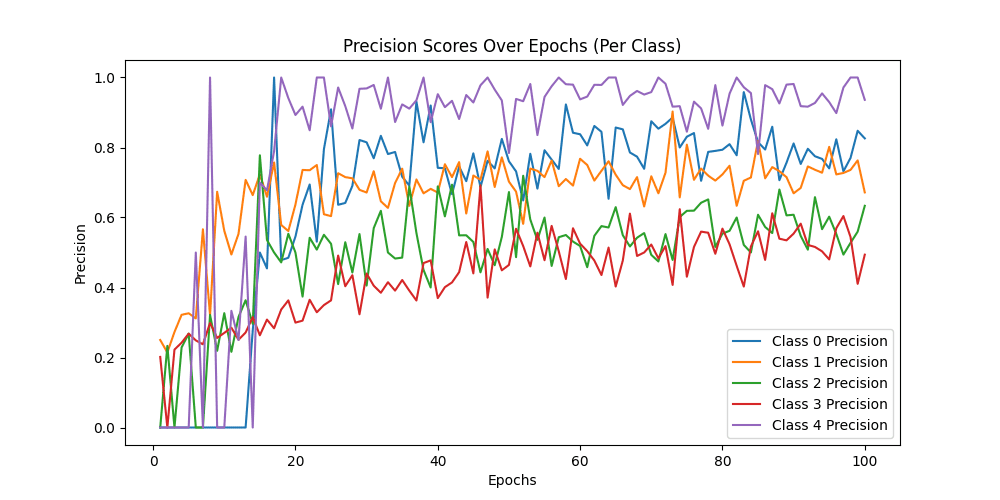
Class-wise Precision: [0.89705882 0.78632479 0.60824742 0.51923077 0.9516129 ]
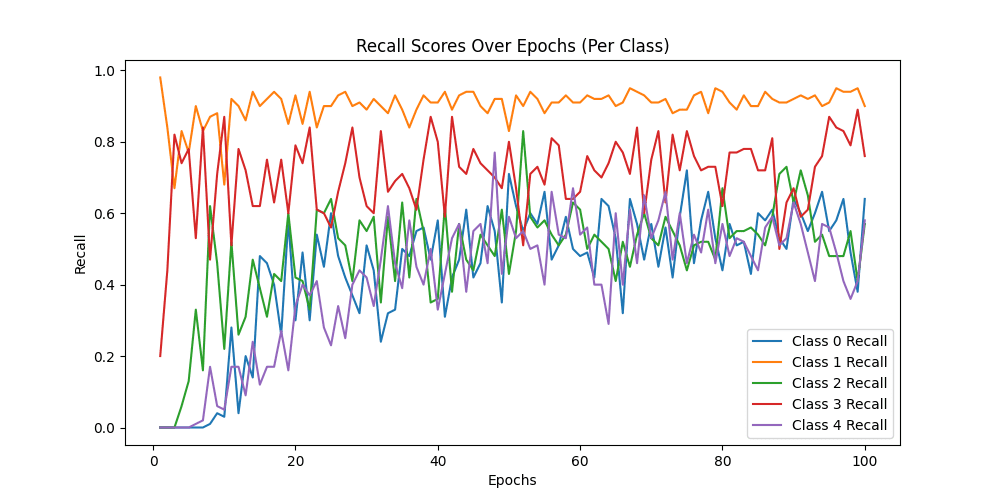
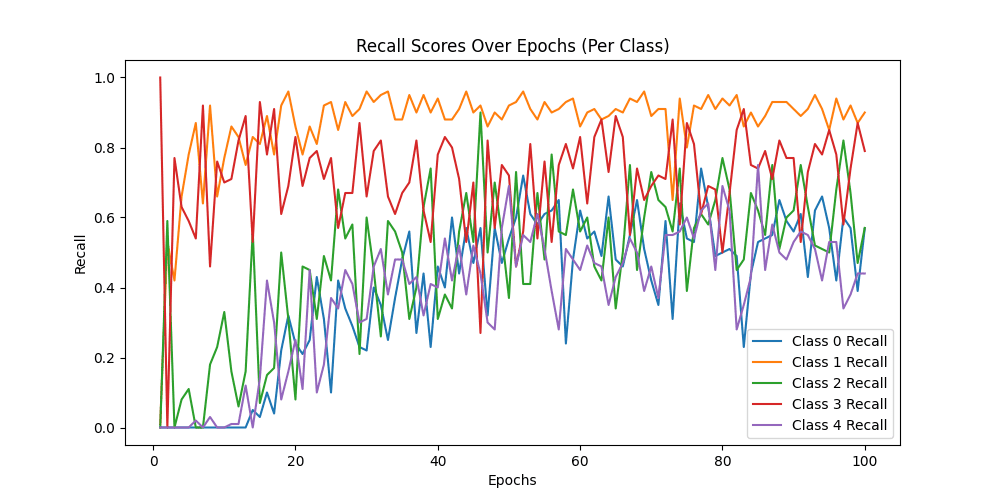
Class-wise Recall: [0.61 0.92 0.59 0.81 0.59]
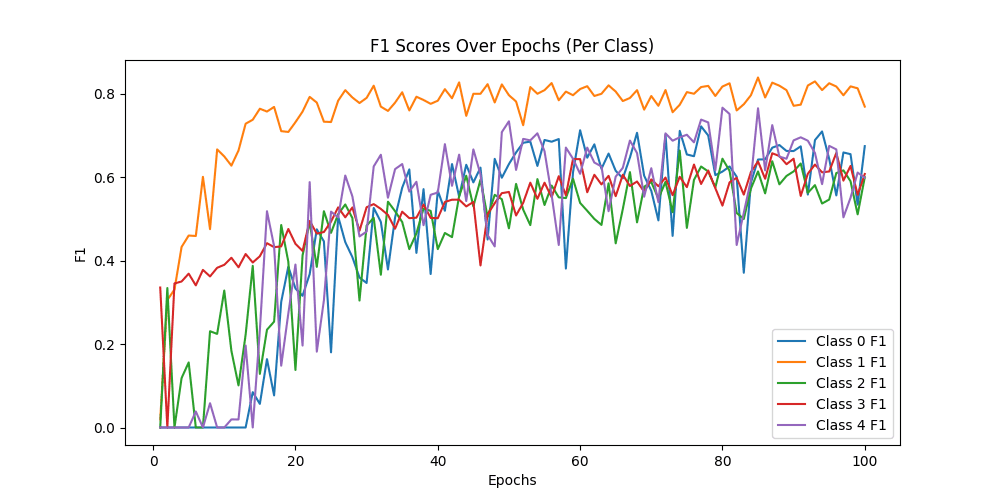
Class-wise F1-score: [0.72619048 0.84792627 0.59898477 0.6328125 0.72839506]
Macro-F1 Score: 0.7068618153547163
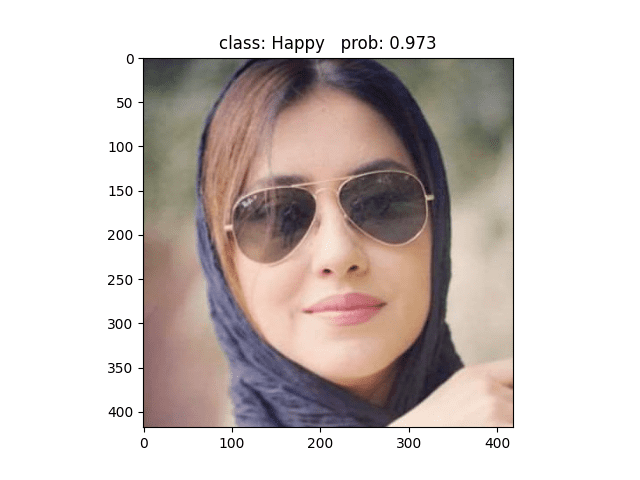
用这张照片预测,模型预测为Happy,但其实这张照片的标签属于Neural类别 ❌
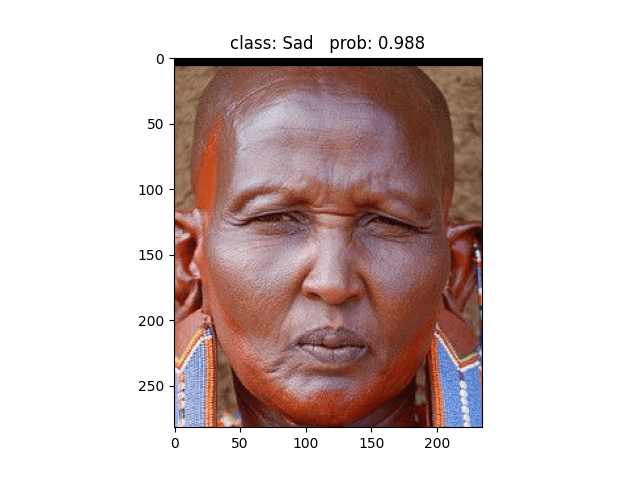
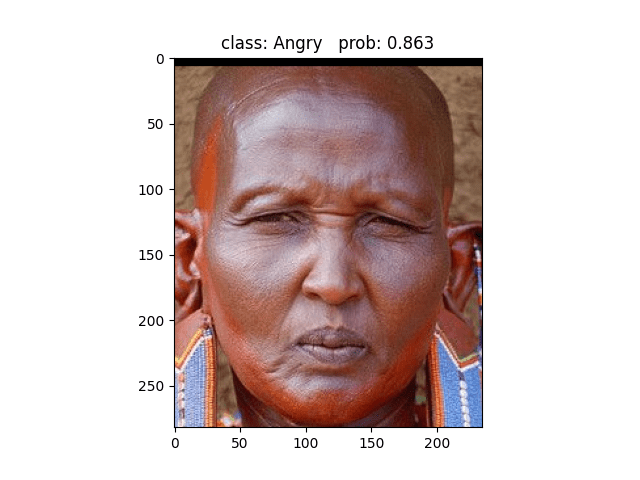
用这张照片预测,模型预测为Sad,但其实这张照片的标签属于Angry类别 ❌
用这张照片预测,模型预测为Neural,但其实这张照片的标签属于Sad类别 ❌,但是我认为这张照片是可以预测为Neutral的

ResNet
残差网络的核心思想是引入了“残差学习”来解决深度网络中的梯度消失问题,允许训练更深层次的网络结构。以下是模型架构的详细描述:
模型的架构设计
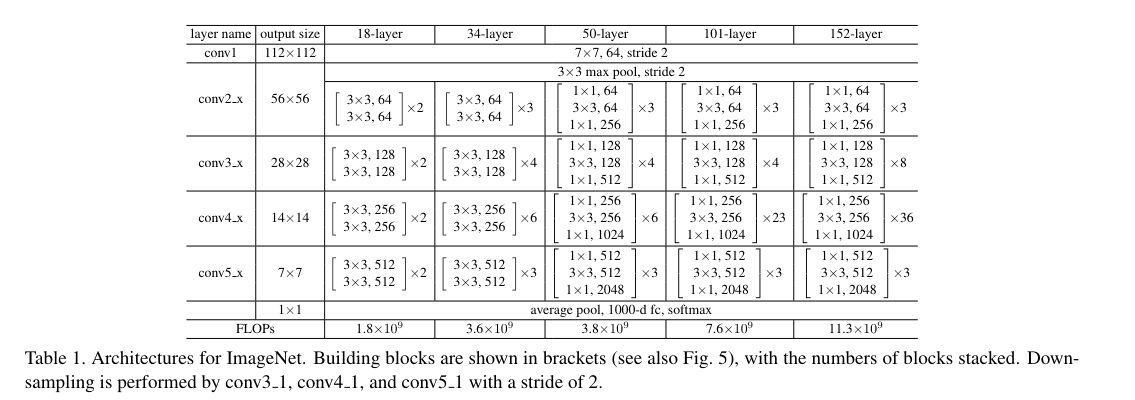
-
卷积层 (
nn.Conv2d): 用于执行卷积操作,是网络中的基本构建块,用于提取图像特征。 -
批量归一化 (
nn.BatchNorm2d): 用于归一化卷积层的输出,有助于加快训练速度并提高模型稳定性。 -
激活函数 (
nn.ReLU): 用于在卷积和归一化后引入非线性,ReLU(Rectified Linear Unit)是最常用的激活函数。
残差块
-
BasicBlock: 基础残差块,适用于输入和输出具有相同维度的情况。它包含两个卷积层,每层后都有批量归一化和ReLU激活函数。
-
Bottleneck: 瓶颈残差块,用于减少计算量,适用于输入和输出维度不同的下采样操作。它包含三个卷积层:第一个1x1卷积层用于降维(squeeze),第二个3x3卷积层用于特征提取,第三个1x1卷积层用于升维(unsqueeze)。在瓶颈块中,第一个1x1卷积层的步长是1,而3x3卷积层的步长是2。
下采样(Downsample)
当残差块用于下采样时,会引入一个额外的卷积层,用于将输入映射到与残差块相同的输出维度。这通常发生在网络的不同层之间,例如从第一层到第二层,输入通道数会翻倍。
ResNet类
ResNet类是整个网络的顶层设计,它初始化了网络的输入层、多个残差块层、一个平均池化层和一个全连接层(如果include_top=True)。网络的输入层是一个7x7的卷积层,后接最大池化层。
-
输入层: 一个7x7的卷积层,步长为2,用于将输入图像的尺寸减小,并提取初级特征。
-
残差块层 (
self.layer1,self.layer2,self.layer3,self.layer4): 由多个残差块组成,每一层的残差块数量由blocks_num列表指定。每一层的输出通道数分别为64、128、256和512。 -
平均池化层 (
self.avgpool): 将经过多层残差块处理的特征图进行平均池化,输出尺寸为(1, 1)。 -
全连接层 (
self.fc): 将平均池化后的输出展平,并映射到最终的类别数量。
模型的架构设计遵循了残差网络(ResNet)的通用结构:
- 输入层 (
self.conv1):- 一个7x7的卷积层,用于将输入图像从原始尺寸降维,并开始特征提取过程。
- 步长(stride)为2,这有助于减少特征图的空间维度。
- 填充(padding)为3,以保持一定的图像尺寸。
- 批量归一化层 (
self.bn1):- 对上述卷积层的输出进行归一化处理。
- 激活函数 (
self.relu):- 使用ReLU激活函数引入非线性。
- 最大池化层 (
self.maxpool):- 使用3x3的最大池化进一步降低特征图的空间尺寸,步长为2。
- 残差块层1 (
self.layer1):- 由多个BasicBlock或Bottleneck块组成,具体取决于构建的是哪种ResNet变体。
- 这些块的输出通道数为64。
- 残差块层2 (
self.layer2):- 同样由多个残差块组成,输出通道数增至128,并且通过下采样将特征图的空间尺寸再次减半。
- 残差块层3 (
self.layer3):- 输出通道数增至256。
- 残差块层4 (
self.layer4):- 输出通道数增至512。
- 平均池化层 (
self.avgpool):- 如果
include_top=True,网络将包括一个平均池化层,将多维的特征图转换为一个1x1的特征向量。
- 如果
- 全连接层 (
self.fc):- 一个线性层,将1x1的特征向量映射到最终的类别数量,即网络的输出。
在这段代码中,_make_layer函数用于创建由残差块组成的层。每一层的残差块数量由blocks_num列表指定,例如对于ResNet34,这个列表是[3, 4, 6, 3],表示每一层包含的残差块数量分别为3、4、6和3个。
我使用的是resnet34,因为太深的模型的计算量太大了,但是我也定义了resnet50和resnet101,有足够的计算量的话可以尝试。
超参数设置
| 超参数 | 意义 | 数值 |
|---|---|---|
| init_weights | 用什么方式初始化权重 | 用Kaiming初始化方法初始化卷积层的权重,并使用正态分布初始化全连接层的权重 |
| batch_size | 每个训练批次中的样本数量 | 16 |
| optimizer | 用于模型参数优化的算法 | Adam优化器 |
| lr (learning rate) | 学习率,控制着在每次迭代中更新模型权重的大小 | 0.0001 |
| epochs | 训练模型的轮数,即整个数据集被遍历的次数。 | 80 |
| loss_function | 计算模型预测和真实标签之间差异的函数 | 交叉熵损失(CrossEntropyLoss) |
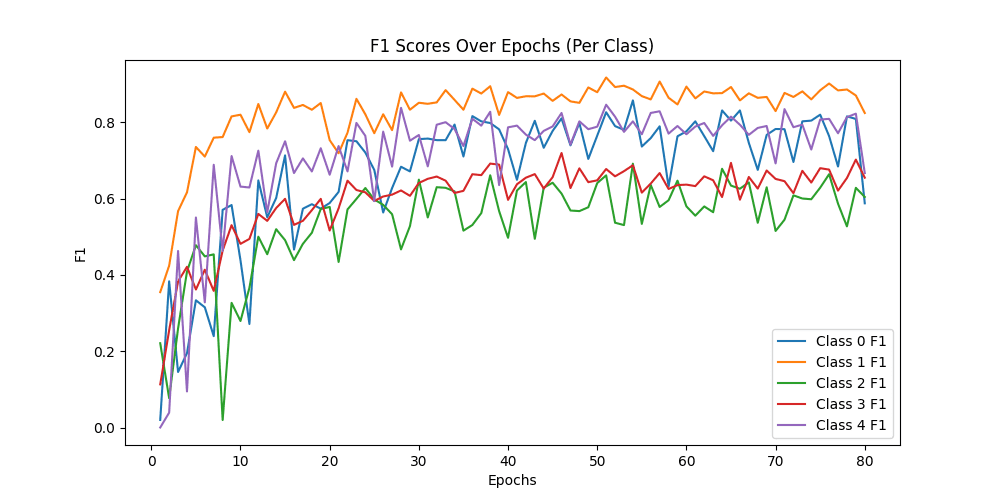
ResNet34结果
最好结果
1
2
3
4
5
6
7
8
9
10
11
train epoch[51/80] loss:0.288: 100%|██████████| 313/313 [00:51<00:00, 6.09it/s]
valid epoch[51/80]: 100%|██████████| 32/32 [00:26<00:00, 1.23it/s]
[epoch 51] train_loss: 0.577 val_accuracy: 0.784
Class Precision Recall F1-score Macro-F1
-------------------------------------------------------------------------------------------------------------------------------
Class 0: 0.9047619047619048 0.76 0.8260869565217391
Class 1: 0.8952380952380953 0.94 0.9170731707317075
Class 2: 0.6033057851239669 0.73 0.6606334841628959
Class 3: 0.7191011235955056 0.64 0.6772486772486772
Class 4: 0.8415841584158416 0.85 0.845771144278607
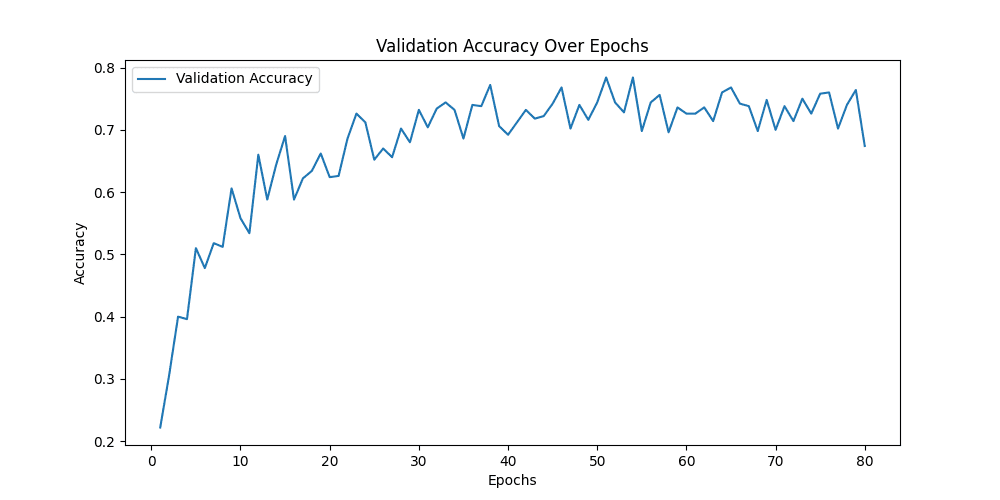
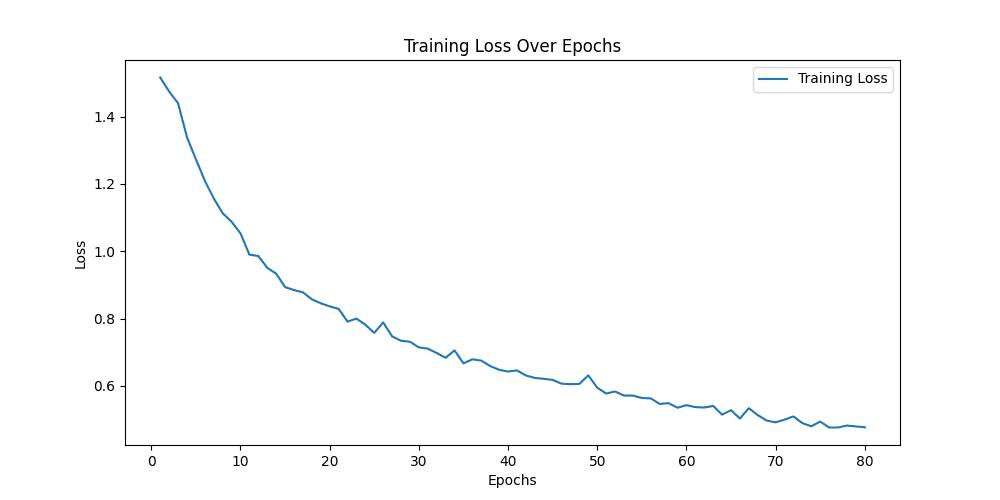
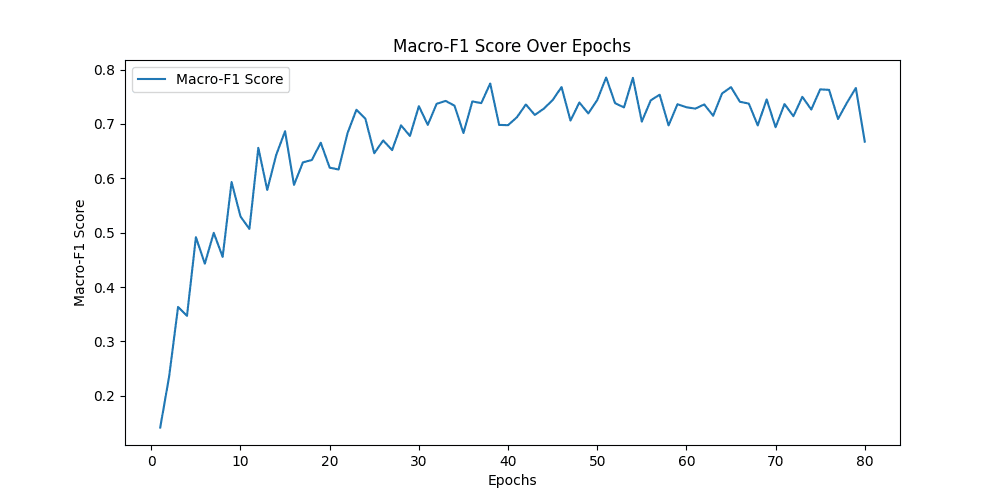
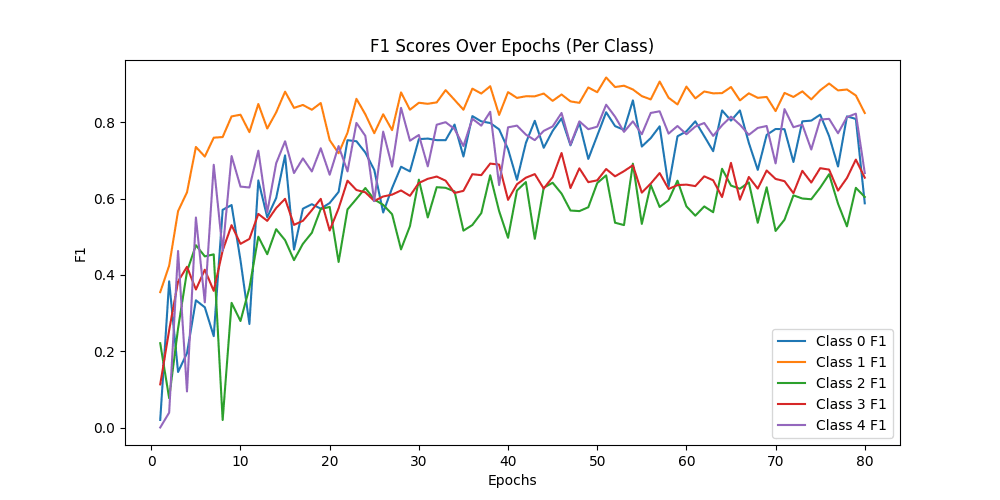
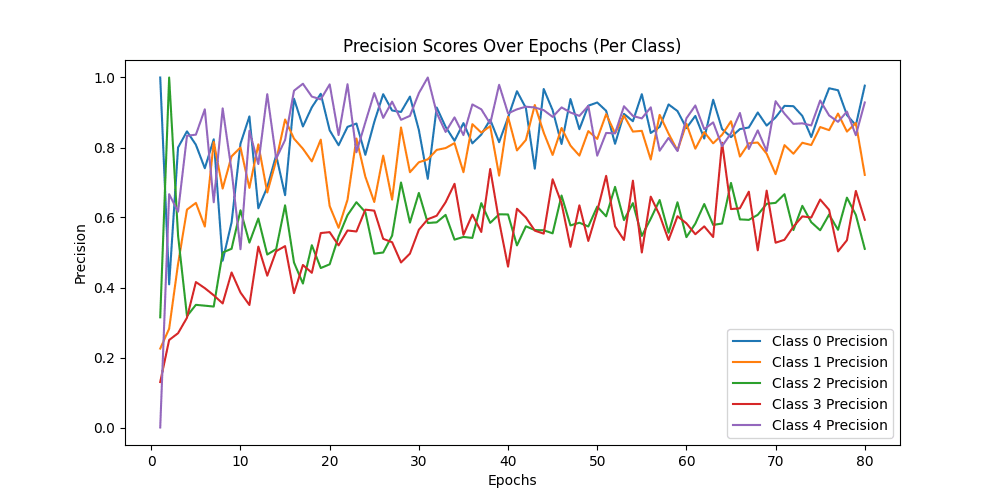
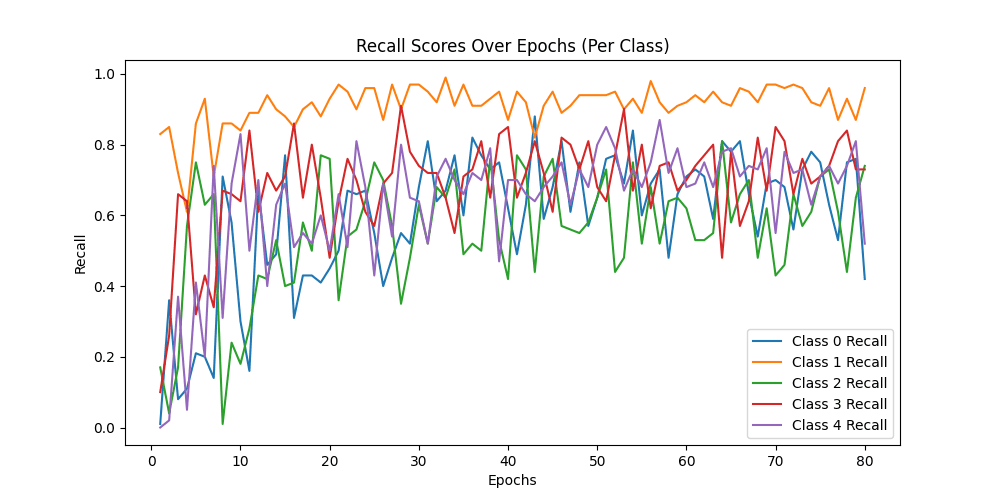
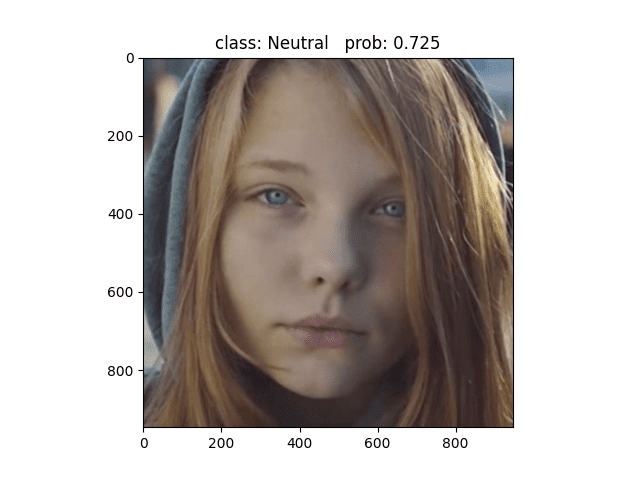
用Resnet34模型做预测,同样的图片可以精确的预测为Neutral,与标签一致,说明Resnet捕捉到了Alexnet无法捕捉到的细节 ✔
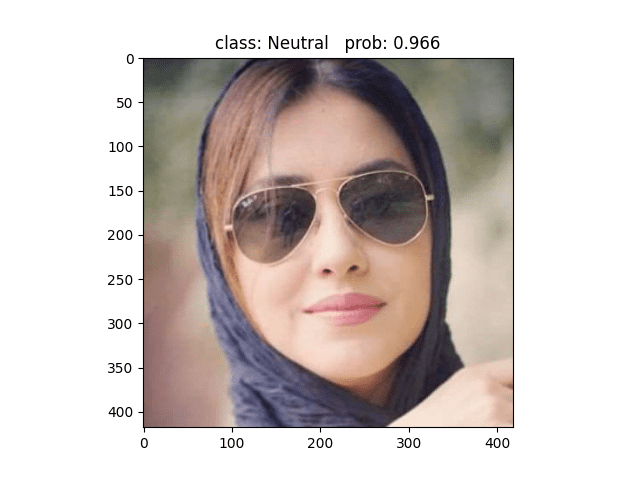
下面这张图片同样预测正确
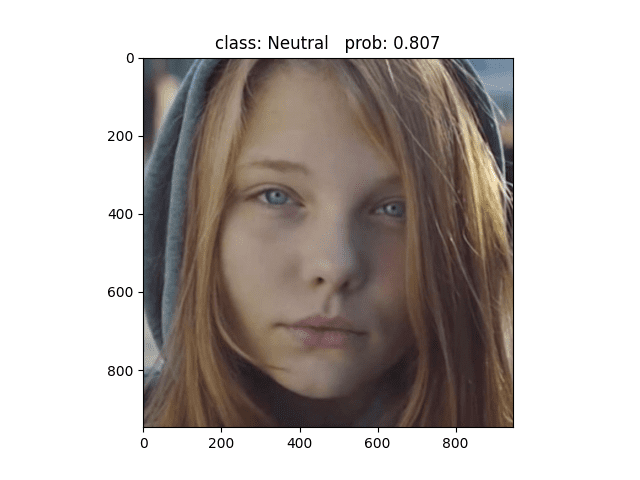
用这张照片预测,模型预测为Neutral,但其实这张照片的标签属于Sad类别,但是我认为这张照片是可以预测为Neutral的
VGG11
模型的架构设计
VGG 网络是一个经典的深度学习模型,主要应用于图像识别任务。VGG 网络由多个卷积层和池化层组成,后面跟随全连接层。
make_features函数:
- 这个函数根据提供的配置列表
cfg构建网络的卷积和池化层。 - 它接受一个列表
cfg作为参数,列表中的每个元素代表一个卷积层的输出通道数或一个池化操作(用字符串 “M” 表示)。 - 函数内部使用一个循环来添加卷积层和 ReLU 激活函数到
layers列表中,每经过一个 “M” 元素,就添加一个最大池化层。
我使用的VGG11(具有 11 个卷积层的 VGG 网络)由以下层组成:'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
输入层
- 输入尺寸:通常为224x224像素的RGB图像。
卷积块
VGG11网络由多个卷积块组成,每个块包含若干卷积层后紧跟一个最大池化层(Max Pooling),并且所有卷积层都使用了ReLU激活函数。
- Block 1:
- 卷积层:1个,3x3卷积核,输入通道3(RGB),输出通道64,无填充(padding=1保持尺寸不变),步长默认为1。
- 最大池化层:2x2核,步长2,用于下采样。
- Block 2:
- 卷积层:1个,3x3卷积核,输入通道64,输出通道128,padding以保持尺寸。
- 最大池化层:同上。
- Block 3:
- 卷积层:2个,均为3x3卷积核,第一个卷积层输入通道128,输出通道256;第二个卷积层输入通道同样为256,输出通道也是256。
- 最大池化层:同上。
- Block 4:
- 卷积层:2个,均为3x3卷积核,输入通道256,输出通道512。
- 最大池化层:同上。
- Block 5:
- 卷积层:2个,均为3x3卷积核,输入通道512,输出通道512。
- 最大池化层:同上。
全连接层
- Flatten:将最后一个池化层的输出展平成一维向量。
- 全连接层 1:输入维度根据之前卷积层输出决定,通常很大,输出维度为4096,使用ReLU激活。
- 全连接层 2:输入4096,输出4096,使用ReLU激活。
- 输出层:输入4096,输出维度根据分类任务决定,比如1000类别时输出为1000,使用softmax函数进行概率输出。
vgg11 是VGG系列中较浅的网络,它有11层深(包括卷积层、池化层和全连接层),因此它比更深的VGG网络(如VGG16或VGG19)训练和推理的速度更快,但可能在特征提取能力上有所不足,但是我的算力不足所以选择了使用vgg11
超参数设置
| 超参数 | 意义 | 数值 |
|---|---|---|
| init_weights | 用什么方式初始化权重 | 用xavier初始化方法初始化权重 |
| batch_size | 每个训练批次中的样本数量 | 32 |
| optimizer | 用于模型参数优化的算法 | Adam优化器 |
| lr (learning rate) | 学习率,控制着在每次迭代中更新模型权重的大小 | 0.0001 |
| epochs | 训练模型的轮数,即整个数据集被遍历的次数。 | 70 |
| loss_function | 计算模型预测和真实标签之间差异的函数 | 交叉熵损失(CrossEntropyLoss) |
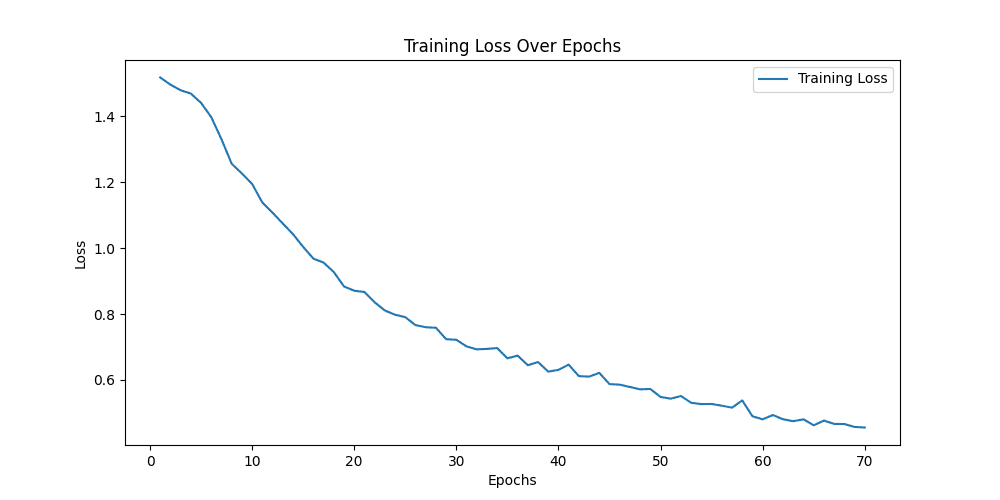
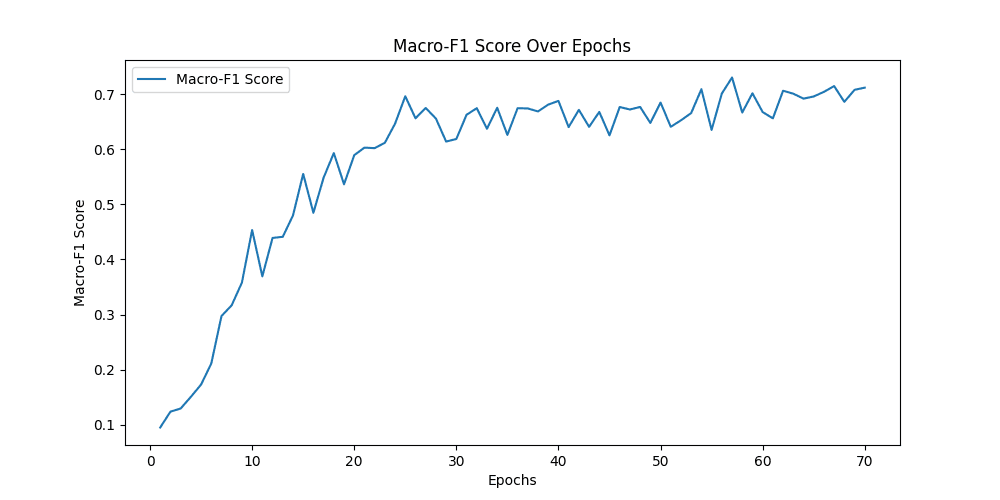
结果
1
2
3
4
5
6
7
8
9
10
11
12
train epoch[54/70] loss:0.220: 100%|██████████| 157/157 [01:04<00:00, 2.45it/s]
100%|██████████| 16/16 [00:26<00:00, 1.65s/it]
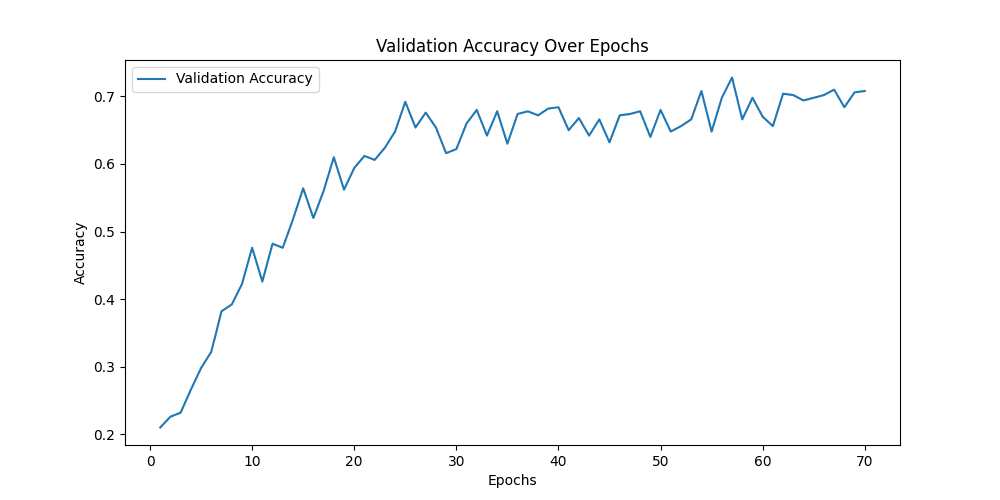
[epoch 54] train_loss: 0.527 val_accuracy: 0.708
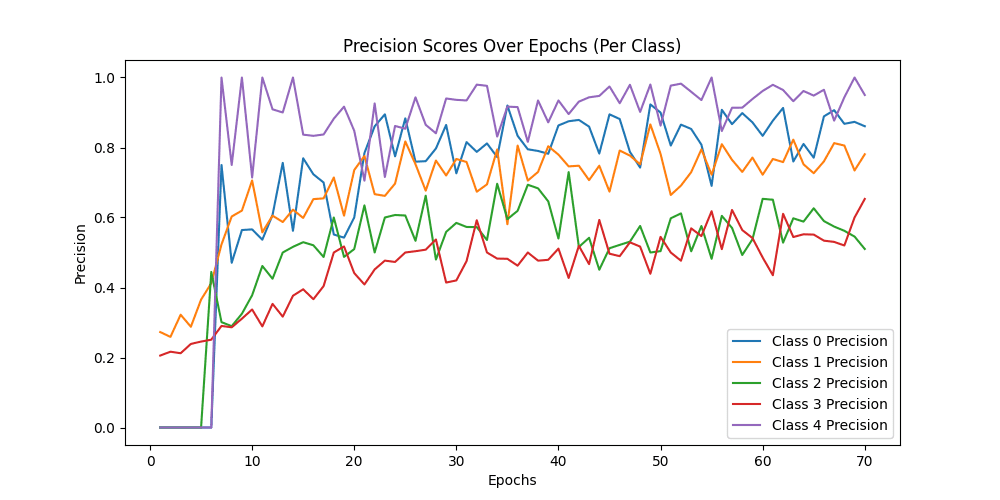
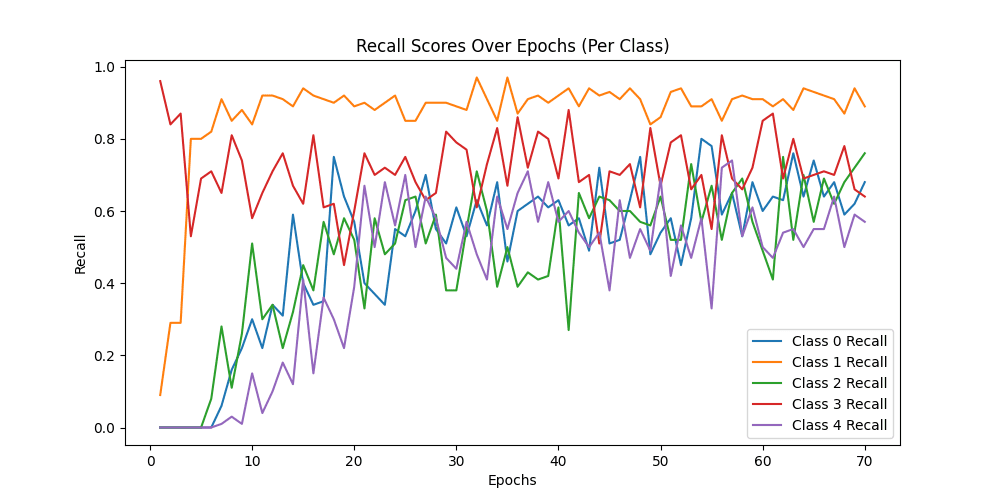
Class Precision Recall F1-score Macro-F1
-------------------------------------------------------------------------------------------------------------------------------
Class 0: 0.8080808080808081 0.8 0.8040201005025126
Class 1: 0.7946428571428571 0.89 0.839622641509434
Class 2: 0.5757575757575758 0.57 0.5728643216080402
Class 3: 0.546875 0.7 0.6140350877192983
Class 4: 0.9354838709677419 0.58 0.7160493827160493
0.7093183068110669
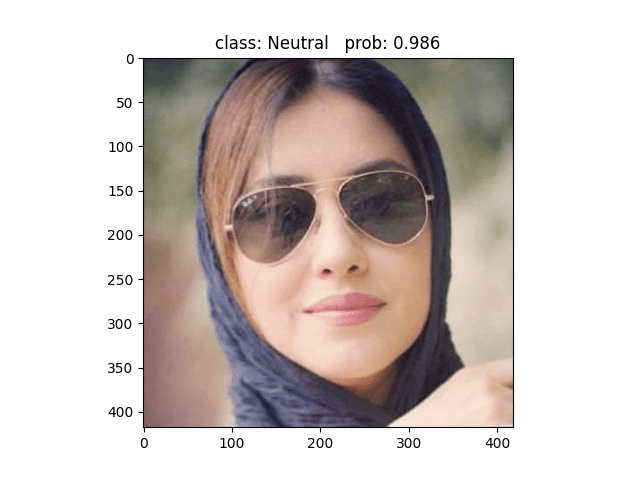
用VGG11模型做预测,同样的图片可以精确的预测为Neutral,与标签一致,说明VGG11捕捉到了Alexnet无法捕捉到的细节 ✔
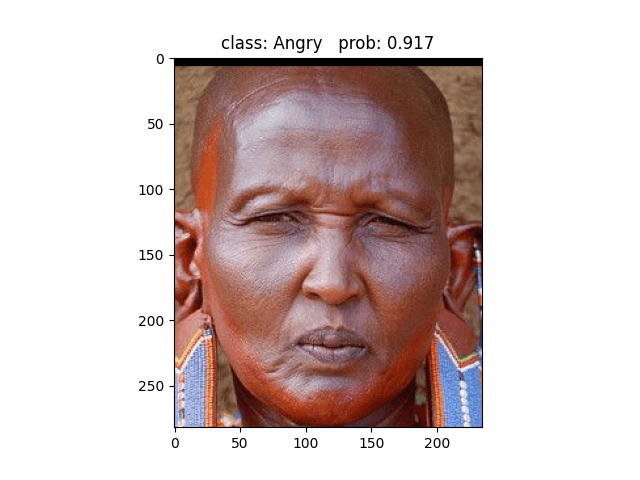
预测正确 ✔
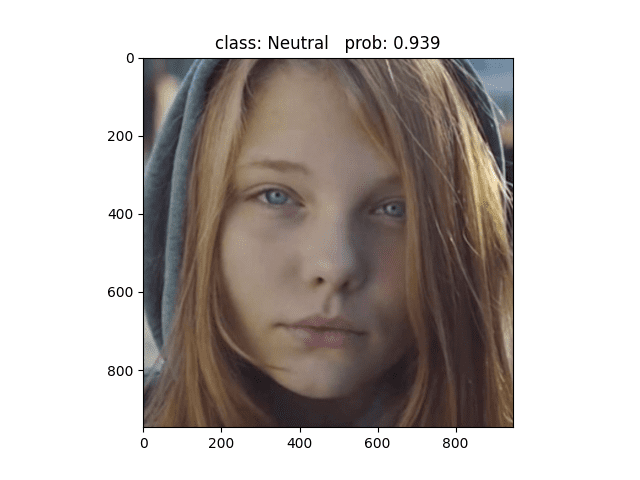
预测错误,但是我认为这张照片是可以预测为Neutral的
GoogleNet
模型的架构设计
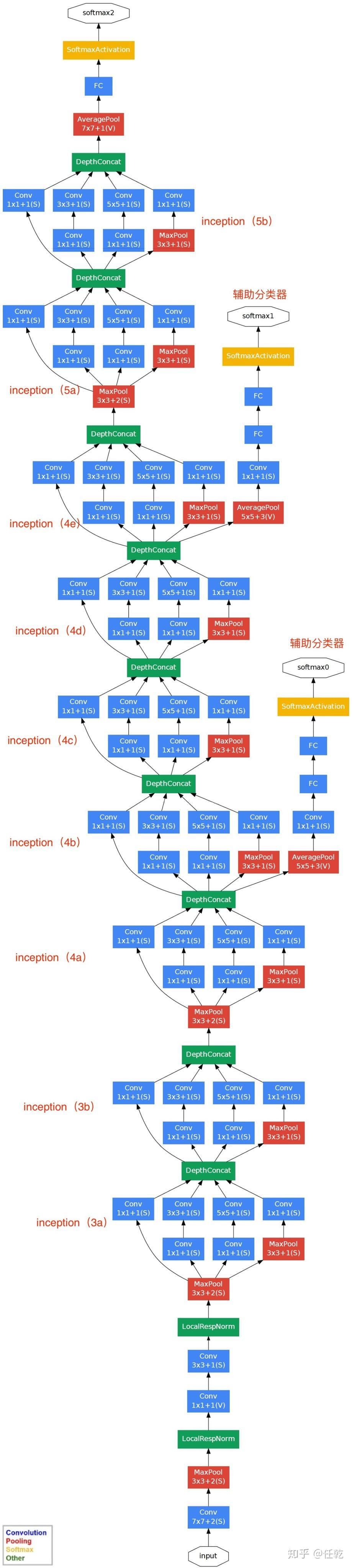
它通过使用Inception模块来构建深度网络,以提高模型的性能和计算效率。下面是GoogLeNet网络架构的详细描述:
- 输入 原始输入图像为224x224x3,且都进行了零均值化的预处理操作(图像每个像素减去均值)。
- 第一层(卷积层) 使用7x7的卷积核(滑动步长2,padding为3),64通道,输出为112x112x64,卷积后进行ReLU操作 经过3x3的max pooling(步长为2),输出为((112 - 3+1)/2)+1=56,即56x56x64,再进行ReLU操作
- 第二层(卷积层) 使用3x3的卷积核(滑动步长为1,padding为1),192通道,输出为56x56x192,卷积后进行ReLU操作 经过3x3的max pooling(步长为2),输出为((56 - 3+1)/2)+1=28,即28x28x192,再进行ReLU操作
- 第三层(Inception 3a层)
分为四个分支,采用不同尺度的卷积核来进行处理
- 64个1x1的卷积核,然后RuLU,输出28x28x64
- 96个1x1的卷积核,作为3x3卷积核之前的降维,变成28x28x96,然后进行ReLU计算,再进行128个3x3的卷积(padding为1),输出28x28x128
- 16个1x1的卷积核,作为5x5卷积核之前的降维,变成28x28x16,进行ReLU计算后,再进行32个5x5的卷积(padding为2),输出28x28x32
- pool层,使用3x3的核(padding为1),输出28x28x192,然后进行32个1x1的卷积,输出28x28x32。 将四个结果进行连接,对这四部分输出结果的第三维并联,即64+128+32+32=256,最终输出28x28x256
- 第三层(Inception 3b层)
- 128个1x1的卷积核,然后RuLU,输出28x28x128
- 128个1x1的卷积核,作为3x3卷积核之前的降维,变成28x28x128,进行ReLU,再进行192个3x3的卷积(padding为1),输出28x28x192
- 32个1x1的卷积核,作为5x5卷积核之前的降维,变成28x28x32,进行ReLU计算后,再进行96个5x5的卷积(padding为2),输出28x28x96
- pool层,使用3x3的核(padding为1),输出28x28x256,然后进行64个1x1的卷积,输出28x28x64。 将四个结果进行连接,对这四部分输出结果的第三维并联,即128+192+96+64=480,最终输出输出为28x28x480
- 第四层(4a,4b,4c,4d,4e)、第五层(5a,5b)……,与3a、3b类似,在此就不再重复。
超参数设置
| 超参数 | 意义 | 数值 |
|---|---|---|
| init_weights | 用什么方式初始化权重 | 用Kaiming初始化方法初始化卷积层的权重,并使用正态分布初始化全连接层的权重 |
| batch_size | 每个训练批次中的样本数量 | 32 |
| optimizer | 用于模型参数优化的算法 | Adam优化器 |
| lr (learning rate) | 学习率,控制着在每次迭代中更新模型权重的大小 | 0.0003 |
| epochs | 训练模型的轮数,即整个数据集被遍历的次数。 | 100 |
| loss_function | 计算模型预测和真实标签之间差异的函数 | 交叉熵损失(CrossEntropyLoss) |
结果
1
2
3
4
5
6
7
8
9
10
11
12
train epoch[87/100] loss:1.278: 100%|██████████| 157/157 [00:42<00:00, 3.73it/s]
100%|██████████| 16/16 [00:24<00:00, 1.53s/it]
[epoch 87] train_loss: 0.892 val_accuracy: 0.704
Class Precision Recall F1-score Macro-F1
-------------------------------------------------------------------------------------------------------------------------------
Class 0: 0.859375 0.55 0.6707317073170732
Class 1: 0.744 0.93 0.8266666666666667
Class 2: 0.5555555555555556 0.75 0.6382978723404256
Class 3: 0.6120689655172413 0.71 0.6574074074074073
Class 4: 0.9666666666666667 0.58 0.725
0.7036207307463147
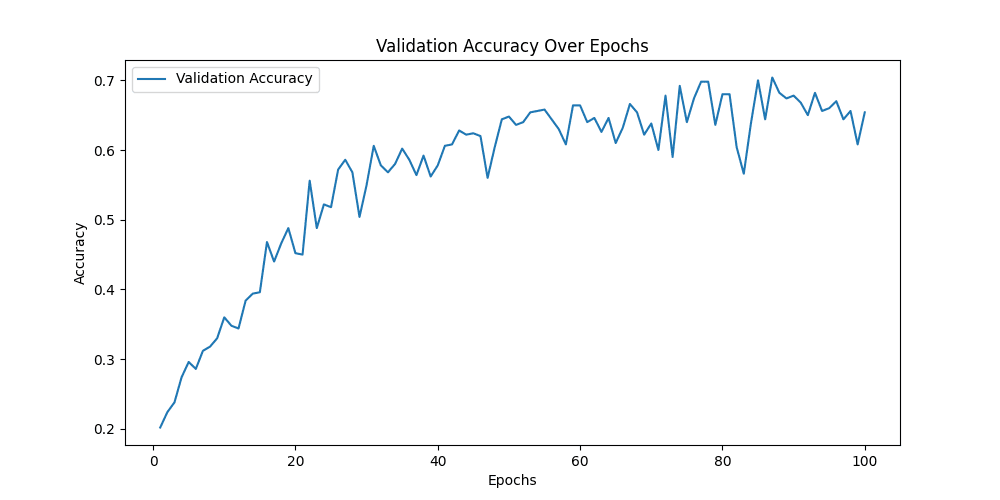
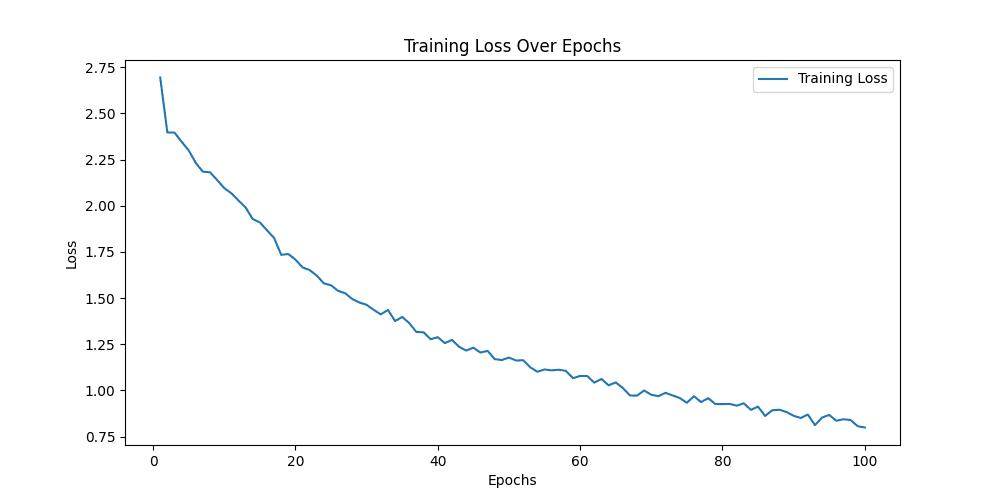
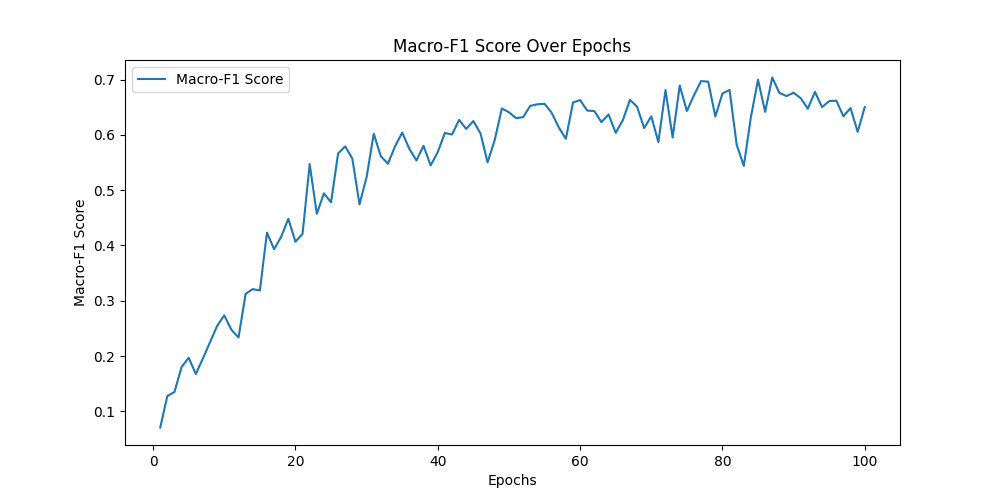
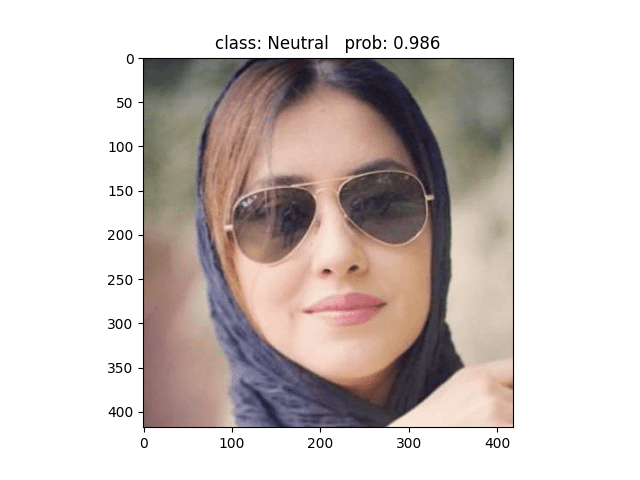
用Googlenet模型做预测,同样的图片可以精确的预测为Neutral,与标签一致,说明Googlenet捕捉到了Alexnet无法捕捉到的细节 ✔
预测错误 ❌
预测错误 ❌ 但是我认为这张照片是可以预测为Neutral的
结果分析
| AlexNet | ResNet | VGG11 | GoogleNet |
|---|---|---|---|
| F1 Scores 排名 | F1 Scores 排名 | F1 Scores 排名 | F1 Scores 排名 |
| Surprise(500)-4 | Happy(1500)-1 | Happy(1500)-1 | Happy(1500)-1 |
| Angry(500)-0 | Surprise(500)-4 | Surprise(500)-4 | Surprise(500)-4 |
| Happy(1500)-1 | Angry(500)-0 | Angry(500)-0 | Angry(500)-0 |
| Neutral(1000)-2 | Sad(1500)-3 | Sad(1500)-3 | Sad(1500)-3 |
| Sad(1500)-3 | More ActionsNeutral(1000)-2 | Neutral(1000)-2 | Neutral(1000)-2 |
| 模型 | ACC | Macro-F1 | 权重大小 | 训练时间(per epoch) | 卷积层数(粗略计算) |
|---|---|---|---|---|---|
| AlexNet | 0.704 | 0.707 | 222MB | 30 | 5 |
| ResNet | 0.784 | 0.712 | 81.3MB | 58 | 28 |
| VGG11 | 0.708 | 0.709 | 491MB | 40 | 8 |
| GoogleNet | 0.704 | 0.704 | 39.4MB | 35 | 17 |
- 模型性能比较:
- 从提供的F1分数排名来看,Happy表情的识别准确率是最高的,而Surprise表情的识别准确率最低。这可能与数据集中Happy表情的样本数量最多有关,而Surprise表情的样本数量最少。
- 在四种模型中,ResNet34模型在Macro-F1分数上表现最佳,这表明它在所有类别上的平均性能最好。
- 模型大小与性能:
- AlexNet模型的大小是第二大的,几乎是GoogleNet的5.5倍,而VGG11模型的大小又是AlexNet的2.5倍,ResNet34在性能最好的同时模型大小也不大,是第二小的。这表明在内存或计算资源有限的情况下,选择更小的模型(如GoogleNet)可能更合适。
- 尽管GoogleNet模型大小较小,但其性能却非常优越,这可能与它的架构设计有关,能够更有效地捕捉图像特征。
- 网络深度的重要性:
- 增加网络的深度可以提高网络的性能。一个深层网络即使在参数数量相同的情况下,性能也至少能与浅层网络相匹配。这是因为深层网络可以通过其额外的层学习到更复杂的特征表示。
- 一个具体的例子是VGG网络,它通过增加网络深度在AlexNet的基础上显著提高了性能。而ResNet则很好的诠释了这一点:越深能提取到特征越多(但也不是越深越好,要和数据量匹配)
通过上述分析,可以得出结论,ResNet34在本次实验中表现最佳,而GoogleNet由于其较小的模型大小和优越的性能,也是一个不错的选择。同时,增加网络的深度对于提高性能是有益的,但也需要考虑到计算资源和训练时间的限制。
实验心得
本次实验花费了整整5天的时间搭建了4个模型(alexnet、resnet、vgg11、googlenet),完成了人脸识别的内容,总的来讲难度属于中等,参考论文即可把网络模型大概搭建出来,
本次实验是一个关于人脸识别技术的研究项目,我投入了整整5天的时间来搭建和测试4个不同经典的深度学习模型,分别是AlexNet、ResNet、VGG11和GoogleNet。
首先,我选择了AlexNet作为起始点,因为它是最早在大规模图像识别任务中取得突破性进展的模型之一。尽管它在今天看来结构相对简单,我按照原始论文的指导搭建了AlexNet模型,并对其进行了适当的调整以适应人脸识别任务。发现模型效果并不好之后,我转向了ResNet模型。ResNet通过引入残差学习解决了深度网络训练中的退化问题,允许我们构建更深的网络结构而不会降低训练效果。训练之后发现模型效果很好,但是这也引发我探究是不是模型越深对本次实验效果越好,所以我接着搭建了没有那么多卷积层数的VGG11模型。VGG11是VGG系列中较浅的网络,效果仍然比Alexnet要好,但是缺点是模型太大了,几乎是Alexnet的2.5倍,有点像是力大砖飞了,所以我又尝试了参数量远小于VGG的GoogleNet模型。GoogleNet以其高效的计算性能和创新的Inception模块而著称,这些模块能够捕捉不同尺度的特征,对于人脸识别这类需要多尺度信息的任务来说,是一个不错的选择,最终效果也显示它以一个较小的模型和比较少的卷积层数实现了比较不错的效果。
在整个实验过程中,我不仅参考了这些模型的原始论文,还查阅了大量的相关文献和资料,实验结果显示,虽然这些模型在理论上都具备处理人脸识别任务的能力,但实际表现各有千秋,这可能与我们的数据集特性、模型超参数设置以及训练过程中的随机性有关。总的来讲,本次实验的难度属于中等。然而,要达到最优的性能,还需要对模型进行细致的调整和优化,这就需要更多的实验和尝试,由于算力的局限,我没有对每一个超参数都进行细致的调整,只是对主要的超参数进行了调节,在准确率超过70%之后就没要再花时间进行进一步调整了。