单层神经网络文本情感分类&朴素贝叶斯文本情感分类
一、 实验题目
在给定文本数据集完成文本情感分类训练,在测试集完成测试,计算准确率。
要求
- 文本的特征可以使用TF或TF-IDF (可以使用sklearn库提取特征)
- 设计合适的网络结构,选择合适的损失函数利用训练集完成网络训练,并在测试集上计算准确率
- 需提交实验报告+代码
- 实验报告应包含损失的可视化展示,以及学习率对准确率影响的可视化展示
经过理论课的复习后,在本次实验要求的基础上,尝试使用朴素贝叶斯方法进行分类。
二、 实验内容
1.算法原理
我的算法采用单层感知机模型来完成文本情感分类的训练。具体的原理如下:
1.数据预处理:将训练集和测试集中的文本数据转换为特征矩阵,使用TF-IDF向量化器将文本转换为特征矩阵。
2.初始化权重:在感知机模型中,权重矩阵W是需要初始化的,这里采用随机化进行权值初始化。
3.前向传播:输入样本特征矩阵X和权重矩阵W,计算输出矩阵Y = XW。
4.计算损失函数:
- 使用MSE(均方误差)损失函数评估训练误差,其计算公式为:
其中N为训练集大小。目的是要让预测值Y尽可能地接近真实值Y_true,从而最小化训练误差。
- 使用交叉熵损失函数评估训练误差,其计算公式为:
其中,$n$ 表示训练集数据的样本数目,$c$ 表示模型的输出类别数。$\delta$ 是一个极小的正数,以防止Y中存在0而导致的对数计算错误。$\odot$ 表示逐元素相乘。
5.梯度下降法更新权重矩阵:通过反向传播计算损失函数的梯度,更新权重矩阵W,使得损失函数L_MSE不断减小,从而提升模型的准确性。梯度下降法的更新公式为 \(W = W - lr * \frac{\partial L_{MSE}}{\partial W}\)
其中,$W$ 表示权重矩阵,$lr$ 表示学习率,$\frac{\partial L_{MSE}}{\partial W}$ 表示均方误差损失函数关于 $W$ 的梯度。这个公式表示权重 $W$ 按照梯度下降的方向进行更新。
6.训练模型:在每个迭代周期中,重复执行前向传播、计算损失函数、梯度下降法更新权重矩阵这三个步骤。不断地训练和优化模型,直到达到预设的迭代次数或者训练误差达到一定的收敛值。
-
评价模型准确率:使用测试集对训练好的模型进行验证,并计算模型的准确率,评估模型的性能。
-
可视化训练过程:将训练过程的损失函数和准确率用图表的形式显示出来,以便于观察模型训练的效果和优化过程。
在完成上述模型后,我觉得单层感知机的神经网络太简单了,所以我决定加入正则化来提高准确率。
L2正则化:向损失函数添加一个关于权重的L2范数惩罚项,使得模型中的所有权重都趋向于较小的值,从而避免了权重过大或过小的情况,有助于防止过拟合。L2正则化即为“岭回归”,其正则化项为权重向量的平方和,加在损失函数中。
- 添加正则化项:为了防止过拟合,损失函数还可以添加正则化项,其目的是强制权重W的值较小,从而限制模型的复杂度,提高泛化能力。因此,在计算损失函数梯度时,需要添加正则化项的偏导数,其更新公式为
\(W = W - lr * (\frac{\partial L_{MSE}}{\partial W} + \lambda * W)\) 其中,$W$ 表示权重矩阵,$lr$ 表示学习率,$\frac{\partial L_{MSE}}{\partial W}$ 表示均方误差损失函数关于 $W$ 的梯度,$\lambda$ 表示正则化参数。这个公式表示对权重进行带有 L2 正则化的梯度下降更新。
2.伪代码
1.假定网络为单层感知机,且没有激活层,没有偏置,此时,网络输出为Y=XW
2.设置损失函数为L_MSE,并随机初始化网络参数W
3.当满足终止条件时,终止优化,否则继续
4.计算网络输出Y=XW,以及损失LMSE=1/N(XW−Y)T(XW−Y)
5.求导可得∂LMSE/∂W = 1/N XT(XW−Y)
6.根据W = W − η ∂LMSE/∂W 更新参数W
7.跳转到3
3.关键代码展示(带注释)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
def ANN():
iterations = []
accur_train = []
accur_test = []
losses = []
#将训练集、测试集和情感标签转换为NumPy数组
# 转换成numpy数组
mydata = data()
aligned_train_set = np.array(mydata.aligned_train_set)
aligned_test_set = np.array(mydata.aligned_test_set)
emotion_train = np.array(mydata.emotion_train)
emotion_test = np.array(mydata.emotion_test)
# 数值为1~6的情感标签转化成二进制
emotion_train_b = LabelBinarizer().fit_transform(emotion_train)
# 数据集参数
feature_size = len(aligned_train_set[0]) #表示每个样本的特征维度(每个样本的特征数量)在本次中有多少词既有多少特征
#开始训练模型
perceptron = Perceptron(feature_size, num_classes)#输入大小为feature_size,输出大小为num_classes
print('learning rate is ',learning_rate)
for iteration in range(iterations_num):
#计算输出Y = 𝑋𝑊
Y = perceptron.forward(aligned_train_set)
Y_test = perceptron.forward(aligned_test_set)
#计算损失MS𝐸 = 1/𝑁(𝑋𝑊 − 𝑌)^2
# L_MSE, d_L_MSE = MSE(aligned_train_set, Y, emotion_train_b) #iterations_num=3500 学习率0.7
L_MSE, d_L_MSE = MSE_with_regularization(aligned_train_set, Y, emotion_train_b, perceptron.weights) #加入正则化
# L_MSE, d_L_MSE = cross_entropy_error(aligned_train_set, Y, emotion_train_b)
# #更新权重 𝑊 = 𝑊 − 𝜂 * 𝜕𝑀𝑆𝐸/𝜕W
# perceptron.weights = perceptron.weights - learning_rate * d_L_MSE
#更新正则化的权重 W = W - lr(dL_MSE/dW + lambda*W)
perceptron.weights = perceptron.weights - learning_rate * (d_L_MSE + lamda * perceptron.weights)
#为了画图取样
if iteration % sample_rate == 0:
#训练集
pre_label = []
for i in range(Y.shape[0]):#Y(train_size, num_class)的矩阵,所以Y.shape[0]即为train_size
pre_label.append(np.argmax(Y[i]) + 1)#np.argmax()返回最大数的索引
cur_accuracy = np.mean(np.equal(pre_label, emotion_train)) #即预测值与训练集情感标签相匹配的比例
print('Train_Set: iteration [{}/{}], Loss: {:.4f}, Accuracy: {}'.format(iteration + 1, iterations_num, L_MSE,100 * cur_accuracy))
accur_train.append(100 * cur_accuracy)
#测试集
pre_label = []
for i in range(Y_test.shape[0]):
pre_label.append(np.argmax(Y_test[i]) + 1)
cur_accuracy = np.mean(np.equal(pre_label, emotion_test))
print('Test_Set: iteration [{}/{}], Loss: {:.4f}, Accuracy: {}'.format(iteration + 1, iterations_num, L_MSE,100 * cur_accuracy))
accur_test.append(100 * cur_accuracy)
iterations.append(iteration)
losses.append(L_MSE)
# 创建一个 1x2 的子图,用于显示训练集和测试集准确率以及损失值
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 6))
# 设置第一个子图的 x 轴和 y 轴标签及标题,并画出训练集和测试集准确率的折线图
ax1.set_xlabel('iterations')
ax1.set_ylabel('accuracy')
ax1.set_title('Train/Test Set Accuracy')
ax1.plot(iterations, accur_train, color = 'red')
ax1.plot(iterations, accur_test, color='green')
ax1.legend(['Train', 'test'])
# 设置第二个子图的 x 轴和 y 轴标签及标题,并画出损失值的折线图
ax2.set_xlabel('iterations')
ax2.set_ylabel('losses')
ax2.set_title('Losses')
ax2.plot(range(len(losses)), losses, color='blue')
# 在最后一行展示所有图形
plt.show()
4.创新点&优化(如果有)
加入正则化加快训练速度且防止过拟合。正则化项的系数λ需要根据实验进行调整。通常来说,较小的λ会使得正则化项对损失函数的影响较小,而较大的λ会使得正则化项对损失函数的影响更加明显。需要注意的是,正则化系数过大也会导致欠拟合问题,因此需要找到一个适当的λ值,从而取得最好的效果。
三、 实验结果及分析
1.实验结果展示示例(可图可表可文字,尽量可视化)
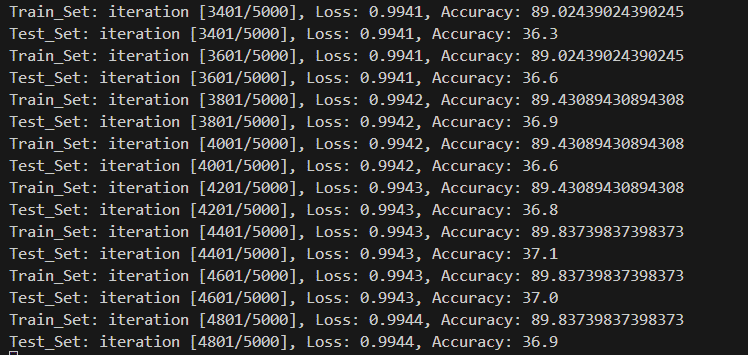
图中iterations都是每隔200次采样1次后做的图
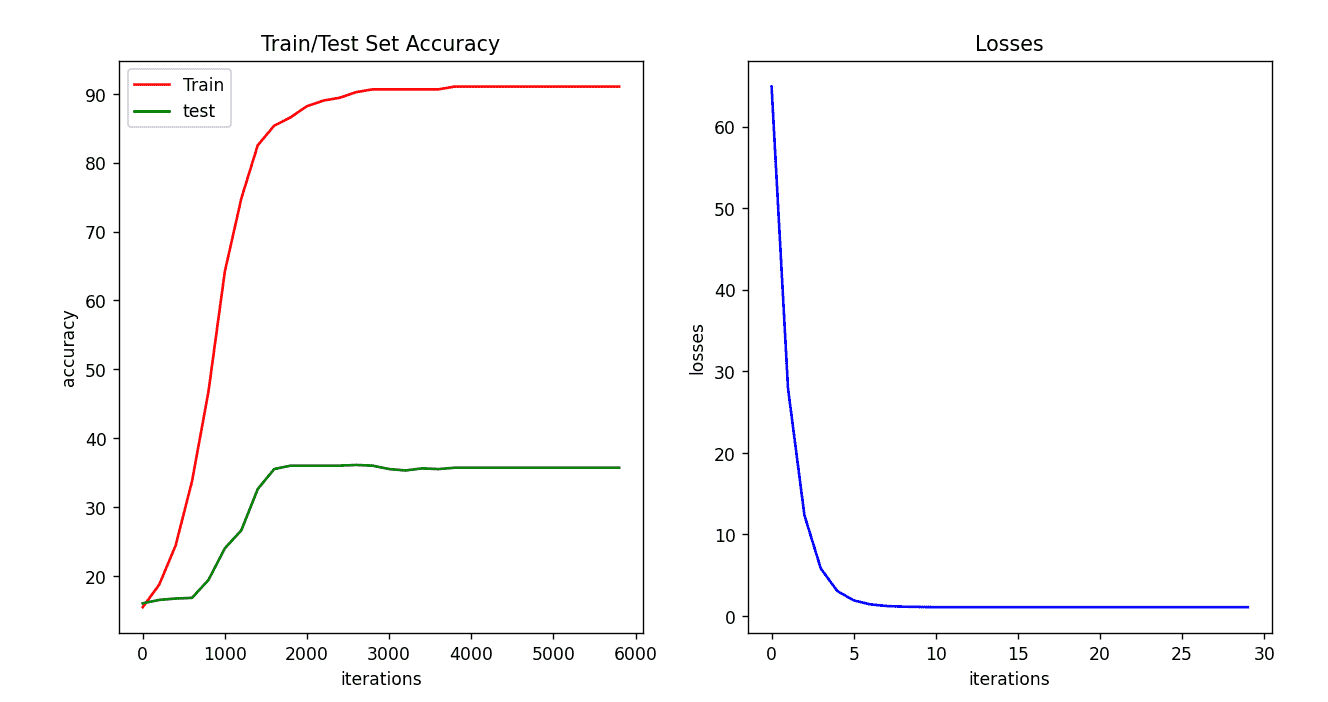
损失函数选正则化后的均方误差,激活函数选softmax,迭代次数为5000次时,学习率对精度影响(具体分析见实验报告的下一节):
2.评测指标展示及分析(机器学习实验必须有此项,其它可分析运行时间等)
考虑学习率learn_rate、迭代次数iterations_num、激活函数、损失函数对准确率的影响。
| 序号 | 激活函数 | 损失函数 | 学习率 | 迭代次数 | accuracy_train | accuracy_test |
|---|---|---|---|---|---|---|
| 1 | sigmoid | 交叉熵 | 0.4 | 8000 | 97.6% | 30.6% |
| 2 | sigmoid | 交叉熵 | 0.4 | 8000 | 97.5% | 32.1% |
| 3 | sigmoid | 交叉熵 | 0.4 | 8000 | 97.6% | 29.2% |
| 平均 | / | / | / | / | 97.56% | 30.63% |
| 序号 | 激活函数 | 损失函数 | 学习率 | 迭代次数 | accuracy_train | accuracy_test |
|---|---|---|---|---|---|---|
| 1 | sigmoid | 均方误差 | 0.4 | 8000 | 97.5% | 31.7% |
| 2 | sigmoid | 均方误差 | 0.4 | 8000 | 97.6% | 30.0% |
| 3 | sigmoid | 均方误差 | 0.4 | 8000 | 97.5% | 31.0% |
| 平均 | / | / | / | / | 97.56% | 30.9% |
| 序号 | 激活函数 | 损失函数 | 学习率 | 迭代次数 | accuracy_train | accuracy_test |
|---|---|---|---|---|---|---|
| 1 | softmax | 交叉熵 | 0.4 | 8000 | 88.2% | 36.1% |
| 2 | softmax | 交叉熵 | 0.4 | 8000 | 87.3% | 36.3% |
| 3 | softmax | 交叉熵 | 0.4 | 8000 | 89.8% | 36.4% |
| 平均 | / | / | / | / | 88.4% | 36.26% |
| 序号 | 激活函数 | 损失函数 | 学习率 | 迭代次数 | accuracy_train | accuracy_test |
|---|---|---|---|---|---|---|
| 1 | softmax | 均方误差 | 0.4 | 8000 | 88.6% | 37.1% |
| 2 | softmax | 均方误差 | 0.4 | 8000 | 88% | 37.8% |
| 3 | softmax | 均方误差 | 0.4 | 8000 | 88.2% | 36.5% |
| 平均 | / | / | / | / | 88.2% | 37.13% |
可以看到softmax激活函数适合更适合这一个多分类问题,sigmoid激活函数建立一个多标签分类模型时,其中每个相互包含的类都有两个结果,对本次实验的问题不太好。
看了以上数据可以发现,由于我们划分的训练集太小了,所以很容易就会过拟合。为了解决这一点,有两个解决方案:
- 在均方误差中加入正则化的思想。
- 提高学习率减少迭代次数。
加入正则化:
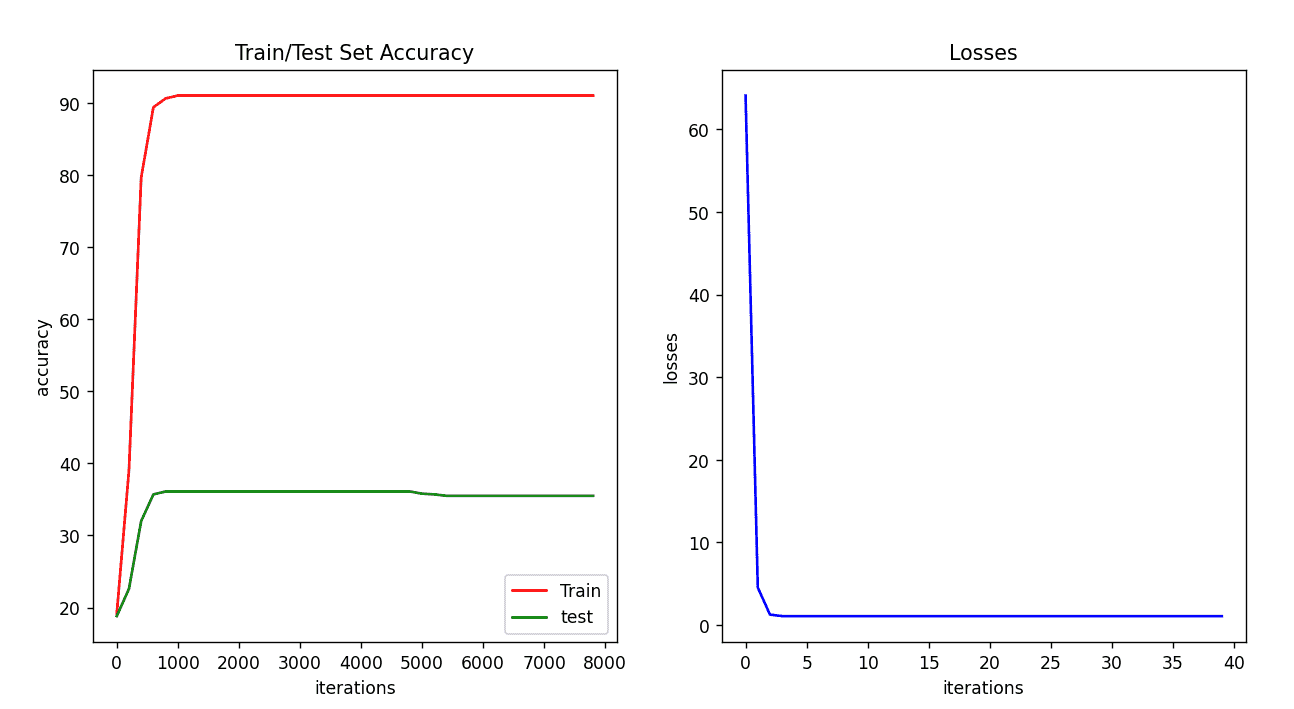
| 序号 | 激活函数 | 损失函数 | 学习率 | 迭代次数 | accuracy_train | accuracy_test |
|---|---|---|---|---|---|---|
| 1 | softmax | 均方误差(正则化) | 0.4 | 8000 | 90.6% | 36.1% |
| 2 | softmax | 均方误差(正则化) | 0.4 | 8000 | 91.6% | 36.1% |
| 3 | softmax | 均方误差(正则化) | 0.4 | 8000 | 91.05% | 35.5% |
| 平均 | / | / | / | / | 91.08% | 35.9% |
发现虽然没有显著提高精度,但是显著提高了收敛速度,迭代次数在1500次左右就已经收敛了
提高学习率减少迭代次数:
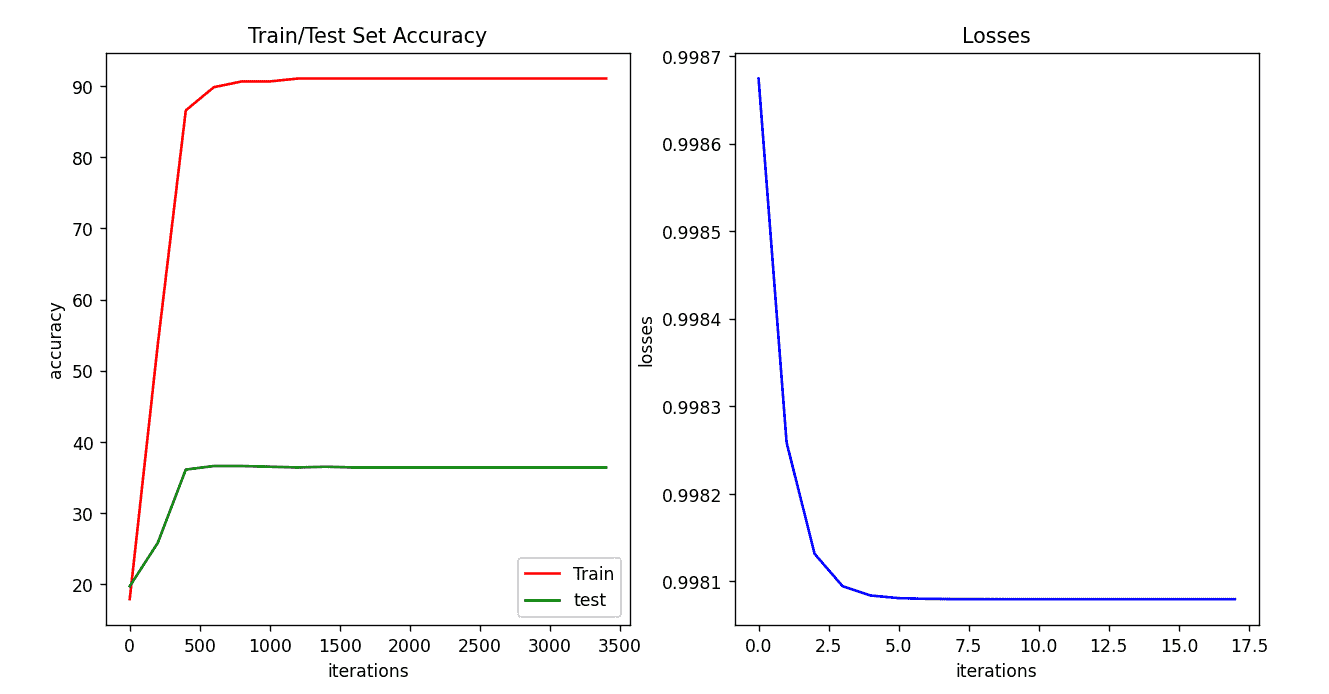
| 序号 | 激活函数 | 损失函数 | 学习率 | 迭代次数 | accuracy_train | accuracy_test |
|---|---|---|---|---|---|---|
| 1 | softmax | 均方误差 | 0.7 | 3500 | 91.05% | 36.4% |
| 2 | softmax | 均方误差 | 0.7 | 3500 | 91.05% | 36.3% |
| 3 | softmax | 均方误差 | 0.7 | 3500 | 91.05% | 36.4% |
| 平均 | / | / | / | / | 91.05% | 36.36% |
以下激活函数都选用softmax,损失函数选用均方误差。
对于迭代次数iterations_num = 7000,学习率对精度影响如下:
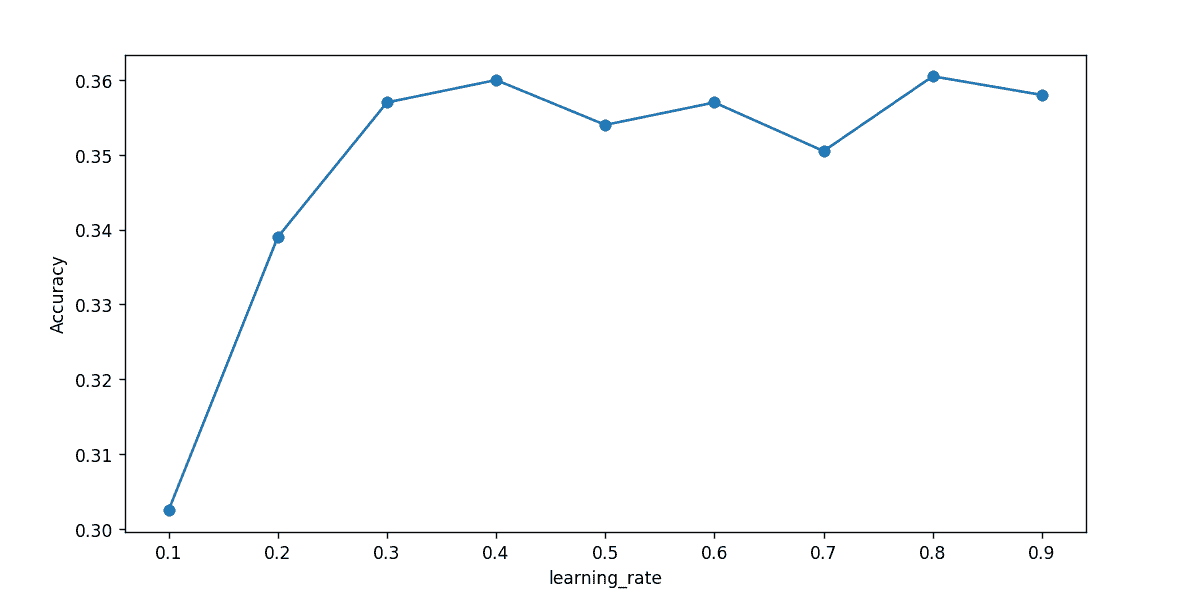
对于学习率learn_rate=0.4,迭代次数对精度影响如下:
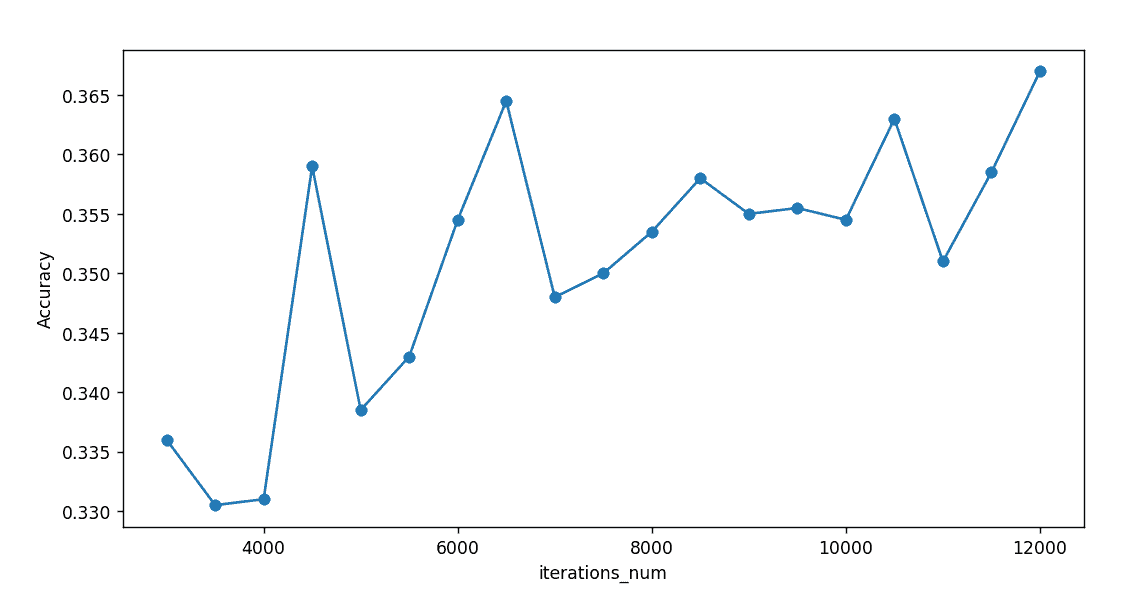
可以看到迭代次数在8000次后就接近收敛了
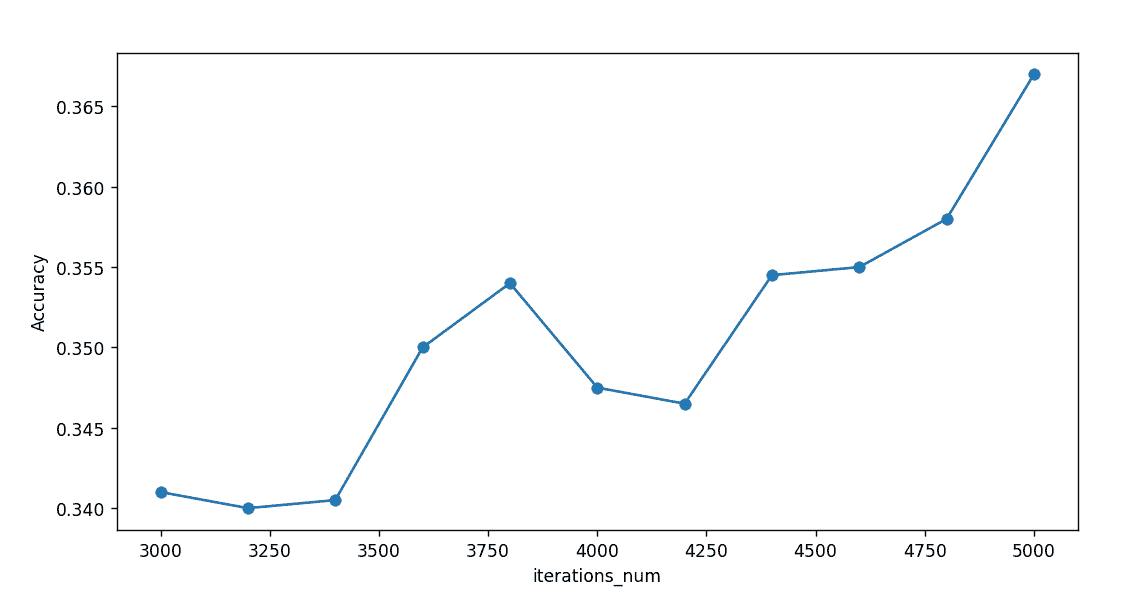
对于学习率learn_rate=0.7,迭代次数对精度影响如下:
四、 自己想做的实验
因为本次的数据量太小了,所以导致训练集只有200多条,测试集只有1200多条,如果我把两者换过来,给多一点训练集,对分类的精度会不会高一点呢?
调换后:
| 序号 | 激活函数 | 损失函数 | 学习率 | 迭代次数 | accuracy_train | accuracy_test |
|---|---|---|---|---|---|---|
| 1 | softmax | 均方误差 | 0.7 | 3500 | 57.3% | 42% |
五、 参考资料
扩展实验一 使用朴素贝叶斯分类器进行分类
一、实验内容
(1)算法原理
朴素贝叶斯分类器是一种基于概率论的分类算法,它的原理是利用贝叶斯定理(Bayes’ theorem)进行分类。具体来讲,朴素贝叶斯分类器假设所有特征之间相互独立,然后根据每个特征出现的概率以及各个类别出现的先验概率,计算某个文档属于各个类别的后验概率,最终将该文档归为后验概率最大的那个类别。
朴素贝叶斯分类器的算法可以分为以下几个步骤:
- 收集训练数据:首先需要收集带有标签的样本数据,这些数据可以用来训练分类器。
- 特征提取:将训练数据中的文本转化为特征向量,常用的方法有词袋模型和TF-IDF方法。
- 计算先验概率:对于每一个类别,需要计算其在训练数据中出现的概率,即先验概率。
- 计算条件概率:对于每一个特征值,需要计算在给定类别下该特征值出现的概率,即条件概率。由于朴素贝叶斯分类器假设特征之间相互独立,因此可以将每个特征的条件概率乘起来,得到文档属于某个类别的后验概率。
- 根据后验概率进行分类:最终将文档归为后验概率最大的那个类别。
(2)伪代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 计算每个类别的先验概率
for c in classes:
prior[c] = count(samples with class c) / total samples
# 计算每个特征在每个类别下的条件概率
for c in classes:
for f in features:
conditional_prob[c][f] = (count(samples with feature f and class c) + 1)
/ (count(samples with class c) + 2)
# 对于新样本x,计算其属于每个类别的后验概率
for c in classes:
posterior[c] = log(prior[c])
for f in features:
if x has feature f:
posterior[c] += log(conditional_prob[c][f])
else:
posterior[c] += log(1 - conditional_prob[c][f])
# 预测新样本所属类别
predicted_class = argmax(posterior)
(3)关键代码展示(带注释)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 给定训练数据train_data,词汇表vocabulary
# 返回条件概率p(word|label)
def train(self, train_data, vocabulary):
# 计算每个特征在每个类别下的条件概率
total_counts = {}
for label in train_data.keys():
total_counts[label] = sum(train_data[label].values())
probabilities = {}
# 这里要进行拉普拉斯平滑
k = 4
for label in train_data.keys():
probabilities[label] = {}
for word in vocabulary:
if word in train_data[label].keys():
count = train_data[label][word]
else:
count = 0
probabilities[label][word] = (count + k) / (total_counts[label] + k * len(vocabulary))
return probabilities
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 给定测试数据,给回预测结果
def predict(self, test_data, probabilities, freq):
labels = list(probabilities.keys())
results = []
label_sum = sum(freq.values())
# 对每个句子进行预测
for words in test_data:
scores = {}
# 对每个label进行打分
for label in labels:
score = freq[label] / label_sum
for word in words:
if word in probabilities[label].keys():
score *= probabilities[label][word]
scores[label] = score
# 预测结果为最大分数的标签
result = max(scores, key=scores.get)
results.append(result)
return results
二、实验结果展示以及性能分析
这里尝试了几种方法来对文本进行分类,主要是下面几种方法
- 完全是自己实现的提取文本特征的函数(这里实现的是TF方法)、训练函数和预测函数
- 用 sklearn 库来提取文本特征,然后手动实现训练函数和预测函数
- 完全用 sklearn 库来实现所有的功能,包括提取文本特征、训练函数和预测函数下面会展示这几种方法的结果进行对比
完全是自己实现的提取文本特征的函数、训练函数和预测函数
- 这里进行拉普拉斯平滑中有一个超参数 ,下面将展示对 取不同值的结果
| k | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 正确率 | 0.384 | 0.385 | 0.387 | 0.385 | 0.383 |

用 sklearn 库来提取文本特征,然后手动实现训练函数和预测函数
- 提取特征方法用TF
1
self.vectorizer = TfidfVectorizer(use_idf=False)

- 提取特征方法用TF-IDF
1
self.vectorizer = TfidfVectorizer(use_idf=True)
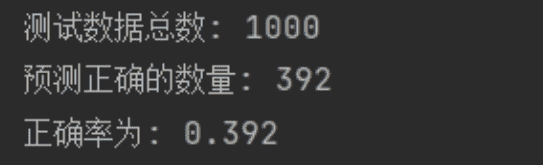
完全用 sklearn 库来实现所有的功能,包括提取文本特征、训练函数和预测函数
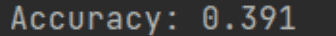
总结:
- 由实验结果可以知道,如果完全用 sklearn 库来实现所有的功能的话,准确率可以达到0.391,这个主要是为了给其它方法一个对比参照(毕竟这是别人已经写好的库,表现应该不会差)
- 如果是自己完全手写的话,我这里是采用了TF进行文本特征的提取,即只是考虑到了单词出现的频率,没有考虑到单词出现在各个类别里的情况以及单词出现的顺序等关系,所以性能比上面的0.391稍微差一点,最后经过调参发现最好能达到0.387
- 而如果是采用 sklearn 库来提取文本特征,而手动实现训练函数和预测函数的话,可以在采取IF的时候拥有0.397的准确率,在采取IF-IDF的时候拥有0.392的准确率
提取特征方法(IF和IF-IDF)选取的优缺点
TF(TermFrequency):词频统计方法,每个文档中各个单词出现的次数就是这些单词的TF值。
TF-IDF(TermFrequency-InverseDocumentFrequency)在TF的基础上,加入了逆文档频率因子,用于衡量某个词语对于整个语料库的区分能力
相比而言,TF-IDF更为常用且表现更好。原因在于:
- TF仅考虑单词在当前文档中出现的频率,没有考虑到该单词在其他文档中的频率以及该单词是否为停用词等。而TF-IDF通过乘以一个逆文档频率因子来弥补这一不足,可以更好地反映单词在整个语料库中的重要程度。
- 对于同一个单词,在不同的文本中可能扮演着不同的角色,如“apple”在购物网站上指代水果,而在科技网站上则指代苹果公司的产品。TF-IDF采用了全局信息,对于不同文档中出现的同一个词,可以根据它在整个语料库中的出现情况,赋予不同的权重,从而更准确地反映其含义。
但是在本次的实验中发现,采用 sklearn 库来提取文本特征,使用TF方法得到的准确率较高,经过分析,可能是因为下面的几个原因。
- 样本数量较少:如果你的样本数量比较小,那么文档频率(IDF)很有可能无法准确地反映单词的重要性,此时采用简单的TF方法可能会更为合适。
- 语料库不够规范:如果语料库中存在大量噪声、误差或不规范的文本,使用TF-IDF可能会将这些错误信息纳入考虑范围,影响模型效果。在这种情况下,简单的TF方法可能会更加鲁棒。
- 应用场景偏向于短文本:在一些短文本的场景下,由于文本长度较短,IDF值可能会受到限制,使得TF-IDF方法的效果变差。而TF方法则可以更好地反映出短文本中单词出现的重要性。