内存管理策略
To provide a detailed description of various ways of organizing memory hardware
To discuss various memory-management techniques, including paging and segmentation
To provide a detailed description of the Intel Pentium, which supports both pure segmentation and segmentation with paging
提供组织内存硬件的各种方法的详细说明
讨论各种内存管理技术,包括分页和分段
提供英特尔奔腾的详细说明,它支持纯分段和分页分段
1. 背景 Background
-
Program must be brought (from disk) into memory and placed within a process for it to be run
-
Main memory and registers are only storage CPU can access directly
- Memory unit only sees a stream of addresses + read requests, or address + data and write requests
- Register access in one CPU clock (or less)
- Main memory can take many cycles, causing a stall
-
Cache sits between main memory and CPU registers Protection of memory required to ensure correct operation
- 程序必须(从磁盘)导入内存并放置在进程中才能运行
- CPU可以直接访问的存储只有主存储器和寄存器
- 内存单元只能看到地址流 + 读取请求,或地址 + 数据和写入请求
- 在一个 CPU 时钟(或更少)中注册访问
- 主内存的访问可能需要多个周期,从而导致CPU停滞(stall)
- 缓存位于主存储器和 CPU 寄存器之间 确保正确操作所需的内存保护
1.1 基本硬件
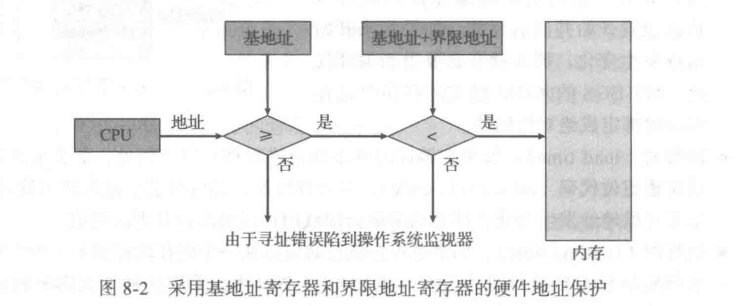
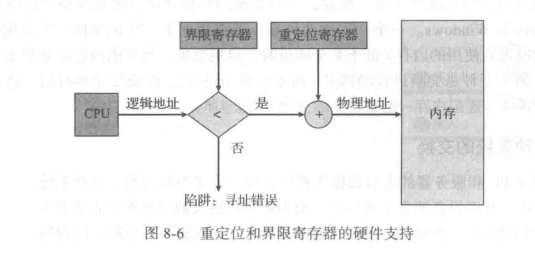
Base and Limit Registers :A pair of base and limit registers define the logical address space CPU must check every memory access generated in user mode to be sure it is between base and limit for that user
基址寄存器和界限地址寄存器:一对基址寄存器和界限地址寄存器定义逻辑地址空间 CPU 必须检查在用户模式下生成的每个内存访问,以确保该用户在基址和界限地址之间

-
基地址寄存器(base register)含有最小的合法的物理内存地址,
-
界限地址寄存器(limit register)指定了范围的大小。
内存空间保护的实现是通过CPU硬件对在用户模式下产生的地址与寄存器的地址进行比较来完成的。当在用户模式下执行的程序试图访问操作系统内存或其他用户内存时,会陷入操作系统,而操作系统则将它作为致命错误来处理(图 8-2)。这种方案防止用户程序无意或故意修改操作系统或其他用户的代码或数据结构。
只有操作系统可以通过特殊的特权指令,才能加载基地址寄存器和界限地址寄存器。由于特权指令只能在内核模式下执行,而只有操作系统才能在内核模式下执行,所以只有操作系统可以加载基地址寄存器和界限地址寄存器。这种方案允许操作系统修改这两个寄存器的值,而不允许用户程序修改它们。
在内核模式下执行的操作系统可以无限制地访问操作系统及用户的内存。这项规定允许操作系统:
- 加载用户程序到用户内存,
- 转储出现错误的程序,
- 访问和修改系统调用的参数,
- 执行用户内存的I/O,
- 以及提供许多其他服务等。例如,多任务系统的操作系统在进行上下文切换时,应将一个进程的寄存器的状态存到内存,再从内存中调入下个进程的上下文到寄存器
1.2 地址绑定 Address Binding
Programs on disk, ready to be brought into memory to execute form an inputqueue
- Without support, must be loaded into address 0000
Inconvenient to have first user process physical address always at 0000
- How can it not be?
Further, addresses represented in different ways at different stages of aprogram’s life
- Source code addresses usually symbolic
- Compiled code addresses bind to relocatable addresses
- i.e. “14 bytes from beginning of this module”
- Linker or loader will bind relocatable addresses to absolute addresses
- i.e. 74014
- Each binding maps one address space to another
磁盘上的程序,准备进入内存以从输入队列执行
- 如果没有支持,必须加载到地址 0000 中
不方便第一个用户进程物理地址始终为 0000
- 怎么可以不是?
此外,在程序生命的不同阶段以不同的方式表示的地址
- 源代码地址通常为符号
- 编译的代码地址绑定到可重定位的地址
- 即“从本模块开头 14 个字节”
- 链接器或加载器会将可重定位地址绑定到绝对地址
- 即 74014
- 每个绑定将一个地址空间映射到另一个地址空间
通常,程序作为二进制的可执行文件,存放在磁盘上。为了执行,程序应被调入内存并放在进程中。根据采用的内存管理,进程在执行时可以在磁盘和内存之间移动。在磁盘上等待调到内存以便执行的进程形成了输入队列(input queue)。 正常的单任务处理过程是:从输入队列中选取一个进程并加载到内存;进程在执行时会访问内存的指令和数据;最后,进程终止时,它的内存空间将会释放。
在大多数情况下,用户程序在执行前,需要经过好几个步骤,其中有的是可选的(参见图8-3)。在这些步骤中,地址可能会有不同表示形式。源程序中的地址通常是用符号表示(如变量 count)。 **编译器通常将这些符号地址绑定(bind)到可重定位的地址**(如“从本模块开始的第14 字节”)。链接程序或加载程序再将这些可重定位的地址绑定到绝对地址(如74014)。每次绑定都是从一个地址空间到另一个地址空间的映射。
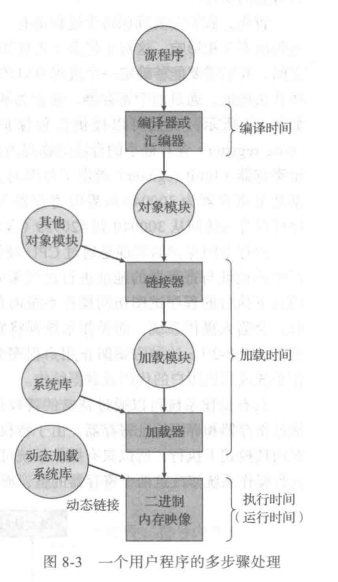
通常,指令和数据绑定到存储器地址可在沿途的任何一步中进行:
- 编译时(compile time):如果在编译时就已知道进程将在内存中的驻留地址,那么就可以生成绝对代码(absolute code)。例如,如果事先就知道用户进程驻留在内存地址R处,那么生成的编译代码就可以从该位置开始并向后延伸。如果将来开始地址发生变化,那么就有必要重新编译代码。MS-DOS的COM格式的程序就是在编译时绑定成绝对代码的。
- 加载时(load time):如果在编译时并不知道进程将驻留在何处,那么编译器就应生成可重定位代码(relocatable code)。对这种情况,最后绑定会延迟到加载时才进行如果开始地址发生变化,那么只需重新加载用户代码以合并更改的值。
- 执行时(runtime time):如果进程在执行时可以从一个内存段移到另一个内存段,那么绑定应延迟到执行时才进行。正如8.1.3 节所述,采用这种方案需要特定硬件才行。大多数的通用计算机操作系统采用这种方法。
本章主要讨论如何在计算机系统中有效实现这些绑定,以及适当的硬件支持
1.3 逻辑地址空间与物理地址空间
The concept of a logical address space that is bound to a separatephysical address space is central to proper memory management
- Logical address – generated by the CPU; also referred to as virtual address
- Physical address – address seen by the memory unit
Logical and physical addresses are the same in compile-time and loadtime address-binding schemes; logical (virtual) and physical addresses differ in execution-time address-binding scheme
Logical address space is the set of all logical addresses generated by a program
Physical address space is the set of all physical addresses generated by a program
绑定到单独物理地址空间的逻辑地址空间的概念对于正确的内存管理至关重要
- 逻辑地址 – 由 CPU 生成;也称为虚拟地址
- 物理地址 – 内存单元看到的地址
逻辑地址和物理地址在编译时和加载时地址绑定方案中是相同的;逻辑(虚拟)地址和物理地址在执行时地址绑定方案中有所不同
逻辑地址空间是程序生成的所有逻辑地址的集合
物理地址空间是程序生成的所有物理地址的集合
Memory-Management Unit (MMU) 内存管理单元:
MMU–Hardware device that at run time maps virtual to physical address
Many methods possible, covered in the rest of this chapter
To start, consider simple scheme where the value in the relocation register is added to every address generated by a user process at the time it is sent to memory
- Base register now called relocation register
- MS-DOS on Intel 80x86 used 4 relocation registers
The user program deals with logical addresses; it never sees the real physical addresses
- Execution-time binding occurs when reference is made to location in memory
- Logical address bound to physical addresses
内存管理单元:
MMU—在运行时将虚拟地址映射到物理地址的硬件设备
许多可能的方法,在本章的其余部分介绍
首先,考虑简单的方案,其中重新定位寄存器中的值在发送到内存时加上到用户进程生成的每个地址
- 基本寄存器现在称为重定位寄存器
- 英特尔 80x86 上的 MS-DOS 使用了 4 个重定位寄存器
用户程序处理逻辑地址;它永远不会看到真实的物理地址
- 引用内存中的位置时发生执行时绑定
- 绑定到物理地址的逻辑地址
基地址寄存器这里称为重定位寄存器(relocation register)。用户进程所生成的地址在送交内存之前,都将加上重定位寄存器的值(如图8-4 所示)。例如,如果基地址为14000,那么用户对位置0的访问将动态地重定位为位置14000;对地址346的访问将映射为位置14346。
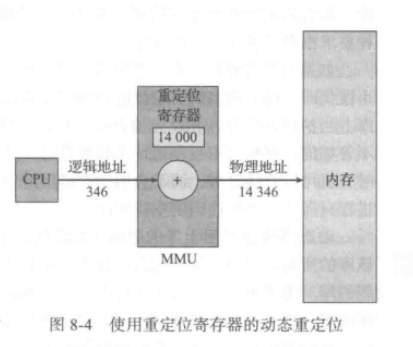
我们现在有两种不同类型的地址:
逻辑地址(范围为0max)和物理地址(范围为R+0~R + max,其中R为基地址的值)。
用户只生成逻辑地址,且以为进程的地址空间为0~max。
然而,这些逻辑地址在使用之前应映射到物理地址。逻辑地址空间绑定到另一单独物理地址空间的这一概念对内存的管理至关重要。
1.4 动态加载 Dynamic relocation using a relocation register
在迄今为止的讨论中,一个进程的整个程序和所有数据都应在物理内存中,以便执行。因此,进程的大小受限于内存的大小。为了获得更好的内存空间利用率,可以使用动态加载(dynamic loading)。采用动态加载时,一个程序只有在调用时才会加载。所有程序都以可重定位加载格式保存在磁盘上。
主程序被加载到内存,并执行。当一个程序需要调用另一个程序时,调用程序首先检查另一个程序是否已加载。如果没有,可重定位链接程序会加载所需的程序到内存,并更新程序的地址表以反映这一变化。接着,控制传递给新加载的程序。
动态加载的优点是,只有一个程序被需要时,它才会被加载。当大多数代码需要用来处理异常情况时,如错误处理,这种方法特别有用。在这种情况下,虽然整个程序可能很大但是所用的 (和加载的)部分可能很小。
动态加载不需要操作系统提供特别支持。用户的责任是,设计他们的程序利用这种方法的优点。然而,操作系统可以通过实现动态加载的程序库来帮助程序员。
1.5 动态链接与共享库
Static linking – system libraries and program code combined by the loader into the binary program image
Dynamic linking –linking postponed until execution time
Small piece of code, stub, used to locate the appropriate memoryresident library routine
Stub replaces itself with the address of the routine, and executes the routine
Operating system checks if routine is in processes’ memory address
- If not in address space, add to address space
Dynamic linking is particularly useful for libraries
System also known as shared libraries
Consider applicability to patching system libraries
- Versioning may be needed
静态链接 – 由加载器将系统库和程序代码组合成二进制程序映像
动态链接 – 链接推迟到执行时间
一小段代码,存根,用于查找适当的内存驻留库例程
存根将自身替换为例程的地址,并执行例程
操作系统检查例程是否在进程的内存地址中
- 如果不在地址空间中,请添加到地址空间
动态链接对库特别有用
系统也称为共享库
考虑修补系统库的适用性
- 可能需要版本控制
动态链接库(dynamically linked library)为系统库,可链接到用户程序,以便运行(参见图8-3)。有的操作系统只支持静态链接(static linking),它的系统库与其他目标模块-样,通过加载程序,被合并到二进制程序映像。 ** **动态链接类似于动态加载。这里,不是加载而是链接,会延迟到运行时。这种功能通常用于系统库,如语言的子程序库。没有这种功能,系统内的所有程序都需要一份语言库的副本(或至少那些被程序所引用的子程序)。这种要求浪费了磁盘空间和内存空间。
如果有动态链接,在二进制映像内,每个库程序的引用都有一个存根(stub)。存根是一小段代码,用来指出如何定位适当的内存驻留库程序,或者在程序不在内存内时应如何加载库。当执行存根时,它首先检查所需程序是否已在内存中。如果不在,就将程序加到内存不管如何,存根会用程序地址来替换自己,并开始执行程序。因此,下次再执行该程序代码时,就可以直接进行,而不会因动态链接产生任何开销。采用这种方案,使用语言库的所有进程只需要一个库代码副本就可以了。
2. 交换 Swapping
A process can be swapped temporarily out of memory to a backingstore, and then brought back into memory for continued execution
- Total physical memory space of processes can exceed physical memory
Backing store – fast disk large enough to accommodate copies of all memory images for all users; must provide direct access to these memory images
Roll out, roll in – swapping variant used for priority-based scheduling algorithms; lower-priority process is swapped out so higher-priority process can be loaded and executed
Major part of swap time is transfer time; total transfer time is directly proportional to the amount of memory swapped
System maintains a ready queue of ready-to-run processes which have memory images on disk
Does the swapped out process need to swap back in to same physical addresses?
Depends on address binding method
- Plus consider pending I/O to / from process memory space
Modified versions of swapping are found on many systems (i.e., UNIX, Linux, and Windows)
- Swapping normally disabled
- Started if more than threshold amount of memory allocated
- Disabled again once memory demand reduced below threshold
进程可以暂时从内存中交换到后备存储,然后返回到内存中继续执行
- 进程的总物理内存空间可以超过物理内存
备份存储——足够大的快速磁盘,可以容纳所有用户的所有内存映像的副本;必须提供对这些内存映像的直接访问
推出,推出 - 用于基于优先级的调度算法的交换变体;优先级较低的进程被换出,以便可以加载和执行优先级较高的进程
交换时间的主要部分是转移时间;总传输时间与交换的内存量成正比
系统维护一个准备运行进程的就绪队列,这些进程在磁盘上有内存映像
换出的进程是否需要换回相同的物理地址?
取决于地址绑定方式
- 再加上考虑挂起的 I/O 进出进程内存空间
在许多系统(即 UNIX、Linux 和 Windows)上都可以找到交换的修改版本
- 交换通常禁用
- 如果分配的内存量超过阈值则启动
- 一旦内存需求降低到阈值以下,再次禁用
2.1 标准交换
If next processes to be put on CPU is not in memory, need to swap out a process and swap in target process
Context switch time can then be very high
100MB process swapping to hard disk with transfer rate of 50MB/sec
- Swap out time of 2000 ms
- Plus swap in of same sized process
- Total context switch swapping component time of 4000ms (4 seconds)
Can reduce if reduce size of memory swapped – by knowing how much memory really being used
- System calls to inform OS of memory use viarequest_memory() and release_memory()
Other constraints as well on swapping
- Pending I/O – can’t swap out as I/O would occur to wrong process
- Or always transfer I/O to kernel space, then to I/O device
- Known as double buffering, adds overhead
Standard swapping not used in modern operating systems
- But modified version common
- Swap only when free memory extremely low
如果要放在 CPU 上的下一个进程不在内存中,则需要换出一个进程并换入目标进程
上下文切换时间可能非常高
100MB 进程交换到硬盘,传输速率为 50MB/秒
- 换出时间为 2000 ms
- 加上相同尺寸的流程的交换
- 上下文切换组件的总时间为 4000 毫秒(4 秒)
如果减小交换的内存大小,可以减少 - 通过了解实际使用的内存量
- 系统调用以通知操作系统内存使用情况 viarequest_memory() 和 release_memory()
交换的其他限制
- 挂起的 I/O – 无法换出,因为 I/O 会发生在错误的进程上
- 或者始终将 I/O 传输到内核空间,然后传输到 I/O 设备
- 称为双缓冲,增加开销
现代操作系统中不使用标准交换
- 但修改版常见
- 仅在可用内存极低时交换
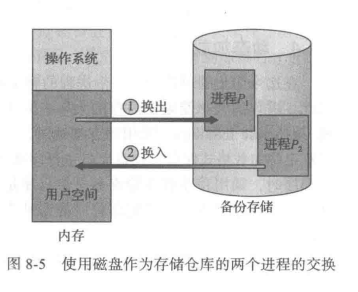
标准交换在内存与备份存储之间移动进程。
备份存储通常是快速磁盘。它应足够大,以容纳所有用户的所有内存映像的副本:并且它应提供对这些存储器映像的直接访问。系
统维护一个可运行的所有进程的就绪队列 (ready queue),它们的映像在备份存储或内存中。
当CPU调度器决定要执行一个进程时,它调用分派器。分派器检查队列中的下一个进程是否在内存中。如果不在,并且没有空闲内存区域,那么分派器会换出(swap out)当前位于内存中的一个进程,并换入(swap in)所需进程。然后,重新加载寄存器,并且将控制权转移到所选进程。
2.2 移动系统的交换 Swapping on Mobile Systems
Not typically supported
- Flash memory based
- Small amount of space
- Limited number of write cycles
- Poor throughput between flash memory and CPU on mobileplatform
Instead use other methods to free memory if low
- iOS asks apps to voluntarily relinquish allocated memory
- Read-only data thrown out and reloaded from flash if needed
- Failure to free can result in termination
- Android terminates apps if low free memory, but first writesapplication state to flash for fast restart
- Both OSes support paging as discussed below
通常不支持交换
- 基于闪存
- 空间小
- 有限的写周期数
- 移动平台上闪存和 CPU 之间的吞吐量低
如果内存不足,请改用其他方法释放内存
- iOS 要求应用程序自愿放弃分配的内存
- 只读数据被丢弃并在需要时从闪存重新加载
- 未能释放可能导致终止
- 如果可用内存不足,Android 会终止应用程序,但首先将应用程序状态写入闪存以快速重启
- 两种操作系统都支持分页,如下所述
3. 连续内存分配 Contiguous Allocation
Main memory must support both OS and user processes
Limited resource, must allocate efficiently
Contiguous allocation is one early method
Main memory usually into two partitions:
- Resident operating system, usually held in low memory with interrupt vector
- User processes then held in high memory
- Each process contained in single contiguous section of memory
Relocation registers used to protect user processes from each other, and from changing operating-system code and data
- Base register contains value of smallest physical address
- Limit register contains range of logical addresses – each logical address must be less than the limit register
- MMU maps logical address dynamically
- Can then allow actions such as kernel code being transient and kernel changing size
主内存必须同时支持操作系统和用户进程
资源有限,必须有效分配
连续分配是一种早期方法
内存通常分为两个区域:一个用于驻留操作系统,另一个用于用户进程。
- 驻留操作系统,通常保存在带有中断向量的低内存中
- 然后将用户进程保存在高内存中
- 每个进程都包含在单个连续的内存部分中(在采用连续内存分配(contiguous memory allocation)时每个进程位于一个连续的内存区域,与包含下一个进程的内存相连。)
重定位寄存器用于保护用户进程免受彼此影响,并防止更改操作系统代码和数据
- 基址寄存器包含最小物理地址的值
- 限制寄存器包含逻辑地址范围——每个逻辑地址必须小于限制寄存器
- MMU 动态映射逻辑地址
- 然后可以允许诸如内核代码瞬态和内核更改大小之类的操作
3.1 内存保护
重定位和界限寄存器的硬件支持:
3.2 内存分配
Multiple-partition allocation
- Degree of multiprogramming limited by number of partitions
- Variable-partition sizes for efficiency (sized to a given process’ needs)
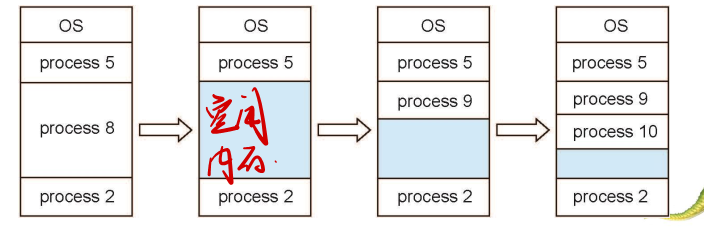
- Hole – block of available memory; holes of various size are scattered throughout memory
- When a process arrives, it is allocated memory from a hole large enough to accommodate it
- Process exiting frees its partition, adjacent free partitions combined
- Operating system maintains information about: a) allocated partitions b) free partitions (hole)
多分区分配
- 多进程并发程度受分区数限制
- 可变分区大小以提高效率(根据给定进程的需求调整大小)
- 孔 – 可用内存块;各种大小的孔散落在整个内存中
- 当进程到达时,它会从一个足够大的孔中分配内存以容纳它,如果孔太大,会将多余空间返回给孔的集合。
- 进程退出释放其分区,相邻的空闲分区合并,也就是将这些孔合并成大孔
- 操作系统维护以下信息: a) 分配的分区 b) 空闲分区(孔)
这种方法是通用动态存储分配问题(dynamic storage-allocation problem)(根据一组空闲孔来分配大小为 n 的请求)的一个特例。这个问题有许多解决方法。从一组可用孔中选择一个空闲孔的最为常用方法包括:首次适应 (first-fit)最优适应(best-fit)及最差适应(worst.fit)
dynamic Storage-Allocation Problem
How to satisfy a request of size n from a list of free holes?
-
First-fit: Allocate the first hole that is big enough
-
Best-fit: Allocate the smallest hole that is big enough; must search entire list, unless ordered by size Produces the smallest leftover hole
-
Worst-fit: Allocate the largest hole; must also search entire list Produces the largest leftover hole
First-fit and best-fit better than worst-fit in terms of speed and storage utilization
动态存储分配问题
如何满足可用孔列表中的 n 号请求?
-
首次适应:分配第一个足够大的孔
-
最优适应:分配足够大的最小孔;必须搜索整个列表,除非按大小排序 这种方法可以产生最小的剩余孔
-
最差适应:分配最大的孔;还必须搜索整个列表 产生最大的剩余孔
在速度和存储利用率方面,首次拟合和最佳拟合优于最适配
3.3 碎片 Fragmentation
External Fragmentation – total memory space exists to satisfy a request, but it is not contiguous
Internal Fragmentation – allocated memory may be slightly larger than requested memory; this size difference is memory internal to a partition, but not being used
First fit analysis reveals that given N blocks allocated, 0.5 N blocks lost to fragmentation
- 1/3 may be unusable -> 50-percent rule
Reduce external fragmentation by compaction
- Shuffle memory contents to place all free memory together in one large block
- Compaction is possible only if relocation is dynamic, and is done at execution time
- I/O problem
- Latch job in memory while it is involved in I/O
- Do I/O only into OS buffers
Now consider that backing store has same fragmentation problems
==外部碎片 – 存在总内存空间以满足请求,但它不是连续的,存储被分成了大量的小孔==
==内部碎片 – 分配的内存可能略大于请求的内存;此大小差异是分区内部的内存,但未使用==
首次适应分析表明,给定分配的N个块,0.5个块因碎片而丢失
- 1/3 可能不可用 -> 50% 规则
通过压缩(compaction )减少外部碎片
- 它的目的是移动内存内容,以便将所有空闲空间合并成一整块。
- 仅当重新定位是动态的并且在执行时完成时,才能进行压缩,如果重定位是静态的,并且在汇编时或加载时进行的,那么就不能紧缩。
- I/O 问题
- 在内存中涉及 I/O 时锁存作业
- 仅对操作系统缓冲区执行 I/O 操作
现在考虑后备存储具有相同的碎片问题
外部碎片化问题的另一个可能的解决方案是:允许进程的逻辑地址空间是不连续的;这样,只要有物理内存可用,就允许为进程分配内存。
有两种互补的技术可以实现这个解决方案:分段(8.4节)和分页(8.5节)。这两个技术也可以组合起来。
4. 分段 Segmentation
==分段会产生外部碎片,但是不会产生内部碎片==
Memory-management scheme that supports user view of memory
A program is a collection of segments
- A segment is a logical unit such as:
- main program
- procedure
- function
- method
- object
- local variables, global variables
- common block
- stack
- symbol table
- arrays
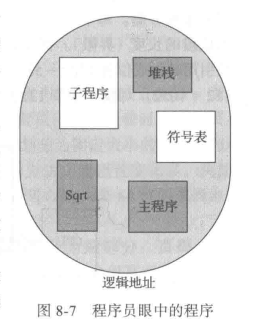
支持用户内存视图的内存管理方案
程序是段的集合
- 段是一个逻辑单元,例如:
- 主程序
- 程序
- 功能
- 方法
- 对象
- 局部变量、全局变量
- 公共块
- 栈
- 符号表
- 阵 列
4.1 基本方法
Logical address consists of a two tuple:
<segment-number, offset>,
Segment table – maps two-dimensional physical addresses; each table entry has:
- base – contains the starting physical address where the segments reside in memory
- limit – specifies the length of the segment
Segment-table base register (STBR) points to the segment table’s location in memory
Segment-table length register (STLR) indicates number of segments used by a program;
- segment number s is legal if s < STLR
Protection
- With each entry in segment table associate:
- validation bit = 0 -> illegal segment
- read/write/execute privileges
Protection bits associated with segments; code sharing occurs at segment level
Since segments vary in length, memory allocation is a dynamic storage-allocation problem
A segmentation example is shown in the following diagram
逻辑地址由有序对组成:
<段号,偏移>,
段表 – 映射二维物理地址;每个表条目具有:
- base – 包含段驻留在内存中的起始物理地址
- limit – 指定段的长度
段表基寄存器 (STBR) 指向段表在内存中的位置
段表长度寄存器(STLR)表示程序使用的段数;
- 段号 s 是合法的,如果 s < STLR
保护
-
与段表中的每个条目相关联:
-
验证位 = 0 ->非法段
-
读/写/执行权限
-
与段关联的保护位;代码共享发生在段级别
由于段的长度不同,因此内存分配是一个动态存储分配问题
下图显示了分段示例
4.2 分段硬件
虽然用户现在能够通过二维地址来引用程序内的对象,但是实际物理内存仍然是一维的字节序列。因此,我们应定义一个实现方式,以便映射用户定义的二维地址到一维物理地址。这个地址是通过段表(segment table)来实现的。段表的每个条目都有段基地址(segment base)和段界限(segment limit)。段基地址包含该段在内存中的开始物理地址,而段界限指定该段的长度。
段表的使用如图 8-8 所示。每个逻辑地址由两部分组成:段号s和段偏d。段号用作段表的索引,逻辑地址的偏移d应位于0和段界限之间。如果不是这样,那么会陷人操作系统中(逻辑地址试图访问段的外面)。如果偏移 d合法,那么就与基地址相加而得到所需字节的物理内存地址。因此,段表实际上是基址寄存器值和界限寄存器值的对的数组。
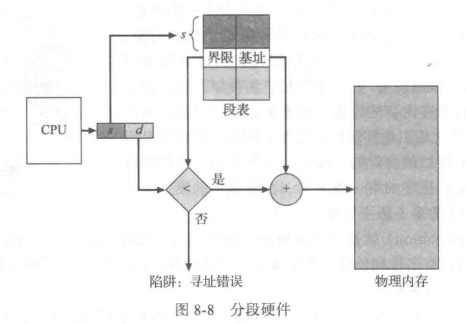
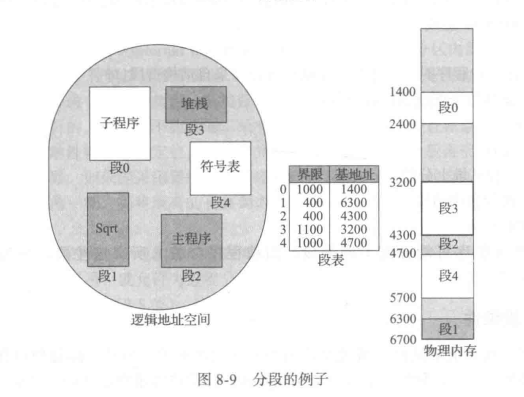
作为一个例子,假设如图8-9 所示的情况。假设有 5 个段,按0-4来编号。各段按如图所示来存储。每个段都在段表中有一个条目,它包括段在物理内存内的开始地址 (基地址)和该段的长度(界限)。例如,段2为400 字节长,开始于位置4300。因此,对段2字节 53的引用映射成位置4300 +3 = 4353。对段3 字节852的引用映射成位置3200(段3基地址)+852=4052。对段0字节1222的引用会陷入操作系统,这是由于该段仅为 1000 字节长。
5. 分页
==分页没有外部碎片,但是每个进程的最后一页可能会产生内部碎片==
分段允许进程的物理地址空间是非连续的。分页(paging)是提供这种优势的另一种内存管理方案。然而,分页避免了外部碎片和紧缩,而分段不可以。分页也避免了将不同大小的内存块匹配到交换空间的麻烦问题。
5.1 基本方法
实现分页的基本方法涉及将物理内存分为固定大小的块,称为帧或页帧 (frame);而将逻辑内存也分为同样大小的块,称为页或页面(page)。
当需要执行一个进程时,它的页从文件系统或备份存储等源处,加载到内存的可用帧。备份存储划分为固定大小的块,它与单个内存帧或与多个内存帧(簇)的大小一样。这个相当简单的方法功能强且变化多。例如逻辑地址空间现在完全独立于物理地址空间,因此,一个进程可以有一个 64位的逻辑地址空间,而系统的物理内存小于254 字节。
分页的硬件支持如图8-10 所示。由 CPU生成的每个地址分为两部分:页码(pagenumber)(p)和页偏移(page offset)(d)。页码作为页表的索引。页表包含每页所在物理内存的基地址。这个基地址与页偏移的组合就形成了物理内存地址,可发送到物理单元。内存的分页模型如图 8-11所示。
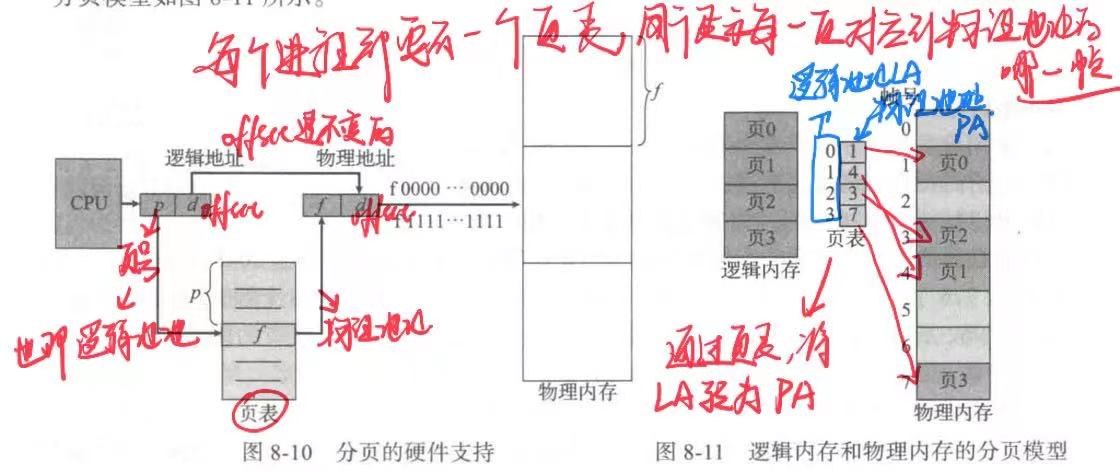
页大小(与帧大小一样)是由硬件来决定的。页的大小为 2 的幂;根据计算机体系结构的不同,页大小可从 512 字节到 1GB 不等。将页的大小选为 2 的幂可以方便地将逻辑地址转换为页码和页偏移。如果逻辑地址空间为 2m,且页大小为 2n字节,那么逻辑地址的高m-n 位表示页码,而低n位表示页偏移。这样,逻辑地址就如下图所示:
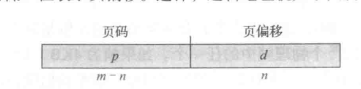
其中p作为页表的索引(index),而d作为页的偏移(offset)
(通过页码(index)来找到帧的起始地址)
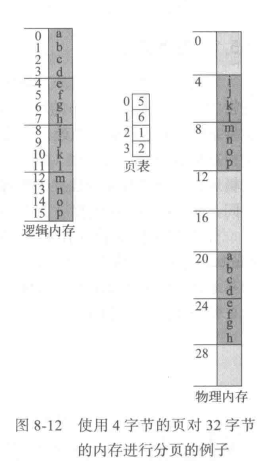
==采用分页方案不会产生外部碎片:每个空闲帧都可以分配给需要它的进程。不过,分页有内部碎片。==
如果进程大小与页大小无关,那么每个进程的内部碎片的均值为半页。
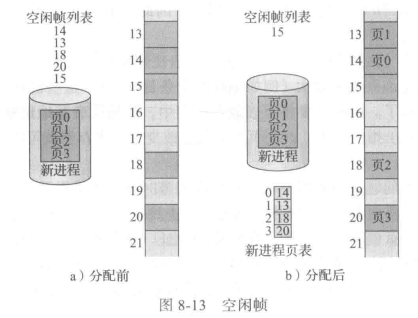
分页的一个重要方面是,程序员视图的内存和实际的物理内存的清楚分离。程序员将内存作为一整块来处理,而且它只包含这一个程序。事实上,一个用户程序与其他程序一起分散在物理内存上。程序员视图的内存和实际的物理内存的不同是通过地址转换硬件来协调的。逻辑地址转变成物理地址。这种映射,程序员是不知道的,它是由操作系统控制的。注意,根据定义,用户进程不能访问不属于它的内存。它无法访问它的页表规定之外的内存页表只包括进程拥有的那些页。
由于操作系统管理物理内存,它应知道物理内存的分配细节:哪些帧已分配,哪些帧空着,总共有多少帧,等等。这些信息通常保存在称为帧表(frame table)的数据结构中。在帧表中,每个条目对应着一个帧,以表示该帧是空闲还是已占用;如果占用,是被哪个(或哪些)进程的哪个页所占用。
另外,操作系统应意识到,用户进程是在用户空间内执行,所有逻辑地址需要映射到物理地址。如果用户执行一个系统调用(例如,要进行 I/0),并提供地址作为参数(如,个缓冲),那么这个地址应映射,以形成正确的物理地址。操作系统为每个进程维护一个页表的副本,就如同它需要维护指令计数器和寄存器的内容一样。每当操作系统自己将逻辑地址映射成物理地址时,这个副本可用作转换。当一个进程可分配到 CPU 时,CPU分派器也根据该副本来定义硬件页表。因此,==分页增加了上下文切换的时间==
5.2 硬件支持
页表的硬件实现有多种方法。最为简单的一种方法是,将页表作为一组专用的寄存器来实现。
如果页表比较小(例如 256 个条目),那么页表使用寄存器还是令人满意的。但是,大多数现代计算机都允许页表非常大(例如 100 万个条目)。对于这些机器,采用快速寄存器来实现页表就不可行了。因而需要将页表放在内存中,并将页表基地址寄存器(Page-TableBase Register,PTBR)指向页表。改变页表只需要改变这一寄存器就可以,这也大大降低了上下文切换的时间。
采用这种方法的问题是访问用户内存位置的所需时间。如果需要访问位置 i,那么应首先利用PTBR 的值,再加上i的页码作为偏移,来查找页表。这一任务需要内存访问。根据所得的帧码,再加上页偏移,就得到了真实物理地址。接着就可以访问内存内的所需位置。采用这种方案,访问一个字节需要两次内存访问(一次用于页表条目,一次用于字节)。这样,内存访问的速度就减半。在大多数情况下,这种延迟是无法忍受的。我们还不如采用交换机制!
这个问题的标准解决方案是采用专用的、小的、查找快速的高速硬件缓冲,它称为转换表缓冲区(Translation Look-aside Buffer,TLB)。(快表)
==所以访问内存流程如下:==
TLB 与页表一起使用的方法如下:TLB 只包含少数的页表条目。当CPU 产生一个逻辑地址后,它的页码就发送到 TLB。
- 如果找到这个页码,它的帧码也就立即可用,可用于访问内存。如上面所提到的,这些步骤可作为 CPU的流水线的一部分来执行;与没有实现分 页的系统相比,这并没有减低性能。
- 如果页码不在TLB 中(称为 TLB 未命中(TLB miss))那么就需访问页表。
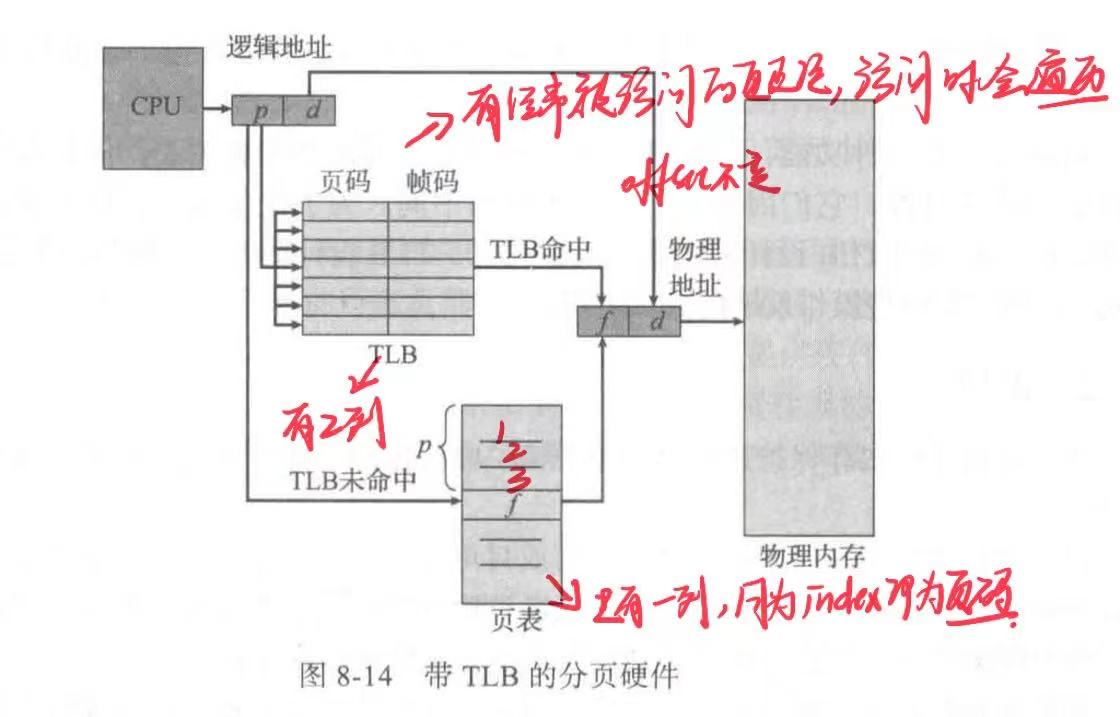
有的TLB在每个TLB条目中还保存地址空间标识符(Address-Space Identifier.ASID)。ASID 唯一标识每个进程,并为进程提供地址空间的保护。
在TLB 中查找到感兴趣页码的次数的百分比称为命中率(hit ratio)。
80%的命中率意味着,有80%的时间可以在 TLB 中找到所需的页码。如果需要 100ns 来访问内存,那么当页码在 TLB 中时,访问映射内存需要 100ns。如果不能在TLB 中找到,那么应先访问位于内存中的页表和帧码(100ns),并进而访问内存中的所需字节 (100ns),这总共要花费200ns。(这里假设页表查找只需要一次内存访问,但是它可能需要多次,后面会谈到。)为了求得有效内存访问时间(effective memory-access time),需要根据概率来进行加权:
有效访问时间=0.80x100+0.20x200=120ns
对于本例,平均内存访问时间多了20%(从100~120ns)。
对于 99% 的命中率,这是更现实的,我们有
有效访问时间=0.99x100+0.01x200=101ns
这种命中率的提高只多了 1% 的访问时间。

5.3 保护
还有一个位通常与页表中的每一条目相关联:有效-无效位(valid-invalid bit)。当该位为有效时,该值表示相关的页在进程的逻辑地址空间内,因此是合法(或有效)的页。当该位为无效时,该值表示相关的页不在进程的逻辑地址空间内。通过使用有效 -无效位,非法地址会被捕捉到。操作系统通过对该位的设置,可以允许或不允许对某页的访问。
5.4 共享页
分页的优点之一是可以共享公共代码。对于分时环境,这种考虑特别重要。假设一个支持40个用户的系统,每个都执行一个文本编辑器。如果该文本编辑器包括150KB 的代码及50KB的数据空间,则需要 8000KB 来支持这40个用户。如果代码是可重入代码(reentrant code)或纯代码(pure code),则可以共享,如图8-16 所示。这里,有3 个进程,它们共享3 页的编辑器,这里每页大小为 50KB(为了简化图,采用了大页面)。每个进程都有它自己的数据页。
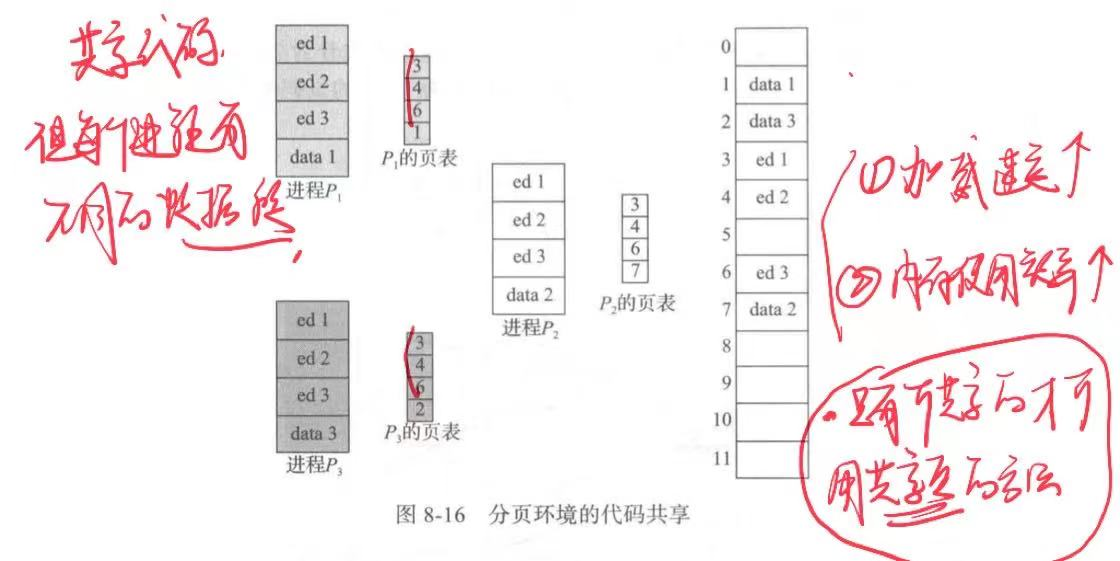
可重人代码是不能自我修改的代码:它在执行期间不会改变。因此,两个或更多个进程可以同时执行相同代码。每个进程都有它自己的寄存器副本和数据存储,以便保存进程执行的数据。当然,两个不同进程的数据不同。
6. 页表结构
这里的内容直接看书,P256