Process Synchronization
协作进程能与系统内其他执行的进程互相影响。协作进程可以通过两种方式来共享数据,第一种方法是直接共享逻辑地址空间(即代码和数据)(共享内存),第二种方法是通过文件或消息来共享数据(消息传递)。
第一种方法可以通过线程来实现,本章通过讨论多种机制,确保共享同一逻辑地址空间的协作进程的有序进行,从而维护数据的一致性。
Objectives
- To present the concept of process synchronization.
- To introduce the critical-section problem, whose solutions can be used to ensure the consistency of shared data
- To present both software and hardware solutions of the critical-section problem
- To examine several classical process-synchronization problems
-
To explore several tools that are used to solve process synchronization problems
- 提出进程同步的概念。
- 引入关键部分问题,其解决方案可用于确保共享数据的一致性
- 提出关键部分问题的软件和硬件解决方案
- 检查几个经典的进程同步问题
- 探索用于解决进程同步问题的几种工具
1. 背景 Background
- Processes can execute concurrently
- May be interrupted at any time, partially completing execution
- Concurrent access to shared data may result in data inconsistency
- Maintaining data consistency requires mechanisms to ensure the orderly execution of cooperating processes
-
Illustration of the problem:Suppose that we wanted to provide a solution to the consumer-producer problem that fills all the buffers. We can do so by having an integer counter that keeps track of the number of full buffers. Initially, counter is set to 0. It is incremented by the producer after it produces a new buffer and is decremented by the consumer after it consumes a buffer.
- 进程可以并发执行
- 可能随时中断,部分完成执行
- 并发访问共享数据可能会导致数据不一致
- 维护数据一致性需要确保合作流程有序执行的机制
- 问题说明:假设我们想为填充所有缓冲区的消费者-生产者问题(课本P176)提供一个解决方案。我们可以通过拥有一个整数来做到这一点 跟踪已满缓冲区数的计数器。最初,计数器设置为 0。它在生成新缓冲区后由生产者递增并在使用者消耗缓冲区后递减。
因为允许两个进程并发操作变量 counter,所以得到不正确的状态。像这样的情况,==即多个进程并发访问和操作同一数据并且执行结果与特定访问顺序有关,称为竞争条件(racecondition)。==为了防止竞争条件,需要确保一次只有一个进程可以操作变量 counter。为了做出这种保证,要求这些进程按一定方式来同步。 由于操作系统的不同部分都操作资源,这种情况在系统内经常出现。此外,正如前面章节所强调的,多核系统的日益流行强调了开发多线程应用的重要性。在这类应用中,多个线程,很可能共享数据,并在不同的处理核上并行运行。显然,我们要求,由于这些活动而导致的任何改变不会互相干扰。由于这个问题的重要性,本章的大部分都是,协作进程如何进行进程同步(process synchronization)和进程协调(process coordination)。
2. 临界区问题 Critical Section Problem
- Consider system of n processes {p0, p1, … pn-1}
- Each process has critical section segment of code
- Process may be changing common variables, updating table, writing file, etc
- When one process in critical section, no other may be in its critical section
- Critical section problem(临界区问题) is to design protocol to solve this
-
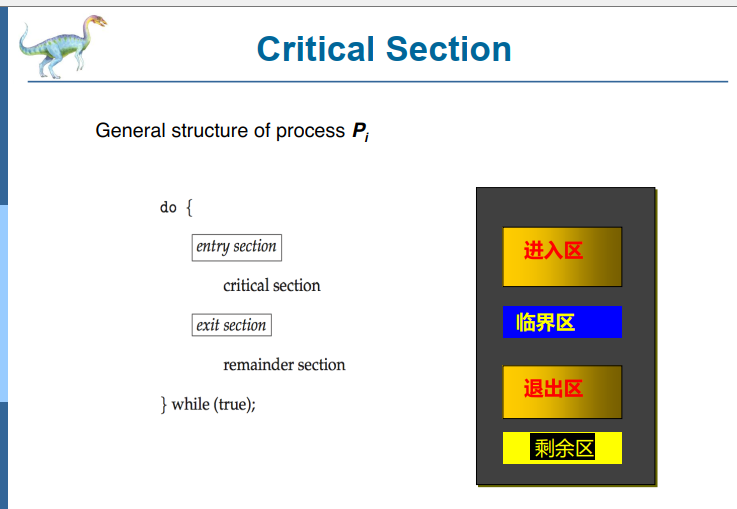
Each process must ask permission to enter critical section in entry section, may follow critical section with exit section, then remainder section
- 考虑 n 个进程的系统 {p0, p1, …pn-1}
- 每个进程都有代码的关键部分
- 进程可能正在更改公共变量,更新表,写入文件, 等
- 当一个过程处于关键部分时,没有其他过程可能处于其关键部分 部分
- 关键部分问题(临界区问题)是设计协议来解决这个问题
- 每个进程必须请求许可才可以通过进入区到临界区,然后临界区后紧跟着退出区,最后是剩余区。
2.1 Solution to Critical-Section Problem
- Mutual Exclusion - If process Pi is executing in its critical section, then no other processes can be executing in their critical sections
- Progress - If no process is executing in its critical section and there exist some processes that wish to enter their critical section, then the selection of the processes that will enter the critical section next cannot be postponed indefinitely
- Bounded Waiting - A bound must exist on the number of times that other processes are allowed to enter their critical sections after a process has made a request to enter its critical section and before that request is granted
- Assume that each process executes at a nonzero speed
- No assumption concerning relative speed of the n processes
- 互斥 - 如果进程 Pi 在其关键部分执行,则没有其他进程可以在其关键部分执行
- 进步 - 如果在其关键部分没有进程正在执行,并且存在一些希望进入其关键部分的进程,则接下来将进入关键部分的进程的选择不能无限期推迟
- 有限等待 - 在进程发出进入其关键部分的请求之后和该请求被授予之前,允许其他进程进入其关键部分的次数必须存在绑定
- 假设每个进程都以非零速度执行
- 没有关于n个过程的相对速度的假设
临界区问题的几个特点:
必须强制实施互斥,在具有关于相同资源或共享对象的临界区的所有进程中,一次只允许一个进程进入临界区;
一个在非临界区的进程必须不干涉其他进程;
不允许一个需要访问临界区的进程被无线延迟;
没有进程在临界区时,任何需要进入临界区的进程必须能够立即进入;
相关进程的速度和处理器数目没有任何要求和限制;
一个进程阻流在临界区中的时间必须时有限的;
总的来说,就是以下四句话:
- 有空让进
- 无空等待
- 择一而入
- 算法可行
2.2 Critical-Section Handling in OS
Two approaches depending on if kernel is preemptive or non- preemptive
- Preemptive – allows preemption of process when running in kernel mode
- Non-preemptive – runs until exits kernel mode, blocks, or voluntarily yields CPU
- Essentially free of race conditions in kernel mode
两种方法取决于内核是抢占式还是非抢占式
- 抢占 – 允许在内核模式下运行时抢占进程
- 非抢占式 – 运行直到退出内核模式、阻塞或自愿产生 CPU
- 非抢占式内核的数据结构基本不会导致竞争条件,因为任何时间只有一个进程处于内核模式。
那么,为何会有人更喜欢抢占式内核而不是非抢占式内核呢?抢占式内核响应更快,因为处于内核模式的进程在释放 CPU之前不会运行任意长的时间。(当然,在内核模式下持续运行很长时间的风险可以通过设计内核代码来最小化。 再者,抢占式内核更适用于实时编程,因为它能允许实时进程抢占在内核模态下运行的其他进程。本章后面将探讨多种操作系统如何管理抢占式内核。
3. Peterson’s Solution Peterson解决方案
- Good algorithmic description of solving the problem
- Two process solution
- Assume that the load and store machine-language instructions are atomic; that is, cannot be interrupted
- The two processes share two variables:
- int turn;
- Boolean flag[2]
- The variable turn indicates whose turn it is to enter the critical section
- The flag array is used to indicate if a process is ready to enter the critical section. flag[i] = true implies that process Pi is ready
一个经典的基于软件的临界区问题的解决方案,称为 Peterson解决方案
Peterson解决方案适用于两个进程交错执行临界区与剩余区。两个进程为P0和P1。为了方便,当使用Pi时,用Pj来表示另一个进程,即j== 1-i。
Peterson解答要求两个进程共享两个数据项:
int turn; boolean flag[2];
变量 turn表示哪个进程可以进人临界区。即如果turn == i 那么进程Pi允许在临界区内执行。数组 flag 表示哪个进程准备进入临界区。例如,如果 flag[i]为true,那么进程Pi;准备进入临界区。在解释了这些数据结构后,就可以分析如图 6-2所示的算法。

为了进入临界区,进程Pi首先设置 flag[i]的值为 true;并且设置 turn 的值为 j,从而表示如果另一个进程Pj希望进入临界区,那么Pj能够进入。如果两个进程同时试图进入,那么turn会几乎在同时设置成i和j。只有一个赋值语句的结果会保持;另一个也会设置,但会立即被重写。变量 turn的最终值决定了哪个进程允许先进入临界区。
4. 硬件同步 Synchronization Hardware
-
Many systems provide hardware support for implementing the critical section code.
- All solutions below based on idea of locking
- Protecting critical regions via locks
- Uniprocessors – could disable interrupts
- Currently running code would execute without preemption
- Generally too inefficient on multiprocessor systems
- Operating systems using this not broadly scalable
- Modern machines provide special atomic hardware instructions
- Atomic = non-interruptible
- Either test memory word and set value Or swap contents of two memory words
-
许多系统为实现关键部分代码提供硬件支持。
- 以下所有解决方案均基于加锁理念
- 通过锁保护关键区域
- 单处理器 – 可以禁用中断
- 当前运行的代码将在不抢占的情况下执行
- 在多处理器系统上通常效率太低
- 使用它的操作系统不能广泛扩展
- 现代机器提供特殊的原子硬件指令
- 原子 = 不可中断
- 测试记忆字并设置值或交换两个记忆字的内容
我们刚刚描述了临界区问题的一种基于软件的解答。然而,正如所提到的,基于软件的解决方案(如Peterson 解答)并不保证在现代计算机体系结构上正确工作。下面,我们探讨临界区问题的多个解答,这包括内核开发人员和应用程序员采用的硬件和软件 API技术所有这些解答都是基于加锁(locking)为前提的,即通过锁来保护临界区。正如将会看到的,这种锁的设计可能相当复杂。
首先,我们介绍一些简单的硬件指令(许多系统都具有的),并有效使用它们来解决临界区问题。硬件功能能够简化编程工作而且提高系统效率。
对于单处理器环境,临界区问题可简单地加以解决:在修改共享变量时只要禁止中断出现。这样,就能确保当前指令流可以有序执行,且不会被抢占。由于不可能执行其他指令所以共享变量不会被意外地修改。这种方法往往为非抢占式内核所采用。
然而,在多处理器环境下,这种解决方案是不可行的。多处理器的中断禁止会很耗时因为消息要传递到所有处理器。消息传递会延迟进入临界区,并降低系统效率。另外,如果系统时钟是通过中断来更新的,那么它也会受到影响。
因此,许多现代系统提供特殊硬件指令,用于检测和修改字的内容,或者用于原子地(atomically)交换两个字(作为不可中断的指令)。我们可以采用这些特殊指令,相对简单地解决临界区问题。这里,我们不是讨论特定机器的特定指令,而是通过指令 test_and_set()和 compare_and_swap()抽象了这些指令背后的主要概念。指令 test_and_set()可以按图6-3 所示来定义。这一指令的重要特征是,它的执行是原子的。因此,如果两个指令 test_and_set()同时执行在不同CPU上,那么它们会按任意次序来顺序执行。如果一台机器支持指令 test_and_set(),那么可以这样实现互斥:声明一个布尔变量 lock,初始化为 false。进程P的结构如图6-4 所示。

(具体内容和解释看课本P181)
5. 互斥锁 Mutex Locks
- Previous solutions are complicated and generally inaccessible to application programmers
- OS designers build software tools to solve critical section problem
- Simplest is mutex lock
- Protect a critical section by first acquire() a lock then release() the lock
- Boolean variable indicating if lock is available or not
- Calls to acquire() and release() must be atomic
- Usually implemented via hardware atomic instructions
- But this solution requires busy waiting
- This lock therefore called a spinlock
- 以前的解决方案很复杂,应用程序员通常无法访问
- 操作系统设计师构建软件工具来解决关键部分问题
- 最简单的是互斥锁
- 通过首先acquire()获得锁然后 release()锁来保护关键部分
- 指示锁是否可用的布尔变量
- 对 acquire() 和 release() 的调用必须是原子的
- 通常通过硬件原子指令实现
- 但此解决方案需要忙等待(会浪费CPU时间)
- 因此,此锁称为旋转锁
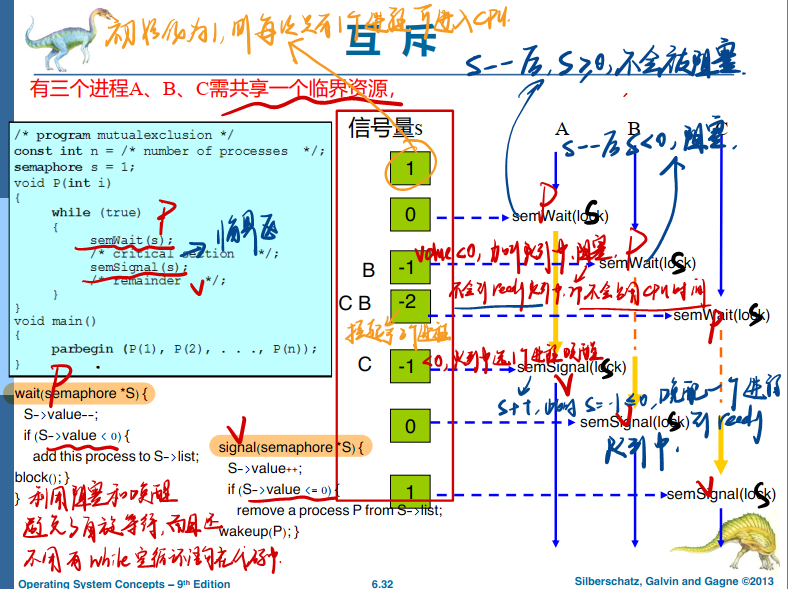
我们采用互斥锁保护临界区,从而防止竞争条件。也就是说,一个进程在进入临界区时应得到锁;它在退出临界区时释放锁。函数 acquire()获取锁,而函数release()释放锁。
每个互斥锁有一个布尔变量 available,它的值表示锁是否可用。如果锁是可用的,那么调用acquire()会成功,并且锁不再可用。当一个进程试图获取不可用的锁时,它会阻塞,直到锁被释放。
按如下定义acquire():
1
2
3
4
5
acquire(){
while (!available)
;/*busywait */
available = false;
}
按如下定义release():
1
2
3
release(){
available = true;
}
这里所给实现的主要缺点是,它需要忙等待 (busy waiting)。当有一个进程在临界区中,任何其他进程在进入临界区时必须连续循环地调用 acquire()。其实,这种类型的互斥锁也被称为自旋锁(spinlock),因为进程不停地转,以等待锁变得可用。(在前面采用指令test_and_set()和compare_and_swap()的那些例子中,有同样的问题。在实际多道程序系统中,即当多个进程共享同一 CPU 时,这种连续循环显然是个问题。忙等待浪费 CPU周期,而这原本可以有效用于其他进程。)
不过,自旋锁确实有一个优点:当进程在等待锁时,没有上下文切换(上下文切换可能需要相当长的时间)。因此,当使用锁的时间较短时,自旋锁还是有用的。自旋锁通常用于多处理器系统,一个线程可以在一个处理器上“旋转”,而其他线程在其他处理器上执行临界区本章(6.7 节),将会研究如何使用互斥锁解决经典同步问题,还会讨论多个操作系统以及Pthreads如何使用这些锁。
6. 信号量 Semaphore
前面方法解决临界区调度问题的缺点:
- 对不能进入临界区的进程, 采用忙式等待测试法, 浪费CPU时间。
- 将测试能否进入临界区的责任推给各个竞争的进程会削弱系统的可靠性, 加重了用户编程负担。
1965年E.W.Dijkstra(荷兰人)提出了新的同步工具–信号量和P (荷兰语的测试Proberen) semWait、 V操作(荷兰语的增量Verhogen) semSignal
- P操作:让进程休眠
- V操作:唤醒一个进程
信号量和P、 V操作 ,将交通管制中多种颜色的信号灯管理交通的方法引入操作系统,让两个或多个进程通过特殊变量展开交互。
信号量:一种软资源
- 一个进程在某一特殊点上被迫停止执行直到接收到一个对应的特殊变量值,这种特殊变量就是信号量(Semaphore),复杂的进程合作需求都可以通过适当的信号结构得到满足。
- 原语:内核中执行时不可被中断的过程
Synchronization tool that provides more sophisticated ways (than Mutex locks) for process to synchronize their activities.(同步工具,为进程同步其活动提供更复杂的方法(互斥锁))
Semaphore S – integer variable(信号量 S – 整数变量)
Can only be accessed via two indivisible (atomic) operations(只能通过两个不可分割(原子)操作访问)
- wait() and signal()
- Originally called P() and V()
Definition of the wait() operation
1
2
3
4
5
wait(S) {
while (S <= 0)
; // busy wait
S--;
}
Definition of the signal() operation
1
2
3
signal(S) {
S++;
}
二元信号量

互斥
6.1 Semaphore Usage 信号量的使用
-
Counting semaphore – integer value can range over an unrestricted domain
-
Binary semaphore – integer value can range only between 0 and 1
- Same as a mutex lock
-
Can solve various synchronization problems
-
Consider P1 and P2 that require S1 to happen before S2
-
Create a semaphore “synch” initialized to 0
1 2 3
P1: S1; signal(synch);1 2 3
P2: wait(synch); S2;Can implement a counting semaphore S as a binary semaphore
-
计数信号量 – 整数值的范围可以跨越不受限制的域
-
二进制信号量 – 整数值的范围只能在 0 到 1 之间
- 与互斥锁相同
-
可以解决各种同步问题
-
考虑要求 S1 在 S2 之前发生的 P1 和 P2
-
创建初始化为 0 的信号量“同步”
1 2 3
P1: S1; signal(synch);1 2 3
P2: wait(synch); S2;Can implement a counting semaphore S as a binary semaphore
可以将计数信号量 S 实现为二进制信号量
6.2 信号量的实现 Semaphore Implementation
- Must guarantee that no two processes can execute the wait() and signal() on the same semaphore at the same time
- Thus, the implementation becomes the critical section problem where the wait and signal code are placed in the critical section
- Could now have busy waiting in critical section implementation
- But implementation code is short
- Little busy waiting if critical section rarely occupied
- Could now have busy waiting in critical section implementation
-
Note that applications may spend lots of time in critical sections and therefore this is not a good solution
- 必须保证没有两个进程可以同时在同一个信号量上执行 wait() 和 signal()
- 因此,实现成为关键部分的问题,其中等待和信号代码被放置在关键部分
- 现在可以忙于等待关键部分的实施
- 但是实现代码很短
- 如果关键部分很少有人占用,则很少忙于等待
- 现在可以忙于等待关键部分的实施
- 请注意,应用程序可能会在关键部分花费大量时间,因此这不是一个好的解决方案
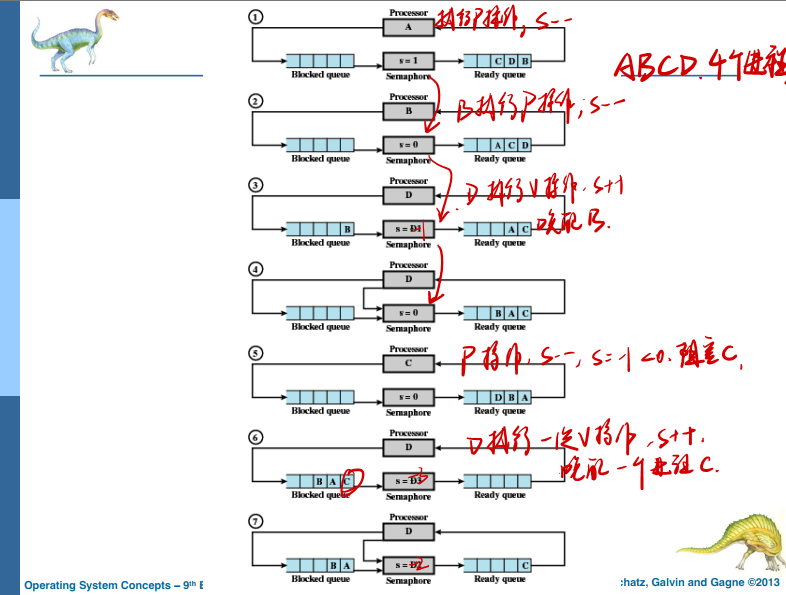
Semaphore Implementation with no Busy waiting
-
With each semaphore there is an associated waiting queue
-
Each entry in a waiting queue has two data items:
- value (of type integer)
- pointer to next record in the list
-
Two operations:
- block – place the process invoking the operation on the appropriate waiting queue
- wakeup – remove one of processes in the waiting queue and place it in the ready queue
1 2 3 4
typedef struct{ int value; struct process *list; } semaphore; - 每个信号灯都有一个关联的等待队列
- 等待队列中的每个条目都有两个数据项:
- 值(整数类型)
- 指向列表中下一条记录的指针
- 两个操作:
- block – 将调用操作的进程放在适当的等待队列上
- 唤醒 – 删除等待队列中的一个进程并将其放入就绪队列中
1
2
3
4
typedef struct{
int value;
struct process *list;
} semaphore;

6.3 死锁和饥饿 Deadlock and Starvation
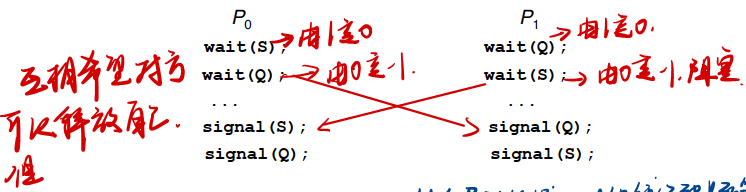
Deadlock – two or more processes are waiting indefinitely for an event that can be caused by only one of the waiting processes
Let S and Q be two semaphores initialized to 1
死锁 – 两个或多个进程无限期地等待可能仅由其中一个等待进程引起的事件
设 S 和 Q 是初始化为 1 的两个信号量
- Starvation – indefinite blocking A process may never be removed from the semaphore queue in which it is suspended
-
Priority Inversion – Scheduling problem when lower-priority process holds a lock needed by higher-priority process Solved via priority-inheritance protocol
- 饥饿 – 无限期封锁 进程可能永远不会从挂起的信号量队列中删除
- 优先级反转 – 当低优先级进程持有高优先级进程所需的锁时出现调度问题 通过优先级继承协议解决
6.4 优先级反转
如果一个较高优先级的进程需要读取或修改内核数据,而且这个内核数据当前正被较低优先级的进程访问(这种串联方式可涉及更多进程),那么就会出现一个调度挑战。由于内核数据通常是用锁保护的,较高优先级的进程将不得不等待较低优先级的进程用完资源。如果较低优先级的进程被较高优先级的进程抢占,那么情况变得更加复杂。
作为一个例子,假设有三个进程,L、M和H,它们的优先级顺序为L<M<H。假定进程H需要资源R,而R目前正在被进程L访问。通常,进程H将等待L用完资源R。但是,现在假设进程M进入可运行状态,从而抢占进程L。间接地,具有较低优先级的进程M,影响了进程H应等待多久,才会使得进程L释放资源R。
这个问题称为优先级反转(priority inversion)。它只出现在具有两个以上优先级的系统因此一个解决方案是只有两个优先级。
6.5 信号量小结
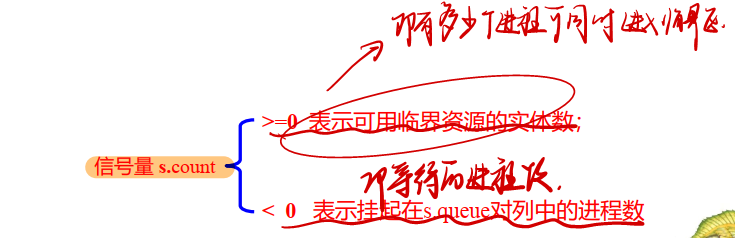
若信号量s.count>=0, 则该值等于可以执行semWait(s)而不需要挂起的进程数。
若信号量s.count为负值, 则其绝对值等于登记排列在该信号量s.queue队列之中等待的进程个数、 亦即恰好等于对信号量s实施semSignal操作而被封锁起来并进入信号量s.queue队列的进程数。
7. 经典同步问题
之后的内容直接看MarginNote3的书P185开始