Alpha-beta剪枝算法设计一个中国象棋博弈程序
一、 实验题目
博弈树搜索,用Alpha-beta剪枝算法设计一个中国象棋博弈程序
二、 实验内容
1.算法原理
本次项目的UI是参考了网上的代码。重点分析alpha-beta剪枝算法,关于UI部分就不详细分析了。本次实验还加入了历史启发式函数增加搜索效率。
着法生成
判断着法的合法性可分为以下几个步骤。 (1) 判断棋子的移动是否在棋盘的范围之内,如果超出,一定不是合法的着法。 (2) 根据行棋方的不同,判断着法是否是吃到己方棋子的着法,如果是,那么一定是不合法的着法。 (3) 根据兵种的不同,判断棋子的走法是否符合中国象棋的规则,主要有以下几个方面: 将、士是否走出九宫。 象是否过河,象眼是否被堵。 马是否蹩脚。 炮要翻山吃子。 兵过河前只能前进,过河后可以前进和左右移动。 本文设计的着法生成主要采用棋盘扫描法:
1
def get_put_down_postion(self, cur_chess):
局面评估
首先我们来看棋局的评估,能否对棋局有一个好的评估是这个算法很关键的一环。我们需要对棋局做出合适的评估,以确定最好的走步。每次估值都需要分开两方的棋子来进行估值。即算出程序方棋局的总体价值和对手方棋局的整体价值。==用程序方估值-对手方估值作为这个状态下的估值。如果这个估值大于0,说明程序方占优势;反之,说明对手方占优势。==
本程序的棋局评估考虑一下两方面:
- 棋子价值
- 棋子位置分值
棋子价值是依据不同棋子具有的不同的攻击力和防御能力,赋予其固定的分值。
| 棋子 | 帅/将 | 车 | 炮 | 马 | 士 | 相/象 | 兵/卒 |
|---|---|---|---|---|---|---|---|
| 分值 | 6000 | 600 | 300 | 270 | 120 | 120 | 30 |
棋子在棋局的中真正价值,不仅与固定分值有关,其所在的位置也十分重要。
例如,沉底炮、过河卒、以及车占士角等都是较好的棋子位置状态,而窝心马、将(帅)离开底线等则属较差的棋子位置状态。由于各类棋子都有自己特有的行棋方法,因此配备一张位置分值表,表中给出了不同棋子在不同位置上的分值。
(具体位置分值表可见code文件夹中Value.py文件)
alpha-beta剪枝
完成好估值后,就可以开始alpha-beta的剪枝算法了。首先确定博弈树的深度,通俗来说就是要让程序往后推演几步。当然推演的步数越多,越能找到一个好的走步,但是所需的时间也就越多。然后我们需要使用一个标记来表示当前是极大层还是在极小层,根据标记来计算当前节点的α或β。如果在极大层,我们需要获得它下面所有极小层的倒推值的极大值(实际上不是所有);如果在极小层,就需要获得它下面所有极大层的倒推层的极小值(实际上不是所有)。这里就牵涉到了剪枝。以在极大层为例,如果当前MAX节点提供的倒推值α大于其前驱极小层MIN节点的β,那么说明这个MAX节点以下搜索提供的值不可能小于α,也就没有继续搜索的意义了,所以就可以直接结束这个MAX节点的搜索,这就是剪枝。
假设α为下界,β为上界,对于α ≤ N ≤ β:
若 α ≤ β 则N有解。(该节点还有继续计算的价值)
若 α > β 则N无解。(停止该节点剩余内容的计算,也不会再更新α、β值)
α-β初始为负无穷到正无穷,算法过程中不断的缩小α-β范围。Max层增加本节点的α,Min层减小本节点的β。
一个节点的初始α、β值来自于父节点。父节点如果还没有相应值,子节点的相应值则是初始的正负无穷。
对于AI节点(Max层),希望挑选子节点中的最大节点。所以会更新最小值α(因为每得到一个符合条件的更大的值时,以后的新值必须更大才会被选择)。新的最小值α来自于已经计算的子节点(中的最大值)。但最大不能大于于父节点的β。
对于玩家方节点(Min层),希望挑选子节点中的最小节点。所以会更新最大值β。新的最大值β来自于已经计算的子节点(中的最小值)。但最小不能小于父节点的α。
何时剪枝的文字描述:
-
后辈极小节点的值≤祖先极大节点的值时,发生剪枝,称为α剪枝。
-
后辈极大节点的值≥祖先极小节点的值时,发生剪枝,称为β剪枝。
这里发生剪枝的条件都是后辈跟祖先比较,不只是跟父节点比,只要有一个祖先满足剪枝条件就发生剪枝。
具体来说,剪枝规则如下:
- α 剪枝。若任一极小层节点的β值不大于它任一前驱极大层节点的α 值,即α (前驱层)≥β(后继层),则可以中止该极小层中这个MIN节点以下的搜索过程。这个MIN节点最终的倒推值就确定为这个β值。
- β剪枝。若任一极大层节点的α 值不小于它任一前驱极小层节点的β值,即α (后继层)≥β(前驱层),则可以中止该极大层中这个MAX节点以下的搜索过程。这个MAX节点最终的倒推值就确定为这个α 值。
具体到代码,则为:
1
2
if alpha >= beta:
break
2.伪代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
输入:搜索深度 depth, alpha, beta;
输出:剪枝时的极大值 alpha 或极小值 beta。
alpha_beta(depth, alpha, beta)
BEGIN
(1) if GameOver or depth≤0 Then /*GameOver 判断棋局是否结束, dept≤0 则达到设置的搜索深度*/
(2) { Return(Evaluation) } /*Evaluation 是棋局局面的估值*/
(3) 初始化极大值 alpha= -INFINITY-1 和极小值 beta= INFINITY+1; /* INFINITY 代表无穷大*/
(4) if 极大值结点 Then
(5) {生成当前局面的所有可行着法集 M;
(6) for M 中的每一个着法 do
(7) {执行着法 Mi;
(8) value= alpha_beta(depth-1,alpha,beta); /*递归搜索子节点 */
(9) 撤销着法 Mi;
(10) if value >alpha Then
(11) { alpha= value; /*取极大值*/
(12) if alpha >= beta Then
(13) return beta;} /*beta 剪枝,抛弃后继节点*/
(14) End for}
(15) return alpha; } /*返回极大值*/
(16) if 极小值结点 Then
(17) {生成当前局面的所有可行着法集 M;
(18) For M 中的每一个着法 do
(19) {执行着法 Mi;
(20) value= AlphaBeta_Search (depth-1,alpha,beta);
(21) 撤销着法 Mi;
(22) if value < beta Then
(23) { beta= value; /*取极小值*/
(24) if beta <= alpha Then
(25) return alpha;} /*alpha 剪枝,抛弃后继节点*/
(26) EndFor}
(27) return beta;}
END
在搜索进行中,每个搜索节点的值都在与 alpha 和 beta 进行比较,如果某个着法的结果小于或等于 alpha,那么它就是很差的着法,应该将其抛弃。如果某个着法的结果大于或者等于 beta,那么整个节点废弃,因为对手不会希望走到这个局面,它会采用别的着法来避免达到这个局面。当某个着法的结果大于 alpha 并且小于 beta时,这个着法就是走棋一方可以考虑的着法。
3.关键代码展示(带注释)
完全按照伪代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
def alpha_beta(self, depth, alpha, beta): # alpha-beta剪枝,alpha是大可能下界,beta是最小可能上界
#偶数层AI持棋,取最大,奇数层玩家持棋,取最小
current_player = (self.max_depth - depth) % 2 # 当前轮到哪个玩家持棋,0代表黑方,1代表红方
if current_player == 1:
current_team = 'r'
else:
current_team = 'b'
if self.board.judge_win(current_team):
return -1000000
if depth == 1:
return self.evaluate()
possible_moves = self.board.generate_move(current_player) # 返回所有能走的方法
if current_player == 0:
for move in possible_moves:
if move:
temp = self.move_to(move)
score = self.alpha_beta(depth - 1, alpha, beta)
if move:
self.undo_move(move, temp)
if score > alpha:
alpha = score
if alpha >= beta:
return beta
if depth == self.max_depth:
self.best_move = move
return alpha
else:
for move in possible_moves:
if move:
temp = self.move_to(move)
score = self.alpha_beta(depth - 1, alpha, beta)
if move:
self.undo_move(move, temp)
if score < beta:
beta = score
if beta<=alpha:
return alpha
if depth == self.max_depth:
self.best_move = move
return beta
但是可以发现其实有可以合并的地方,可以修改为以下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
def alpha_beta(self, depth, alpha, beta): # alpha-beta剪枝,alpha是大可能下界,beta是最小可能上界
#偶数层AI持棋,取最大,奇数层玩家持棋,取最小
current_player = (self.max_depth - depth) % 2 # 当前轮到哪个玩家持棋,0代表黑方,1代表红方
if current_player == 1:
current_team = 'r'
else:
current_team = 'b'
if self.board.judge_win(current_team):
return -1000000
if depth == 1:
return self.evaluate()
possible_moves = self.board.generate_move(current_player) # 返回所有能走的方法
for move in possible_moves:
if move:
temp = self.move_to(move)
score = self.alpha_beta(depth - 1, alpha, beta)
if move:
self.undo_move(move, temp)
if current_player == 0:
if score > alpha:
alpha = score
if depth == self.max_depth:
self.best_move = move
alpha=max(alpha,score)
else:
if score < beta:
beta = score
if depth == self.max_depth:
self.best_move = move
beta=min(beta,score)
if alpha >= beta:
break
return alpha if current_player == 0 else beta
4.创新点&优化(如果有)
启用历史启发式函数加速AI下棋速度。
Alpha-Beta搜索算法的效率在很大程度上取决于搜索树的结构。如果搜索了没多久就能够进行“裁剪”,那么需要分析的工作量将大大减少,效率自然也就大大提高。为了保证Alpha-Beta搜索算法的效率,我们需要调整搜索结点的顺序,使得“裁剪”可以尽可能早地发生。为了调整搜索结点的顺序,我们可以根据部分已经搜索过的结果来进行历史启发式。在搜索的过程中,每当发现一个好的走法,就给该走法累加一个增量以记录其“历史得分”,多次被搜索并认为是好的走法的“历史得分”就会较高。对于即将搜索的结点,按照“历史得分”的高低对它们进行排序,保证较好的走法排在前面。这样Alpha-Beta搜索就可以尽可能早地进行“裁剪”,从而保证了搜索的效率。
历史启发式函数的作用是通过排序所有可能的走法,使得搜索时优先考虑历史得分高的走法,从而减少搜索树的分支,提高搜索效率。因为在实际游戏中,很多棋局中有一些重要的走法,而这些走法通常会出现在历史得分高的走法中,所以通过历史启发式函数,我们可以更加有效地搜索到更优的棋局。
理伦上,与电脑下棋的次数越多,那么它计算的速度就会更快,因为会将历史得分保存到本地的文件中,在每次棋局开始前先载入历史表,每次棋局结束后保存该局的历史表,那么多次训练后就可以增加搜索深度。
History_Heuristic.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import pickle
# 存放历史棋盘
history_chessboard = []
# 将历史启发表保存到文件中
def save_history_table():
with open('history_table.pkl', 'wb') as f:
pickle.dump(history_table, f)
# print_history_table()
# 从文件中读取历史启发表
def load_history_table():
with open('history_table.pkl', 'rb') as f:
return pickle.load(f)
# 保存历史启发式的值
history_table = [[0 for _ in range(9)] for _ in range(10)]
# 根据历史启发式的值,对走法进行排序
def sort_moves(moves):
moves.sort(key=lambda x: history_table[x[0]][x[1]], reverse=True)
return moves
# 打印历史表
def print_history_table():
for i in range(10):
for j in range(9):
print(history_table[i][j], end=' ')
print()
加入历史启发式函数后的alpha_beta函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
#加入历史启发式函数
def alpha_beta(self, depth, alpha, beta): # alpha-beta剪枝,alpha是大可能下界,beta是最小可能上界
#偶数层AI持棋,取最大,奇数层玩家持棋,取最小
current_player = (self.max_depth - depth) % 2 # 当前轮到哪个玩家持棋,0代表黑方,1代表红方
if current_player == 1:
current_team = 'r'
else:
current_team = 'b'
if self.board.judge_win(current_team):
return -1000000
if depth == 1:
return self.evaluate()
possible_moves = self.board.generate_move(current_player) # 返回所有能走的方法
# 根据历史启发式的值,对走法进行排序
sorted_moves = hh.sort_moves(possible_moves)
for move in sorted_moves:
if move:
temp = self.move_to(move)
score = self.alpha_beta(depth - 1, alpha, beta)
if move:
self.undo_move(move, temp)
if current_player == 0:
if score > alpha:
alpha = score
if depth == self.max_depth:
self.best_move = move
hh.history_table[move[0]][move[1]] += depth ** 2
alpha=max(alpha,score)
else:
if score < beta:
beta = score
if depth == self.max_depth:
self.best_move = move
hh.history_table[move[0]][move[1]] -= depth ** 2
beta=min(beta,score)
if alpha >= beta:
break
return alpha if current_player == 0 else beta
同时还加入了悔棋、重新开始、认输的功能。
三、 实验结果及分析
1.实验结果展示示例
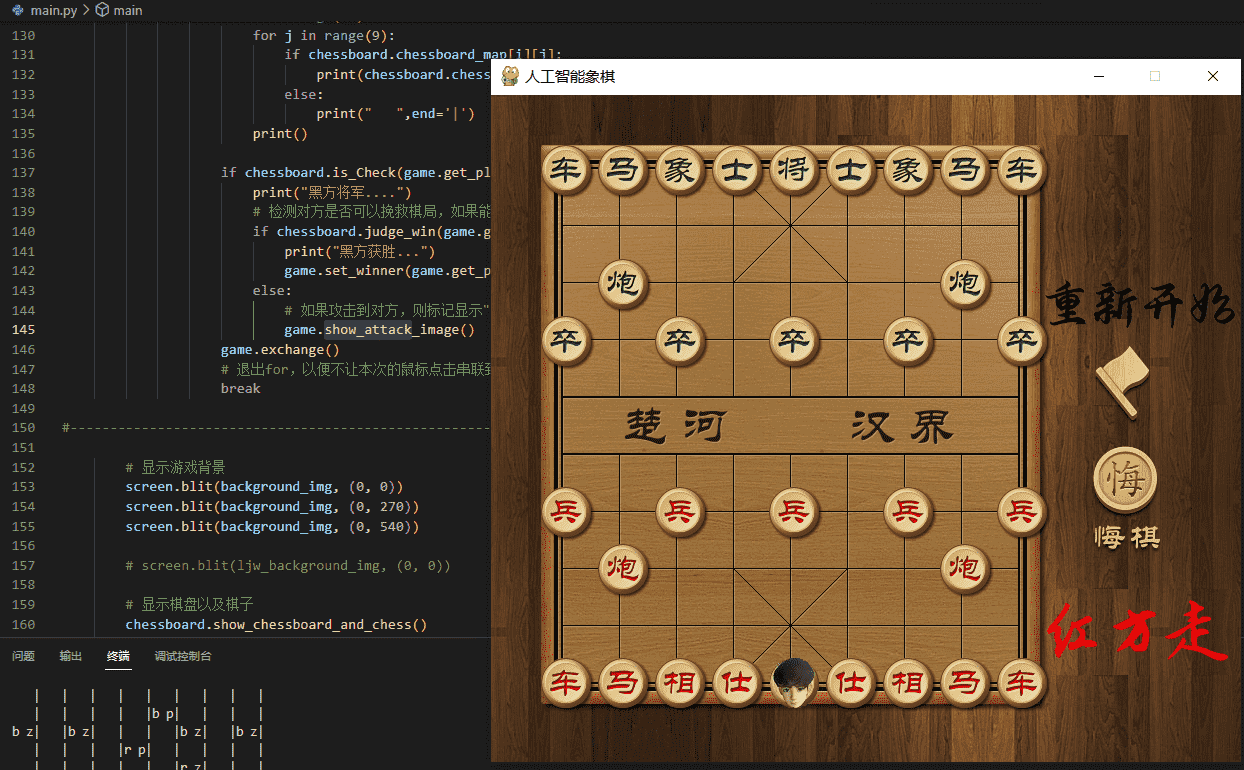
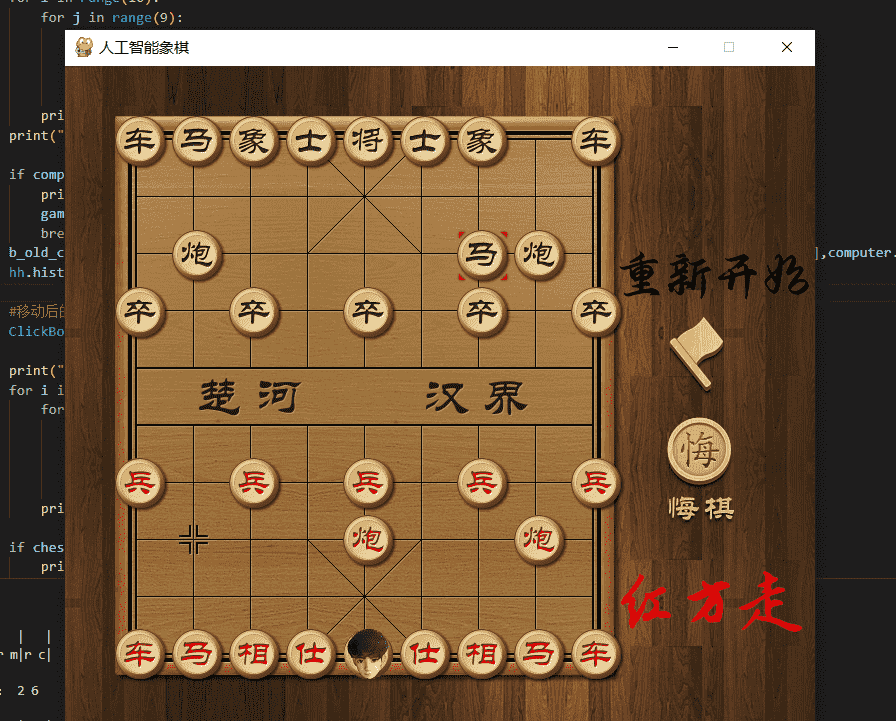
为了使得象棋更具个人风格,我将红方的“帅”修改为自己的微信头像。为了方便观察电脑走步,移动后的棋子上会有红色方框。
2.评测指标展示及分析
经过对弈,本象棋基本达到大多数人类水平,有几率可以通过天天象棋的人机对战的小白难度(人类对小白难度通过率为54.14%)