CPU调度即为短程调度,在本章中不特别区分进程和线程
Objectives
- To introduce CPU scheduling, which is the basis for multiprogrammed operating systems
- To describe various CPU-scheduling algorithms
- To discuss evaluation criteria for selecting a CPU-scheduling algorithm for a particular system
-
To examine the scheduling algorithms of several operating systems
- 引入CPU调度,这是多程序操作系统的基础
- 描述各种CPU调度算法
- 讨论为特定系统选择CPU调度算法的评估标准
- 检查几种操作系统的调度算法
1. Basic Concepts 基本概念
1.1 CPU-I/O 执行周期
- Maximum CPU utilization obtained with multiprogramming
- CPU–I/O Burst Cycle – Process execution consists of a cycle of CPU execution and I/O wait
- CPU burst followed by I/O burst
-
CPU burst distribution is of main concern
- 通过多道并发获得的最大 CPU 利用率
- CPU–I/O 突发周期 – 进程执行包括 CPU 执行和 I/O 等待周期
- CPU 突发,然后是 I/O 突发
- CPU 突发分布是主要关注点
进程执行包括周期(cycle)进行 CPU执行和I/O 等待。进程在这两个状态之间不断交替。进程执行从CPU执行(CPU burst)开始,之后I/O执行(I/O burst);接着另一个CPU 执行,接着另一个I/O执行;等等。最终,最后的 CPU 执行通过系统请求结束,以便终止执行(图 5-1)。
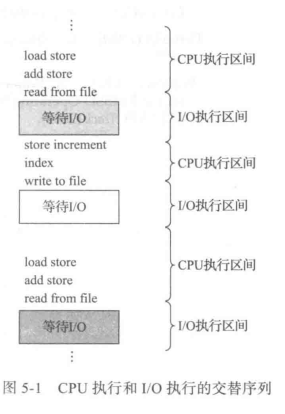
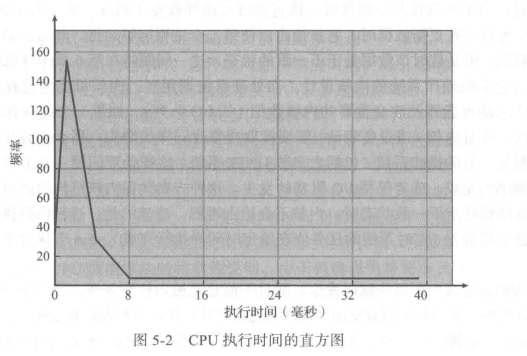
由图可知,具有大量短 CPU执行和少量长CPU 执行。I/0 密集型程序通常具有大量短CPU 执行。CPU 密集型程序可能只有少量长 CPU 执行。对于选择合适的 CPU 调度算法,这种分布是很重要的。
1.2 CPU调度程序 CPU Scheduler
Short-term scheduler selects from among the processes in ready queue, and allocates the CPU to one of them
- Queue may be ordered in various ways
CPU scheduling decisions may take place when a process:
- Switches from running to waiting state
- Switches from running to ready state
- Switches from waiting to ready
- Terminates
Scheduling under 1 and 4 is nonpreemptive
All other scheduling is preemptive
- Consider access to shared data
- Consider preemption while in kernel mode
- Consider interrupts occurring during crucial OS activities
短期调度程序从就绪队列中的进程中进行选择,并将CPU分配给其中一个
- 队列可以以各种方式排序
CPU 调度决策可能发生在进程:
1.从运行状态切换到等待状态 2.从运行状态切换到就绪状态 3.从等待切换到就绪 4.终止
1 和 4 下的调度是非抢占式的
所有其他调度都是抢占式的
- 考虑访问共享数据
- 在内核模式下考虑抢占
- 考虑在关键操作系统活动期间发生的中断
需要进行 CPU调度的情况可分为以下四种:
-
当一个进程从运行状态切换到等待状态时(例如,I/0 请求,或wait()调用以便等待一个子进程的终止)。
-
当一个进程从运行状态切换到就绪状态时(例如,当出现中断时)。
-
当一个进程从等待状态切换到就绪状态时(例如,I/O 完成)。
-
当一个进程终止时。
对于第1种和第4种情况,除了调度没有选择。一个新进程(如果就绪队列有一个进程存在)必须被选择执行。不过,对于第2种和第3种情况,还是有选择的。 如果调度只能发生在第1种和第4种情况下,则调度方案称为非抢占的(nnpreemptive)或协作的(cooperative);否则,调度方案称为抢占的(preemptive)。
在非抢占调度下,日某个进程分配到CPU,该进程就会一直使用CPU,直到它终止或切换到等待状态
1.3 调度程序 Dispatcher
Dispatcher module gives control of the CPU to the process selected by the short-term scheduler; this involves:
- switching context
- switching to user mode
- jumping to the proper location in the user program to restart that program
Dispatch latency – time it takes for the dispatcher to stop one process and start another running
调度程序模块将CPU控制权交给短期调度程序选择的进程;这涉及:
- 切换上下文
- 切换到用户模式
- 跳转到用户程序中的适当位置以重新启动该程序
==调度延迟 – 调度程序停止一个进程并开始另一个进程运行所需的时间==
2. 调度准则 Scheduling Criteria
-
CPU utilization(MAX) – keep the CPU as busy as possible
-
Throughput(MAX) – of processes that complete their execution per time unit
-
Turnaround time(MIN) – amount of time to execute a particular process
-
Waiting time(MIN) – amount of time a process has been waiting in the ready queue
-
Response time(MIN) – amount of time it takes from when a request was submitted until the first response is produced, not output (for time-sharing environment)
- CPU 利用率(MAX) – 使 CPU 尽可能保持繁忙
- 吞吐量(MAX) – 每个时间单位完成执行的进程
- 周转时间(MIN) – 从进程提交到进程完成的时间段
- 等待时间(MIN) – 进程在就绪队列中等待的时间量之和
- 响应时间(MIN) – 从提交请求到产生第一个响应所花费的时间,而不是输出(对于分时环境)
3. 调度算法
3.1 先到先服务调度 First- Come, First-Served (FCFS) Scheduling
最简单的CPU调度算法是先到先服务(First-Come First-Served,FCFS)调度算法。
采用这种方案,先请求 CPU 的进程首先分配到 CPU。FCFS 策略可以通过 FIFO队列容易地实现。当一个进程进入就绪队列时,它的PCB 会被链接到队列尾部。当CPU空闲时,它会分配给位于队列头部的进程,并且这个运行进程从队列中移去。FCFS 调度代码维写简单并且理解容易。
FCFS 策略的缺点是,平均等待时间往往很长。假设有如下一组进程,它们在时间0到达,CPU执行长度按ms计:


另外,考虑动态情况下的FCFS 调度性能。2假设有一个CPU密集型进程和多个I/O密集型进程。随着进程在系统中运行,可能发生如下情况:
CPU 密集型进程得到 CPU,并使用它。在这段时间内,所有其他进程会处理完它们的 I/O,并转移到就绪队列来等待 CPU当这些进程在就绪队列中等待时,I/O设备空闲。最终,CPU 密集型进程完成CPU 执行并且移到I/O设备。所有I/0密集型进程,由于只有很短的 CPU 执行,故很快执行完并移回到I/O队列。这时,CPU空闲。之后,CPU密集型进程会移回到就绪队列并分配到CPU.再次,所有I/0进程会在就绪队列中等待 CPU 密集型进程的完成。由于所有其他进程都等待一个大进程释放CPU,故称之为==护航效果==(convoy effect)。与让较短进程先进行相比这会导致CPU和设备的使用率降低。
也要注意,FCFS 调度算法是非抢占的。一旦 CPU 分配给了一个进程,该进程就会使用CPU直到释放CPU为止,即程序终止或是请求I/O。FCFS 算法对于分时系统(每个用户需要定时得到一定的CPU 时间)是特别麻烦的。允许一个进程使用CPU 过长将是个严重错误。
3.2 最短作业优先调度 Shortest-Job-First (SJF) Scheduling
- Associate with each process the length of its next CPU burst
- Use these lengths to schedule the process with the shortest time
- SJF is optimal – gives minimum average waiting time for a given set of processes
- The difficulty is knowing the length of the next CPU request
- Could ask the user
- 与每个进程关联其下一个 CPU 突发的长度
- 使用这些长度以最短的时间安排流程
- SJF 是最优的 – 为给定的一组过程提供最短的平均等待时间
- 困难在于知道下一个 CPU 请求的长度
- 可以询问用户
另一个不同的CPU调度方法是最短作业优先(Shortest-Job-First,SJF)调度算法。这个算法将每个进程与其下次 CPU 执行的长度关联起来。当CPU 变为空闲时,它会被赋给具有最短 CPU 执行的进程。如果两个进程具有同样长度的CPU 执行,那么可以由 FCFS 来处理。注意,一个更为恰当的表示是最短下次CPU 执行(shortest-next-CPU-burst)算法,这是因为调度取决于进程的下次 CPU 执行的长度,而不是其总的长度。我们使用 SJF 一词主要由于大多数教科书和有关人员都这么称呼这种类型的调度策略。作为一个SJF 调度的例子,假设有如下一组进程,CPU 执行长度以ms计


可以证明 SJF 调度算法是最优的。这是因为对于给定的一组进程,SJF 算法的平均等待时间最小。通过将短进程移到长进程之前,短进程的等待时间减少大于长进程的等待时间增加。因而,平均等待时间减少。
SJF 算法的真正困难是如何知道下次 CPU 执行的长度。对于批处理系统的长期(或作业)调度,可以将用户提交作业时指定的进程时限作为长度。在这种情况下,用户有意精确估计进程时间,这是因为低值可能意味着更快的响应(过小的值会引起时限超出错误,进而需要重新提交)。SJF 调度经常用于长期调度。
虽然SJF 算法是最优的,但是它不能在短期CPU 调度级别上加以实现,因为没有办法知道下次 CPU执行的长度。一种方法是试图近似 SJF 度。虽然不知道下一个CPU执行的长度,但是可以预测它。可以认为下一个 CPU 执行的长度与以前的相似。因此,通过计算下一个CPU执行长度的近似值,可以选择具有预测最短 CPU 执行的进程来运行。
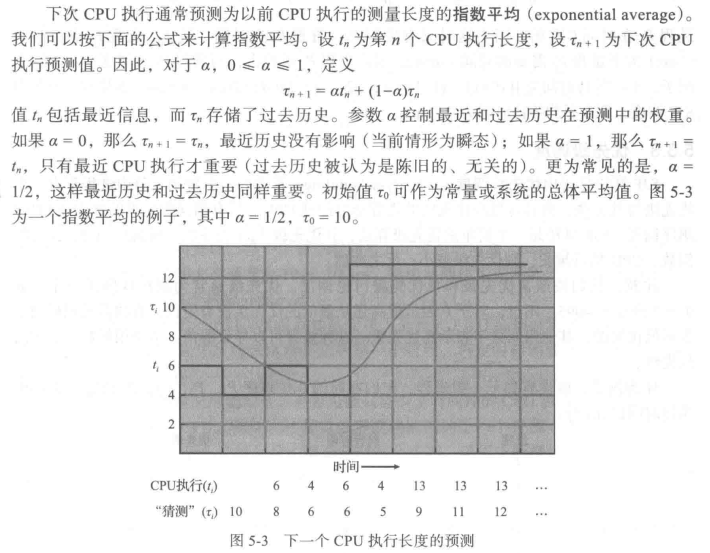
SJF 算法可以是抢占的或非抢占的。当一个新进程到达就绪队列而以前进程正在执行时,就需要选择了。新进程的下次CPU执行,与当前运行进程的尚未完成的CPU执行相比,可能还要小。
-
抢占 SJF 算法会抢占当前运行进程,
-
非抢占 SJF 算法会允许当前运行进程以先完成CPU执行。
抢占SJF 调度有时称为最短剩余时间优先(shortest-remaining-timefirst)调度。


3.3 优先级调度 Priority Scheduling
A priority number (integer) is associated with each process
The CPU is allocated to the process with the highest priority (smallest integer = highest priority)
- Preemptive
- Nonpreemptive
SJF is priority scheduling where priority is the inverse of predicted next CPU burst time
Problem =Starvation – low priority processes may never execute
Solution = Aging – as time progresses increase the priority of the process
优先级数字(整数)与每个进程相关联
CPU 分配给具有最高优先级的进程(最小整数 = 最高优先级)
-
抢占的
-
非抢占的
SJF 是优先级调度,其中优先级是预测的下一个 CPU 突发时间的倒数
问题 =饥饿 – 低优先级进程可能永远不会执行
解决方案 = 老化 – 随着时间的推移,流程的优先级会提高
SJF算法是通用优先级调度(priority-scheduling)算法的一个特例。每个进程都有一个优先级与其关联,而具有最高优先级的进程会分配到 CPU。具有相同优先级的进程按 FCFS顺序调度。SJF 算法是一个简单的优先级算法,其优先级(p) 为下次 (预测的)CPU 执行的倒数。CPU 执行越长,则优先级越小;反之亦然。
注意,我们按照高优先级和低优先级讨论调度。优先级通常为固定区间的数字,如0-7或0~4095。不过,对于0表示最高还是最低的优先级没有定论。有的系统用低数字表示低优先级,其他用低数字表示高优先级。这种差异可以导致混淆。本书用低数字表示高优先级。
作为例子,假设有如下一组进程,它们在时间0按顺序 P,P2,·,P;到达,其CPU执行时间以ms计:
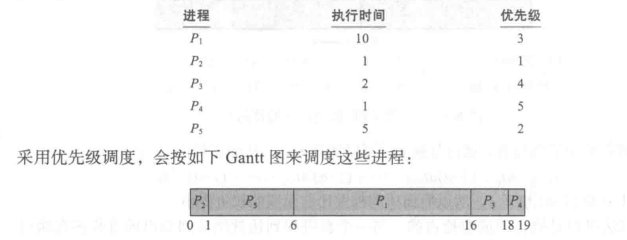

优先调度可以是抢占的或非抢占的。当一个进程到达就绪队列时,比较它的优先级与当前运行进程的优先级。如果新到达进程的优先级高于当前运行进程的优先级,那么抢占优先级调度算法就会抢占 CPU。非抢占优先级调度算法只是将新的进程加到就绪队列的头部。
优先级调度算法的一个主要问题是无穷阻塞(indefinite blocking)或饥饿(starvation)。就绪运行但是等待 CPU的进程可以认为是阻塞的。优先级调度算法可让某个低优先级进程无穷等待CPU。对于一个超载的计算机系统,稳定的更高优先级的进程流可以阻止低优先级的进程获得 CPU。一般来说,有两种情况会发生。要么进程最终会运行(在系统最后为轻负荷时,如星期日凌晨2点),要么系统最终崩溃并失去所有未完成的低优先级进程。(据说,在1973年关闭MIT的IBM 7094时,发现有一个低优先级进早在1967年就已提交但是一直未能运行。) 低优先级进程的无穷等待问题的解决方案之一是老化(aging)。老化逐渐增加在系统中等待很长时间的进程的优先级。例如,如果优先级为从 127(低)到0(高),那可以每15分钟递减等待进程的优先级的值。最终初始优先级值为 127 的进程会有系统内最高的优先级,进而能够执行。事实上,不会超过 32小时,优先级为127 的进程会老化为优先级为0的进程。
3.4 轮转调度 Round Robin (RR)
轮转(Round-Robin,RR)调度算法是专门为分时系统设计的。它类似于FCFS 调度但是增加了抢占以切换进程。将一个较小时间单元定义为时间量 (time quantum)或时间片(time slice)。时间片的大小通常为10~100s。就绪队列作为循环队列。CPU调度程序循环整个就绪队列,为每个进程分配不超过一个时间片的 CPU。 为了实现 RR 调度,我们再次将就绪队列视为进程的 FIFO 队列。新进程添加到就绪队列的尾部。CPU 调度程序从就绪队列中选择第一个进程,将定时器设置在一个时间片后中断,最后分派这个进程。 接下来,有两种情况可能发生。
-
进程可能只需少于时间片的 CPU执行。对于这种情况进程本身会自动释放 CPU。调度程序接着处理就绪队列的下一个进程。
-
否则,如果当前运行进程的 CPU 执行大于一个时间片,那么定时器会中断,进而中断操作系统。然后,进行上下文切换,再将进程加到就绪队列的尾部,接着 CPU 调度程序会选择就绪队列内的下一个进程。
在RR调度算法中,没有进程被连续分配超过一个时间片的CPU(除非它是唯一可运行的进程)。如果进程的CPU 执行超过一个时间片,那么该进程会被抢占,并被放回到就绪队列。因此,RR 调度算法是抢占的。
如果就绪队列有n个进程,并且时间片为q,那么每个进程会得到1/n的CPU 时间,而且每次分得的时间不超过q个时间单元。每个进程等待获得下一个CPU 时间片的时间不会超过(n-1)q 个时间单元。例如,如果有 5个进程,并且时间片为20ms,那么每个进程每100ms会得到不超过20ms的时间。
RR 算法的性能很大程度取决于时间片的大小:
-
在一种极端情况下,如果时间片很大,那么RR算法与FCFS算法一样。
-
相反,如果时间片很小(如1ms),那么RR算法可以导致大量的上下文切换。
例如,假设我们只有一个需要 10 个时间单元的进程。如果时间片为 12个时间单元,那么进程在一个时间片不到就能完成,而且没有额外开销。如果时间片为 6个时间单元,那么进程需要 2 个时间片,并且还有一个上下文切换。如果时间片为 1个时间单元,那么就会有9个上下文切换,相应地使进程执行更慢(图 5-4)。
因此,我们希望时间片远大于上下文切换时间。
Each process gets a small unit of CPU time (time quantum q), usually 10-100 milliseconds. After this time has elapsed, the process is preempted and added to the end of the ready queue.
If there are n processes in the ready queue and the time quantum is q, then each process gets 1/n of the CPU time in chunks of at most q time units at once. No process waits more than (n-1)q time units.
Timer interrupts every quantum to schedule next process Performance
-
q large -> FIFO
-
q small -> q must be large with respect to context switch,
-
otherwise overhead is too high
每个进程获得一个小单位的 CPU 时间(时间量子 q),通常为 10-100 毫秒。经过此时间后,进程将被抢占并添加到就绪队列的末尾。
如果就绪队列中有 n 个进程,并且时间量程为 q,则每个进程一次获得 1/n 的 CPU 时间,以最多 q 个时间单位的块为单位。没有进程等待比 (n-1)q 多的时间单位。
计时器中断每个量程以安排下一个进程性能
-
q 大 -> 先进先出
-
q 小 -> q 在上下文切换方面必须很大,
-
否则开销太高
3.5 多级队列调度 Multilevel Queue
Ready queue is partitioned into separate queues, eg:
- foreground (interactive)
- background (batch)
Process permanently in a given queue
Each queue has its own scheduling algorithm:
- foreground – RR
- background – FCFS
Scheduling must be done between the queues:
- Fixed priority scheduling; (i.e., serve all from foreground then from background). Possibility of starvation.
- Time slice – each queue gets a certain amount of CPU time which it can schedule amongst its processes; i.e., 80% to foreground in RR
- 20% to background in FCFS
就绪队列被分区为单独的队列,例如:
- 前台进程(交互式)
- 后台进程(批处理)
在给定队列中永久处理
每个队列都有自己的调度算法:
- 前台进程 – RR
- 后台进程 - FCFS
必须在队列之间完成调度:
- 固定优先级调度;(即,从前台进程然后从后台进程服务所有内容)。饥饿的可能性。
- 时间片 – 每个队列都有一定的 CPU 时间,它可以在其进程中调度;即,RR 中的前景为 80%
- 20%的背景在FCFS中
3.6 多级反馈队列调度 Multilevel Feedback Queue
A process can move between the various queues; aging can be implemented this way
Multilevel-feedback-queue scheduler defined by the following parameters:
- number of queues
- scheduling algorithms for each queue
- method used to determine when to upgrade a process
- method used to determine when to demote a process
- method used to determine which queue a process will enter when that process needs service
进程可以在各个队列之间移动;老化可以通过这种方式实现
由以下参数定义的多级反馈队列调度程序:
- 队列数量
- 每个队列的调度算法
- 用于确定何时升级进程的方法
- 用于确定何时降级进程的方法
- 用于确定进程在需要服务时将进入哪个队列的方法
多级反馈队列(multilevel feedback queue)调度算法允许进程在队列之间迁移。这种想法是,根据不同CPU 执行的特点来区分进程。如果进程使用过多的 CPU时间,那么它会被移到更低的优先级队列。这种方案将 I/O 密集型和交互进程放在更高优先级队列上。此外,在较低优先级队列中等待过长的进程会被移到更高优先级队列。这种形式的老化阻止饥饿的发生。
通常,多级反馈队列调度程序可由下列参数来定义:
- 队列数量。
- 每个队列的调度算法。
- 用以确定何时升级到更高优先级队列的方法
- 用以确定何时降级到更低优先级队列的方法。
- 用以确定进程在需要服务时将会进人哪个队列的方法。
多级反馈队列调度程序的定义使其成为最通用的CPU调度算法。通过配置,它能适应所设计的特定系统。遗憾的是,由于需要一些方法来选择参数以定义最佳的调度程序,所以它也是最复杂的算法。
4. 线程调度 Thread Scheduling
第4章为进程模型引人了线程,还比较了用户级(user-level)和内核级(kernel-level)的线程。在支持线程的操作系统上,内核级线程(而不是进程)才是操作系统所调度的。用户级线程是由线程库来管理的,而内核并不知道它们。用户级线程为了运行在CPU上最终应映射到相关的内核级线程,但是这种映射可能不是直接的,可能采用轻量级进程(LWP)。本节探讨有关用户级和内核级线程的调度,并提供 Pthreads 调度的具体实例。
LWP为用户级线程和内核级线程之间的中间层。
4.1 竞争范围
用户级和内核级线程之间的一个区别在于它们是如何调度的。
对于实现多对一(4.3.1节)和多对多(4.3.3 节)模型的系统线库会调度用户级线程,以便在可用LWP上运行。这种方案称为进程竞争范围(Process-Contention Scope,PCS),因为竞争CPU是发生在同一进程的线程之间。(当我们说线程库将用户线程调度到可用LWP 时,并不意味着线程真实运行在一个CPU上。这会需要操作系统调度内核线程到物理CPU。为了决定哪个内核级线程调度到一个处理器上,内核采用系统竞争范围 (System-Contention Scope,SCS)。采用SCS调度来竞争 CPU,发生在系统内的所有线程之间。采用一对一模型(4.3.2节)的系统,如Windows、Linux 和Solaris,只采用SCS调度。 通常情况下,PCS 采用优先级调度,即调度程序选择运行具有最高优先级的、可运行的线程。用户级线程的优先级是由程序员设置的,并不是由线程库调整的,尽管有些线程库可能允许程序员改变线程的优先级。重要的是,要注意到 PCS 通常允许一个更高优先级的线程来抢占当前运行的线程:不过,在具有相同优先级的线程之间,没有时间分片的保证(5.3.4 节)。
- Distinction between user-level and kernel-level threads
- When threads supported, threads scheduled, not processes
- Many-to-one and many-to-many models, thread library schedules user-level threads to run on LWP
- Known as process-contention scope (PCS) since scheduling competition is within the process
- Typically done via priority set by programmer
-
Kernel thread scheduled onto available CPU is system-contention scope (SCS) – competition among all threads in system
- 区分用户级和内核级线程
- 当支持线程时,调度线程,而不是进程
- 多对一和多对多模型,线程库调度用户级线程在 LWP 上运行
- 称为进程争用范围 (PCS),因为调度竞争在进程内
- 通常通过程序员设置的优先级来完成
- 调度到可用 CPU 的内核线程是系统争用范围 (SCS) – 系统中所有线程之间的竞争
4.2 Pthreads调度 Pthread Scheduling
API allows specifying either PCS or SCS during thread creation
- PTHREAD_SCOPE_PROCESS schedules threads using PCS scheduling
- PTHREAD_SCOPE_SYSTEM schedules threads using SCS scheduling
Can be limited by OS – Linux and Mac OS X only allow PTHREAD_SCOPE_SYSTEM
Multiple-Processor Scheduling
(了解即可)
-
CPU scheduling more complex when multiple CPUs are available
-
Homogeneous processors within a multiprocessor
-
Asymmetric multiprocessing – only one processor accesses the system data structures, alleviating the need for data sharing
- Symmetric multiprocessing (SMP) – each processor is selfscheduling, all processes in common ready queue, or each has its own private queue of ready processes
- Currently, most common
- Processor affinity – process has affinity for processor on which it is currently running
- soft affinity
- hard affinity
- Variations including processor sets
-
当多个 CPU 可用时,CPU 调度更复杂
-
多处理器内的同构处理器
-
非对称多处理 – 只有一个处理器访问系统数据结构,减轻了数据共享的需求
- 对称多处理 (SMP) – 每个处理器都是自调度的,所有进程都在公共就绪队列中,或者每个进程都有自己的就绪进程专用队列
- 目前最常见的
- 处理器关联 – 进程与当前正在运行的处理器具有关联
- 软亲和力
- 硬亲和力
- 包括处理器组在内的变体
ch5 的 PPT 最后有一个课堂题比较经典可以看看。