Processes
1. 进程概念 Process Concept
1.1 进程
Process – a program in execution; process execution must progress in sequential fashion
Multiple parts:
- The program code, also called text section
- Current activity including program counter, processor registers
- Stack containing temporary data
- Function parameters, return addresses, local variables
- Data section containing global variables
- Heap containing memory dynamically allocated during run time
Program is passive entity stored on disk (executable file), process is active
- Program becomes process when executable file loaded into memory
Execution of program started via GUI mouse clicks, command line entry of its name, etc
One program can be several processes
- Consider multiple users executing the same program
进程 – 正在执行的程序;进程执行必须按顺序进行(进程和作业两个概念是一样的)
多个部分:
- 程序代码,也称为文本部分
- 当前活动,包括程序计数器、处理器寄存器
- 包含临时数据的堆栈
- 函数参数、返回地址、局部变量
- 包含全局变量的数据部分
- 包含运行时动态分配的内存的堆
程序是存储在磁盘上的被动实体(可执行文件),进程是活动实体
- 当可执行文件加载到内存中时,程序变为进程
通过GUI鼠标单击,命令行输入其名称等启动程序的执行
-
一个程序可以是多个进程:
虽然两个进程可以与同一程序相关联,但是当作两个单独的执行序列。例如,多个用户可以运行电子邮件的不同副本,或者同一用户可以调用 Web 浏览器程序的多个副本。每个都是单独进程:虽然文本段相同,但是数据、堆及堆栈段却不同。进程在运行时也经常会生成许多进程。3.4 节将讨论这些问题。
-
考虑多个用户执行同一个程序
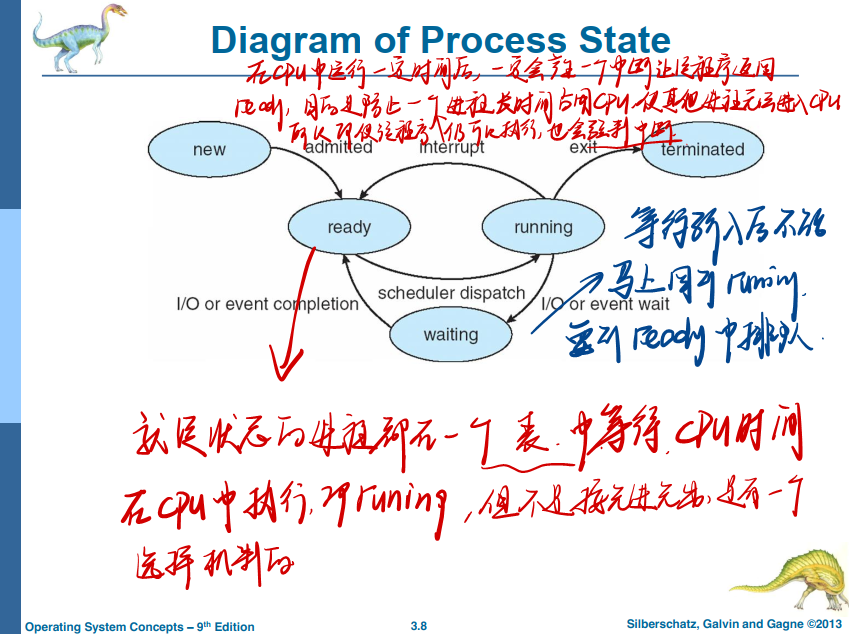
1.2 进程状态 Process State
As a process executes, it changes state
- new: The process is being created
- running: Instructions are being executed
- waiting: The process is waiting for some event to occur
- ready: The process is waiting to be assigned to a processor
- terminated: The process has finished execution
当进程执行时,它会更改状态
- 新的(new):正在创建进程
- 运行(running):正在执行指令
- 等待(waiting):进程正在等待某些事件发生
- 就绪(ready):进程正在等待分配给处理器
- 终止(terminated):进程已完成执行
1.3 进程控制块 Process Control Block (PCB)
如果没有PCB,将无法将进程调入到CPU中。
操作系统感知进程的唯一方式(PCB是进程的身份证)
Information associated with each process (also called task control block)
- Process state – running, waiting, etc
- Program counter – location of instruction to next execute
- CPU registers – contents of all processcentric registers
- CPU scheduling information- priorities, scheduling queue pointers
- Memory-management information – memory allocated to the process
- Accounting information – CPU used, clock time elapsed since start, time limits
- I/O status information – I/O devices allocated to process, list of open files

与每个进程关联的信息(也称为任务控制块),PCB就是下列信息的仓库
- 进程状态 – 正在运行、等待等
- 程序计数器PC - 下次执行的指令位置
- CPU 寄存器 – 所有以进程为中心的寄存器的内容
- CPU调度信息 - 优先级,调度队列指针
- 内存管理信息 – 分配给进程的内存
- 记帐信息 – 使用的 CPU、启动以来经过的时钟时间、时间限制
- I/O 状态信息 – 分配给进程的 I/O 设备、打开的文件列表
1.4 线程 Threads
So far, process has a single thread of execution Consider having multiple program counters per process
- Multiple locations can execute at once
- Multiple threads of control -> threads
- Must then have storage for thread details, multiple program counters in PCB
See next chapter
到目前为止,进程只有一个执行线程 考虑每个进程有多个程序计数器
- 多个位置可以一次执行
- 控制多线程 - >线程
- 然后必须存储线程详细信息,PCB中的多个程序计数器
请参阅下一章
2. 进程调度 Process Scheduling
Maximize CPU use, quickly switch processes onto CPU for time sharing
- Process scheduler selects among available processes for next execution on CPU
- Maintains scheduling queues of processes
- Job queue – set of all processes in the system
- Ready queue – set of all processes residing in main memory, ready and waiting to execute
- Device queues – set of processes waiting for an I/O device Processes migrate among the various queues
最大化 CPU 利用率,快速将进程切换到 CPU 上以进行分时
- 进程调度程序在可用进程中选择下一次在 CPU 上执行
- 维护进程的调度队列
- 作业队列 – 系统中所有进程的集合
- 就绪队列 – 驻留在主内存中的所有进程的集合,准备就绪并等待执行
- 设备队列 – 等待 I/O 设备的进程集 进程在各种队列之间迁移 (迁移:如一个进程已经进入到CPU开始运行,但若此时要读入数据,则又要到磁盘队列,读取完毕后再进入就绪队列等待进入CPU,然后又可能进入其他调度队列)
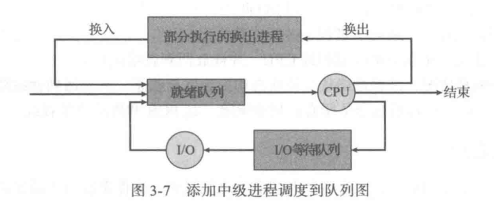
进程调度通常用队列图来表示:
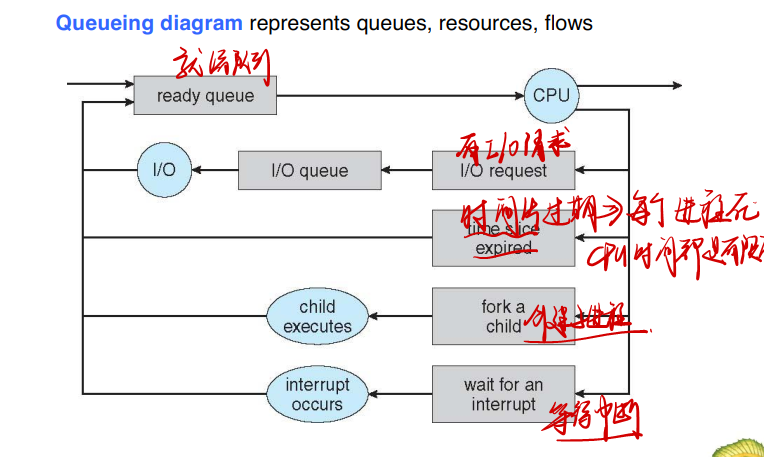
最初,新进程被加到就绪队列;它在就绪队列中等待,直到被选中执行或被分派(dispatched)。当该进程分配到 CPU并执行时,以下事件可能发生: 进程可能发出 I/O 请求,并被放到I/O 队列。 。进程可能创建一个新的子进程,并等待其终止。 。进程可能由于中断而被强制释放 CPU,并被放回到就绪队列。 对于前面两种情况,进程最终从等待状态切换到就绪状态,并放回到就绪队列。进程重复这一循环直到终止;然后它会从所有队列中删除,其 PCB 和资源也被释放。
2.1 调度程序 Schedulers
-
Short-term scheduler (or CPU scheduler) – selects which process should be executed next and allocates CPU
- Sometimes the only scheduler in a system
- Short-term scheduler is invoked frequently (milliseconds) (must be fast)
-
Long-term scheduler (or job scheduler) – selects which processes should be brought into the ready queue
- Long-term scheduler is invoked infrequently (seconds, minutes) -> (may be slow)
- The long-term scheduler controls the degree of multiprogramming
-
Processes can be described as either:
- I/O-bound process – spends more time doing I/O than computations, many short CPU bursts
- CPU-bound process – spends more time doing computations; few very long CPU bursts
-
Long-term scheduler strives for good process mix
-
Medium-term scheduler can be added if degree of multiple programming needs to decrease
- Remove process from memory, store on disk, bring back in from disk to continue execution: swapping
- 短程调度程序(或 CPU 调度程序) – 从ready队列选择下一个应执行的进程并分配 CPU
- 有时是系统中唯一的调度程序
- 频繁调用短期调度程序(毫秒)->(必须快速)
- 长程调度程序(或作业调度程序) – 选择应将哪些进程进入ready队列
- 长程调度程序不经常调用(秒、分钟)->(可能很慢)
- 长程调度程序控制多道程序程度(内存中进程的数量)
- 流程可以描述为:
- I/O 绑定进程 – 花费更多的时间进行 I/O 而不是计算,许多短 CPU 突发
- CPU 密集型进程 – 花费更多时间进行计算;很少有很长的 CPU 突发
- 如果需要降低多道程序程度,可以添加中程调度程序(系统资源不支持那么多进程同时运行)
- 从内存中删除进程,存储在磁盘上(换出),从磁盘恢复并从中断处继续执行(换入),这种方案称为:交换
2.2 Multitasking in Mobile Systems
(课本3.2.3 P78)
Some mobile systems (e.g., early version of iOS) allow only one process to run, others suspended
Due to screen real estate, user interface limits iOS provides for a
- Single foreground process- controlled via user interface
- Multiple background processes– in memory, running, but not on the display, and with limits
- Limits include single, short task, receiving notification of events, specific long-running tasks like audio playback
Android runs foreground and background, with fewer limits
- Background process uses a service to perform tasks
- Service can keep running even if background process is suspended
- Service has no user interface, small memory use
一些移动系统(例如,iOS的早期版本)只允许运行一个进程,其他系统则暂停
由于屏幕空间,iOS提供的用户界面限制
- 单一前台过程 - 通过用户界面控制
- 多个后台进程 - 在内存中,正在运行,但不在显示器上,并且有限制
- 限制包括单个、短任务、接收事件通知、特定的长时间运行任务(如音频播放)
Android 运行前台和后台,限制更少
- 后台进程使用服务执行任务
- 即使后台进程挂起,服务也可以继续运行
- 服务没有用户界面,内存使用量小
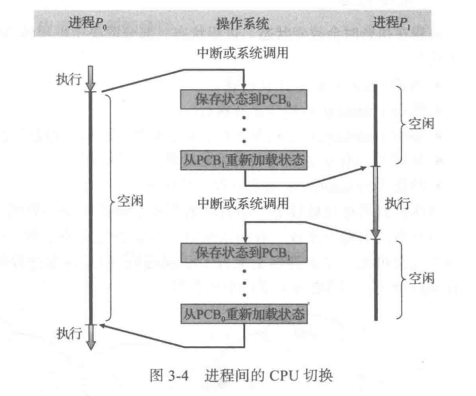
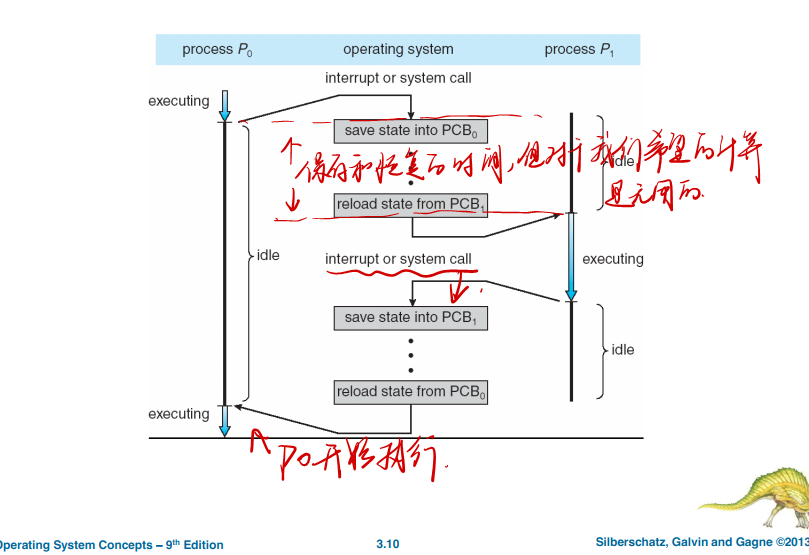
2.3 上下文切换 Context Switch
正如 1.2.1节所提到的,中断导致 CPU 从执行当前任务改变到执行内核程序。这种操作在通用系统中经常发生。当中断发生时,系统需要保存当前运行在CPU 上的进程的上下文以便在处理后能够恢复上下文,即先挂起进程,再恢复进程。进程上下文采用进程 PCB 表示,包括 CPU寄存器的值、进程状态(图3-2)和内存管理信息等。通常,通过执行状态保存(state save),保存CPU 当前状态(包括内核模式和用户模式);之后,状态恢复(staterestore)重新开始运行。 切换 CPU到另一个进程需要保存当前进程状态和恢复另一个进程的状态,这个任务称为上下文切换(context switch)。当进行上下文切换时,内核会将旧进程状态保存在其 PCB中,然后加载经调度而要执行的新进程的上下文。上下文切换的时间是纯粹的开销,因为在切换时系统并没有做任何有用工作。上下文切换的速度因机器不同而有所不同,它依赖于内存速度、必须复制的寄存器数量、是否有特殊指令(如加载或存储所有寄存器的单个指令)。典型速度为几毫秒。
When CPU switches to another process, the system must save the state of the old process and load the saved state for the new process via a context switch
- Context of a process represented in the PCB
- Context-switch time is overhead; the system does no useful work while switching
- The more complex the OS and the PCB ➔ the longer the context switch
- Time dependent on hardware support
- Some hardware provides multiple sets of registers per CPU ➔ multiple contexts loaded at once
当 CPU 切换到另一个进程时,系统必须保存旧进程的状态,并通过上下文切换加载新进程的保存状态
- 进程的内容保存在PCB中
- 上下文切换时间是开销;切换时系统不做任何有用的工作
- 操作系统和PCB越复杂➔上下文切换越长
- 时间取决于硬件支持
- 某些硬件为每个 CPU 提供多组寄存器 ➔ 一次加载多个上下文
3. 进程运行 Operations on Processes
System must provide mechanisms for:
- process creation,
- process termination,
- and so on as detailed next
系统必须提供以下机制:
- 进程创建,
- 进程终止,
- 以此类推,详见下文
3.1 进程的创建 Process Creation
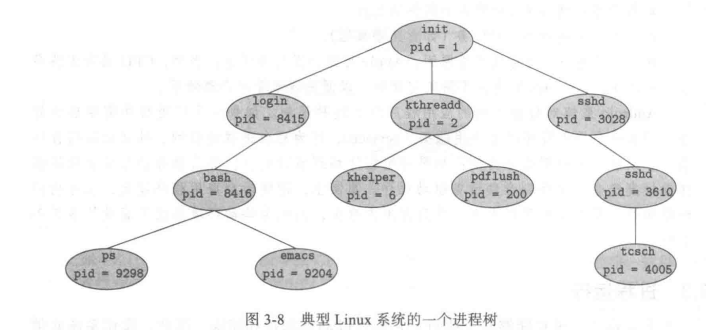
Parent process create children processes, which, in turn create other processes, forming a tree of processes
Generally, process identified and managed via a process identifier (pid)
Resource sharing options
- Parent and children share all resources
- Children share subset of parent’s resources
- Parent and child share no resources
Execution options
- Parent and children execute concurrently
- Parent waits until children terminate
执行选项
-
父子并发执行
-
父母等到孩子终止
资源共享选项
- 亲子共享所有资源
- 孩子们分享父母资源的子集
- 父子不共享资源
一般来说,当一个进程创建子进程时,该子进程会需要一定的资源(CPU 时间、内存文件、I/O 设备等)来完成任务。子进程可以从操作系统那里直接获得资源,也可以只从父进程那里获得资源子集。父进程可能要在子进程之间分配资源或共享资源(如内存或文件)。限制子进程只能使用父进程的资源,可以防止创建过多进程,导致系统超载。
除了提供各种物理和逻辑资源外,父进程也可能向子进程传递初始化数据(或输入)
父进程创建子进程,子进程又创建其他进程,形成进程树,通常,进程通过进程标识符 (pid) 标识和管理(pid是识别进程唯一方式)
当进程创建新进程时,可有两种执行可能:
- 父进程与子进程并发执行。
- 父进程等待,直到某个或全部子进程执行完新进程的地址空间也有两种可能:
新进程的地址空间也有两种可能
-
子进程是父进程的复制品(它具有与父进程同样的程序和数据)
-
子进程加载另一个新程序。
3.2 进程终止 Process Termination
- Process executes last statement and then asks the operating system to delete it using the exit() system call.
- Returns status data from child to parent (via wait())
- Process’ resources are deallocated by operating system
- Parent may terminate the execution of children processes using the abort() system call. Some reasons for doing so:
- Child has exceeded allocated resources
- Task assigned to child is no longer required
- The parent is exiting and the operating systems does not allow a child to continue if its parent terminates
Some operating systems do not allow child to exists if its parent has terminated. If a process terminates, then all its children must also be terminated.
- cascading termination. All children, grandchildren, etc. are terminated.
- The termination is initiated by the operating system.
The parent process may wait for termination of a child process by using the wait()system call. The call returns status information and the pid of the terminated process
pid = wait(&status);
- If no parent waiting (did not invoke
wait()) process is a zombie - If parent terminated without invoking
wait, process is an orphan
进程执行最后一条语句,然后使用 exit() 系统调用要求操作系统删除它。
- 将状态数据从孩子返回给父母(通过 wait())
- 进程的资源由操作系统释放
父进程可以使用 abort() 系统调用终止子进程的执行。这样做的一些原因:
- 孩子已经超出了分配的资源
- 不再需要分配给孩子的任务
- 父进程正在退出,操作系统不允许子进程在其父进程终止时继续运行
如果其父进程已终止,则某些操作系统不允许子进程存在。如果一个父进程终止,那么它的所有子进程也必须终止,这种情况叫级联终止
- 级联终止。所有的孩子、孙子等都被终止了。
- 终止由操作系统发起。
父进程可以使用 wait() 系统调用等待子进程的终止。该调用返回状态信息和已终止进程的 pid
pid = wait(&status);
系统调用 wait()可以通过参数,让父进程获得子进程的退出状态;这个系统调用也返回终止子进程的标识符,这样父进程能够知道哪个子进程已经终止了;
当一个进程终止时,操作系统会释放其资源。不过,它位于进程表中的条目还是在的直到它的父进程调用 wait();这是因为进程表包含了进程的退出状态。
-
当进程已经终止但是其父进程尚未调用wait(),这样的进程称为僵尸进程(zombie process)。所有进程终止时都会过渡到这种状态,但是一般而言僵尸只是短暂存在。一旦父进程调用了 wait(),僵尸进程的进程标识符和它在进程表中的条目就会释放。
-
如果父进程没有调用 wait()就终止,以致于子进程成为孤儿进程(orphan process)
3.3 Multiprocess Architecture – Chrome Browse
Many web browsers ran as single process (some still do)
If one web site causes trouble, entire browser can hang or crashGoogle Chrome Browser is multiprocess with 3 different types of processes:
- Browser process manages user interface, disk and network I/O
- Renderer process renders web pages, deals with HTML, Javascript. A new renderer created for each website opened
- Runs in sandbox restricting disk and network I/O, minimizing effect of security exploits
- Plug-in process for each type of plug-in
许多Web浏览器作为单个进程运行(有些仍然如此)
如果一个网站引起麻烦,整个浏览器可能会挂起或崩溃谷歌Chrome浏览器是多进程的,有3种不同类型的进程:
- 浏览器进程管理用户界面、磁盘和网络 I/O
- 渲染器进程渲染网页,处理HTML,Javascript。为每个打开的网站创建一个新的呈现器
- 在沙盒中运行,限制磁盘和网络 I/O,最大限度地减少安全漏洞的影响
- 每种插件的插件过程

4. 进程间通信 Interprocess Communication
Processes within a system may be independent or cooperating
Cooperating process can affect or be affected by other processes, including sharing data
Reasons for cooperating processes:
- Information sharing
- Computation speedup
- Modularity
- Convenience
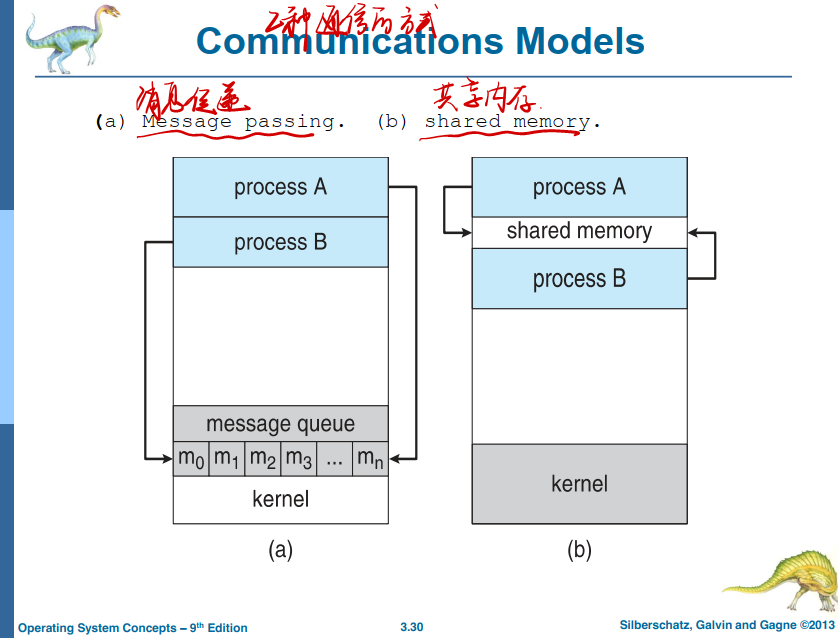
Cooperating processes need interprocess communication (IPC)
- Two models of IPC
- Shared memory
- Message passing
系统内的流程可以是独立的,也可以是协作的
合作过程可能会影响其他过程或受其他过程的影响,包括共享数据
合作进程的原因:
- 信息共享
- 计算加速
- 模块性
- 方便
协作进程需要进程间通信 (IPC)
- 两种IPC模型
- 共享内存
- 消息传递
4.1 进程协作 Cooperating Processes
Independent process cannot affect or be affected by the execution of another process
Cooperating process can affect or be affected by the execution of another process
Advantages of process cooperation
- Information sharing
- Computation speed-up
- Modularity
- Convenience
独立进程不能影响或受另一个进程的执行影响
协作进程可以影响或受另一个过程的执行的影响
进程协作的优势
- 信息共享
- 计算加速
- 模块性
- 方便
4.2 Producer-Consumer Problem (解释协作进程为什么要共享)
生产者-消费者问题,这是协作进程的通用范例。 生产者(producer)进程生成信息,以供消费者(consumer)进程消费。例如,编译器生成的汇编代码可供汇编程序使用,而且汇编程序又可生成目标模块以供加载程序使用。生产者-消费者问题同时还为客户机-服务器范例提供了有用的比喻。通常,将服务器当作生产者,而将客户机当作消费者。例如,一个 Web 服务器生成(提供)HTML 文件和图像,以供请求资源的 Web 客户浏览器使用(读取)。
解决生产者 -消费者问题的方法之一是,采用共享内存。为了允许生产者进程和消费者进程并发执行,应有一个可用的缓冲区,以被生产者填充和被消费者清空。这个缓冲区驻留在生产者进程和消费者进程的共享内存区域内。当消费者使用一项时,生产者可产生另一项。生产者和消费者必须同步,这样消费者不会试图消费一个尚未生产出来的项。
缓冲区类型可分两种。
- 无界缓冲区(unbounded-buffer)没有限制缓冲区的大小。消费者可能不得不等待新的项,但生产者总是可以产生新项。
- 有界缓冲区(bounded-buffer)假设固定大小的缓冲区。对于这种情况,如果缓冲区空,那么消费者必须等待;并且如果缓冲区满,那么生产者必须等待。
Paradigm for cooperating processes, producer processproduces information that is consumed by a consumer process
- unbounded-buffer places no practical limit on the size of the buffer
- bounded-buffer assumes that there is a fixed buffer size
协作进程的范式,生产者过程产生消费者消费的信息过程
- 无界缓冲区对缓冲区的大小没有实际限制
- 有界缓冲区假定存在固定的缓冲区大小
(有代码,在书的3.4.1 P86,PPT在3.31)
4.3 共享内存 Shared Memory
- An area of memory shared among the processes that wish to communicate
- The communication is under the control of the users processes not the operating system.
- Major issues is to provide mechanism that will allow the user processes to synchronize their actions when they access shared memory.
-
Synchronization is discussed in great details in Chapter 5
- 在希望通信的进程之间共享的内存区域
- 通信由用户进程控制,而不是操作系统。
- 主要问题是提供允许用户进程在访问共享内存时同步其操作的机制。
- 同步在第 5 章中详细讨论
4.4 消息传递 Message Passing
- Mechanism for processes to communicate and to synchronize their actions
- Message system – processes communicate with each other without resorting to shared variables
- IPC facility provides two operations:
- send(message)
- receive(message)
-
The message size is either fixed or variable
- If processes P and Q wish to communicate, they need to:
- Establish a communication link between them
- Exchange messages via send/receive
- Implementation issues:
- How are links established?
- Can a link be associated with more than two processes?
- How many links can there be between every pair of communicating processes?
- What is the capacity of a link?
- Is the size of a message that the link can accommodate fixed or variable?
- Is a link unidirectional or bi-directional?
- Implementation of communication link
- Physical:
- Shared memory
- Hardware bus
- Network
- Logical:
- Direct or indirect
- Synchronous or asynchronous
- Automatic or explicit buffering
- Physical:
- 进程通信和同步他们的行动的机制
- 消息系统——进程之间无需借助共享变量即可相互通信
- IPC 设施提供两种操作:
- 发送信息
- 接收(消息)
-
消息大小是固定的或可变的
- 如果进程 P 和 Q 希望进行通信,他们需要:
- 在它们之间建立通信链接
- 通过发送/接收交换信息
- 实施问题:
- 链接是如何建立的?
- 一个链接可以与两个以上的进程相关联吗?
- 每对通信进程之间可以有多少个链接?
- 链接的容量是多少?
- 链接可以容纳的消息大小是固定的还是可变的?
- 链接是单向的还是双向的?
- 通信链路的实现
- 物理上:
- 共享内存
- 硬件总线
- 网络
- 逻辑上:
- 直接或间接
- 同步或异步
- 自动或显式缓冲
- 物理上:
以下研究逻辑上这3个问题:
4.4.1 命名–直接通信和间接通信
Direct Communication
对于直接通信(direct communication)需要通信的每个进程必须明确指定通信的接收者或发送者。采用这种方案,原语 send()和receive()定义如下:
- send(P,message): 向进程P发送message。
- receive(Q,message): 从进程Q接收 message。
这种方案的通信链路具有以下属性:
- 在需要通信的每对进程之间,自动建立链路。进程仅需知道对方身份就可进行交流。
- 每个链路只与两个进程相关
- 每对进程之间只有一个链路。
这种方案展示了寻址的对称性(symmetry),即发送和接收进程必须指定对方,以便通信。这种方案的一个变形采用寻址的非对称性(asymmetry),即只要发送者指定接收者,而接收者不需要指定发送者。采用这种方案,原语 send()和 receive()的定义如下:
- send(P,message):向进程P 发送message。
- receive(id,message):从任何进程,接收message,
这里变量id 被设置成与其通信进程的名称。 这两个方案(对称和非对称的寻址)的缺点是:生成进程定义的有限模块化。更改进程的标识符可能需要分析所有其他进程定义。所有旧的标识符的引用都应找到,以便修改成为新标识符。通常,任何这样的硬编码(hard-coding)技术(其中标识符需要明确指定),与下面所述的采用间接的技术相比要差。
Processes must name each other explicitly:
- send (P, message) – send a message to process P
- receive(Q, message) – receive a message from process Q
Properties of communication link
- Links are established automatically
- A link is associated with exactly one pair of communicating processes
- Between each pair there exists exactly one link
- The link may be unidirectional, but is usually bi-directional
进程必须显式命名:
- send (P, message)– 向进程 P 发送消息
- receive(Q, message) – 从进程 Q 接收消息
通信链路的属性
- 在需要通信的每对进程之间自动建立链路。进程只需要知道对方身份就可以交流
- 一个链接只与一对通信进程相关联
- 每对之间正好存在一个链接
- 链接可能是单向的,但通常是双向的
Indirect Communication
在间接通信(indirect communication)中,通过邮箱或端口来发送和接收消息。邮箱可以抽象成一个对象,讲程可以向其中存放消息,也可从中删除消自,每个邮箱都有一个唯一的标识符。例如,POSIX 消息队列采用一个整数值来标识一个邮箱。一个进程可以通过多个不同邮箱与另一个进程通信,但是两个进程只有拥有一个共享邮箱时才能通信。原语send()和receive()定义如下:
- send(A,message):向邮箱A发送message。
- receive(A,message); 从邮箱A接收message。
对于这种方案,通信链路具有如下特点:
- 只有在两个进程共享一个邮箱时,才能建立通信链路
- 一个链路可以与两个或更多进程相关联。
- 两个通信进程之间可有多个不同链路,每个链路对应于一个邮箱。
现在假设进程P、P和P;都共享邮箱A。进程P发送一个消息到A,而进程P和P都对A 执行 receive()。哪个进程会收到 P发送的消息?答案取决于所选择的方案:
- 允许一个链路最多只能与两个进程关联。
- 允许一次最多一个进程执行操作 receive()
- 允许系统随意选择一个进程以便接收消息(即进程P和 P两者之一都可以接收消息,但不能两个都可以)。系统同样可以定义一个算法来选择哪个进程是接收者(如轮转,进程轮流接收消息)。系统可以让发送者指定接收者。
邮箱可以为进程或操作系统拥有。如果邮箱为进程拥有(即邮箱是进程地址空间的一部分),那么需要区分所有者(只能从邮箱接收消息)和使用者(只能向邮箱发送消息)。由于每个邮箱都有唯一的标识符,所以关于谁能接收发到邮箱的消息没有任何疑问。当拥有邮箱的进程终止,那么邮箱消失。任何进程后来向该邮箱发送消息,都会得知邮箱不再存在。
与此相反,操作系统拥有的邮箱是独立存在的;它不属于某个特定进程。因此,操作系统必须提供机制,以便允许进程进行如下操作:
- 创建新的邮箱。
- 通过邮箱发送和接收消息。
- 删除邮箱
Messages are directed and received from mailboxes (also referred to as ports)
- Each mailbox has a unique id
- Processes can communicate only if they share a mailbox
Properties of communication link
- Link established only if processes share a common mailbox
- A link may be associated with many processes
- Each pair of processes may share several communication links
- Link may be unidirectional or bi-directional
Operations
- create a new mailbox (port)
- send and receive messages through mailbox
- destroy a mailbox
Primitives are defined as:
- send(A, message) – send a message to mailbox A
- receive(A, message) – receive a message from mailbox A
Mailbox sharing
- P1, P2, and P3 share mailbox A
- P1, sends; P2 and P3 receive
- Who gets the message?
Solutions
- Allow a link to be associated with at most two processes
- Allow only one process at a time to execute a receive operation
- Allow the system to select arbitrarily the receiver.
- Sender is notified who the receiver was.
从邮箱(也称为端口)定向和接收邮件
- 每个邮箱都有一个唯一的ID
- 进程只有在共享邮箱时才能通信
通信链路的属性
- 仅当进程共享公共邮箱时才建立链接
- 一个链接可能与许多进程相关联
- 每对进程可以共享多个通信链路,每个链路对于一个邮箱
- 链接可以是单向的,也可以是双向的
操作
- 创建新邮箱(端口)
- 通过邮箱发送和接收消息
- 销毁邮箱
基元定义为:
- send(A, message) – 向邮箱 A 发送邮件
- receive(A, message) – 从邮箱 A 接收邮件
邮箱共享
- P1、P2 和 P3 共享邮箱 A
- P1发送;P2 和 P3 接收
- 谁收到消息?
解决方案
- 允许链接最多与两个进程关联
- 一次只允许一个进程执行接收操作
- 允许系统任意选择接收器。
- 通知发送方是接收方。
4.4.2 同步
进程间通信可以通过调用原语 send()和receive()来进行。实现这些原语有不同的设计方案。消息传递可以是阻塞 (blocking)或非阻塞 (nonblocking),也称为同步(synchronous)或异步(asynchronous)。(本书的多种操作系统算法会涉及同步和异步行为的概念。
- 阻塞发送(blocking send): 发送进程阻塞,直到消息由接收进程或邮箱所接收
- 非阻塞发送(nonblocking send): 发送进程发送消息,并且恢复操作。
- 阻塞接收(blocking receive): 接收进程阻塞,直到有消息可用。
- 非阻塞接收(nonblocking receive):接收进程收到一个有效消息或空消息
不同组合的 send()和 receive()都有可能。当send()和 receive()都是阻塞的,则在发送者和接收者之间就有一个交会(rendezvous)。当采用阻塞的 send()和receive()时,生产者-消费者问题的解决就简单了。生产者仅需调用阻塞 send()并且等待,直到消息被送到接收者或邮箱。同样,当消费者调用receive()时,它会阻塞直到有一个消息可用。
Message passing may be either blocking or non-blocking Blocking is considered synchronous
- Blocking send – the sender is blocked until the message is received
- Blocking receive – the receiver is blocked until a message is available
Non-blocking is considered asynchronous
- Non-blocking send – the sender sends the message and continue
- Non-blocking receive – the receiver receives:
- A valid message, or
- Null message
Different combinations possible
- If both send and receive are blocking, we have a rendezvous
消息传递可以是阻塞的或非阻塞的,阻塞被认为是同步的
- 阻塞发送——发送者被阻塞直到消息被接收
- 阻塞接收——接收者被阻塞直到消息可用
非阻塞被认为是异步的
- 非阻塞发送——发送者发送消息并继续
- 非阻塞接收——接收方接收:
- 有效消息,或
- 空消息
可能的不同组合
- 如果发送和接收都阻塞,我们有一个交会(rendezvous )
4.4.3 缓冲 Buffering
不管通信是直接的还是间接的,通信进程交换的消息总是驻留在临时队列中。简单地讲,队列实现有三种方法:
- 零容量(zero capacity):队列的最大长度为0;因此,链路中不能有任何消息处于等待。对于这种情况,发送者应阻塞,直到接收者接收到消息。
- 有限容量(bounded capacity):队列长度为有限的n;因此,最多只能有n个消息驻留其中。如果在发送新消息时队列未满,那么该消息可以放在队列中(或者复制消息或者保存消息的指针),且发送者可以继续执行而不必等待。然而,链路容量是有限的。如果链路已满,那么发送者应阻塞,直到队列空间有可用的为止。
- 无限容量(unbounded capacity):队列长度可以无限,因此,不管多少消息都可在其中等待。发送者从不阻塞。
零容量情况称为无缓冲的消息系统,其他情况称为自动缓冲的消息系统。
Queue of messages attached to the link. implemented in one of three ways
- Zero capacity – no messages are queued on a link. Sender must wait for receiver (rendezvous)
- Bounded capacity – finite length of n messages Sender must wait if link full
- Unbounded capacity – infinite length Sender never waits
附加到链接的消息队列。以三种方式之一实现
- 零容量 – 链路上没有消息排队。发送方必须等待接收方(会合)
- 有界容量 – n 条消息的有限长度 如果链接已满,发件人必须等待
- 无限容量 – 无限长度 发送者从不等待
5. IPC 例子
PPT ch3 3.47 开始
课本 3.5 P89
6. 客户机-服务器通信 Communications in Client-Server Systems
- Sockets
- Remote Procedure Calls(RPC)
- Pipes
-
Remote Method Invocation (Java) (RMI)
-
套接字
- 远程过程调用(RPC)
- 管道
- 远程方法调用 (Java) (RMI)
6.1 Sockets
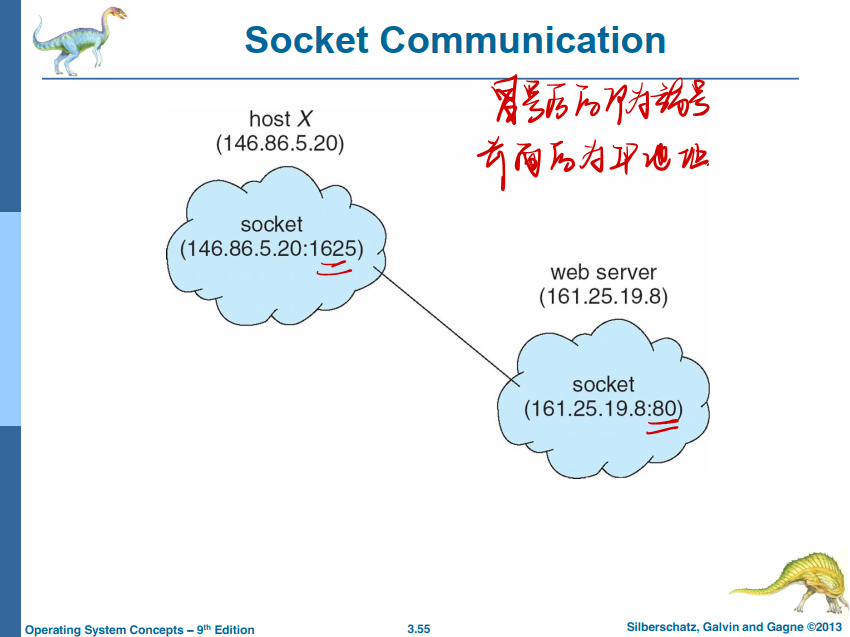
套接字(socket)为通信的端点。通过网络通信的每对进程需要使用一对套接字,即每个进程各有一个。每个套接字由一个IP 地址和一个端口号组成。通常,套接字采用客户机-服务器架构。服务器通过监听指定端口,来等待客户请求。服务器在收到请求后,接受来自客户套接字的连接,从而完成连接。实现特定服务(如telnet、ftp 和 http)的服务器监听所周知的端口(telnet 服务器监听端口 23,fp 服务器监听端口21,Web 或 http 服务器监听端口 80)。所有低于 1024 的端口都是众所周知的,我们可以用它们来实现标准服务
当客户进程发出连接请求时,它的主机为它分配一个端口。这个端口具有大于1024的某个数字。例如,当P地址为146.86.5.20的主机X的客户希望与P地址为161.25.19.8的Web服务器(监听端口80)建立连接时,它所分配的端口可为1625。该连接由一对套接字组成:主机X上的( 146.86.5.20:1625 ),Web 服务器上的(161.25.19.8:80 )这种情况如图3-20所示。根据目的端口号码主机之间传输的分组可以发送到适当的进程。
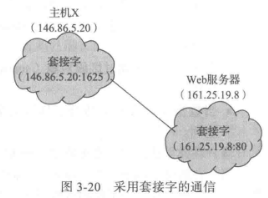
所有连接必须是唯一的。因此,当主机X的另一个进程希望与同样的 Web 服务器建立另一个连接时,它会分配到另一个大于1024但不等于 1625 的端口号。这确保了所有连接都由唯一的一对套接字组成。
Java提供三种不同类型的套接字。
- 面向连接(connection-oriented)的TCP套接字是用Socket类实现的。
- 无连接(connectionless)的UDP 套接字使用 DatagramSocket 类。
- 最后MulticastSocket 类为DatagramSocket 类的子类,多播套接字允许数据发送到多个接收者
A socket is defined as an endpoint for communication
Concatenation of IP address and port – a number included at start of message packet to differentiate network services on a host
The socket 161.25.19.8:1625 refers to port 1625 on host 161.25.19.8
Communication consists between a pair of sockets
All ports below 1024 are well known, used for standard services
Special IP address 127.0.0.1 (loopback) to refer to system on which process is running
套接字定义为通信终结点
套接字是IP 地址和端口的串联 – 消息数据包开头包含的数字,用于区分主机上的网络服务
套接字 161.25.19.8:1625 是指:主机 161.25.19.8 上的端口 1625
通信由一对套接字组成
1024以下的所有端口都是众所周知的,用于标准服务
特殊 IP 地址 127.0.0.1(环回),用于引用正在运行进程的系统
6.2 Remote Procedure Calls (RPC)
(详细内容可看课本3.6.2 P96)
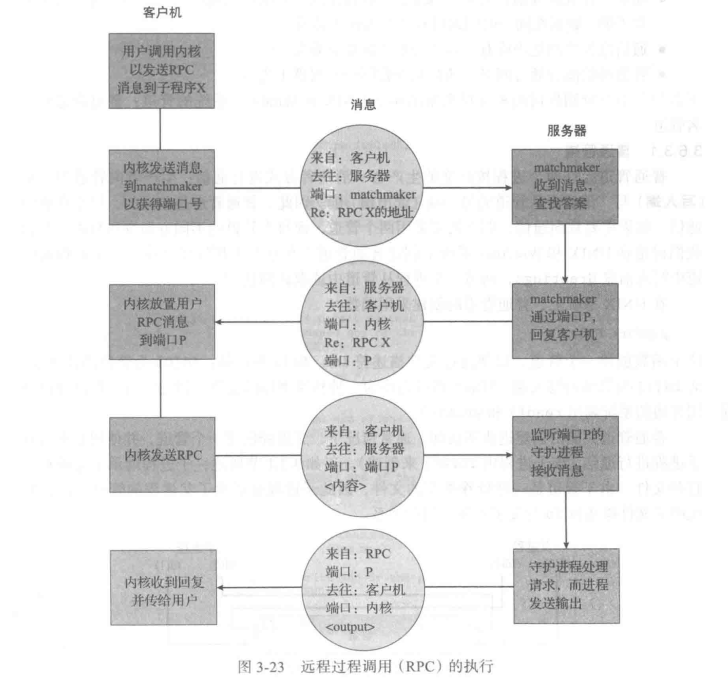
- Remote procedure call (RPC) abstracts procedure calls between processes on networked systems
- Again uses ports for service differentiation
- Stubs – client-side proxy for the actual procedure on the server
- The client-side stub locates the server and marshalls the parameters
- The server-side stub receives this message, unpacks the marshalled parameters, and performs the procedure on the server
-
On Windows, stub code compile from specification written in Microsoft Interface Definition Language (MIDL)
- Data representation handled via External Data
- Representation (XDL) format to account for different architectures
- Big-endian and little-endian
- Remote communication has more failure scenarios than local
- Messages can be delivered exactly once rather than at most once
-
OS typically provides a rendezvous (or matchmaker) service to connect client and server
- 远程过程调用 (RPC) 抽象化网络系统上进程之间的过程调用
- 再次使用端口进行服务差异化
- 存根 – 服务器上实际过程的客户端代理
- 客户端存根定位服务器并封送参数
- 服务器端存根接收此消息,解压缩编组参数,并在服务器上执行该过程
-
在Windows上,从微软界面定义语言(MIDL)编写的规范编译的存根代码
- 通过外部数据处理数据表示
- 表示 (XDL) 格式,用于考虑不同的体系结构
- 大端和小端
- 远程通信的故障场景多于本地通信
- 消息可以只传递一次,而不是最多一次
- 操作系统通常提供会合(或匹配器)服务来连接客户端和服务器
6.3 管道
Acts as a conduit allowing two processes to communicate Issues:
- Is communication unidirectional or bidirectional?
- In the case of two-way communication, is it half or full duplex?
- Must there exist a relationship (i.e., parent-child) between the communicating processes?
- Can the pipes be used over a network?
Ordinary pipes – cannot be accessed from outside the process that created it. Typically, a parent process creates a pipe and uses it to communicate with a child process that it created.
Named pipes – can be accessed without a parent-child relationship
充当允许两个进程传达问题的管道:
- 通信是单向的还是双向的?
- 在双向通信的情况下,是半双工(数据在同一时间内只能按一个方向传输)还是全双工(数据在同一时间内可在两个方向上传输)?
- 通信过程之间是否存在关系(即父子关系)吗?
- 管道可以通过网络使用吗?还是只能在同一台机器上进行
普通管道 – 无法从创建它的进程外部访问。通常,父进程创建一个管道,并使用它来与它创建的子进程进行通信。
命名管道 – 无需父子关系即可访问
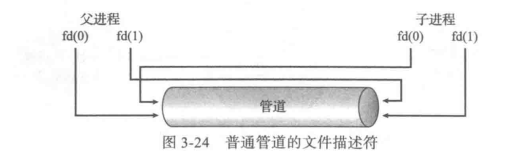
Ordinary Pipes
- Ordinary Pipes allow communication in standard producer-consumer style
- Producer writes to one end (the write-end of the pipe)
- Consumer reads from the other end (the read-end of the pipe)
- Ordinary pipes are therefore unidirectional
- Require parent-child relationship between communicating processes
- Windows calls these anonymous pipes
-
See Unix and Windows code samples in textbook
- 普通管道允许以标准的生产者-消费者风格进行通信
- 生产者写入一端(管道的写入端)
- 使用者从另一端(管道的读取端)读取
- 因此普通管道是单向的
-
要求通信进程之间的父子关系
- Windows调用这些匿名管道
- 请参阅教科书中的Unix和Windows代码示例
Named Pipes
- Named Pipes are more powerful than ordinary pipes Communication is bidirectional
- No parent-child relationship is necessary between the communicating processes
- Several processes can use the named pipe for communication
-
Provided on both UNIX and Windows systems
- 命名管道比普通管道更强大通信是双向的
- 通信过程之间不需要父子关系
- 多个进程可以使用命名管道进行通信
- 在 UNIX 和 Windows 系统上提供
操作系统原理第三章作业
姓名:吕捷为
学号:21307381
完成日期:2023年3月25日
Question 1
3.1 Describe the differences among short-term, medium-term, and long-term scheduling.
3.1 描述短程、中程和长程调度之间的差异
Answer:
- 时间跨度:
短程调度(也称为进程调度)主要负责将就绪队列中的进程选择一个合适的进程,分配给 CPU 进行执行,时间跨度一般是几十毫秒到几秒钟之间。
中程调度(也称为内存调度)主要负责将处于内存中的进程挂起,将其交换到磁盘上,以释放出内存空间,之后进程可以被重新调入内存,并从中断处继续执行,时间跨度一般是几分钟到几小时之间。
长程调度(也称为作业调度)主要负责将新的进程请求分配给系统,并决定是否创建新的进程,时间跨度一般是几小时到几天之间。
- 调度的目的:
短程调度的主要目的是使 CPU 利用率最大化,保证系统的吞吐量,以及确保响应时间和延迟时间的优化。
中程调度的主要目的是管理内存,防止内存耗尽,以及避免进程间的干扰,提高系统的稳定性。
长程调度的主要目的是管理系统资源,保证系统的负载均衡,同时确保系统的可用性和可靠性。
- 调度的频率:
短程调度的频率非常高,每个时钟周期都会进行一次调度。
中程调度的频率较低,一般每几分钟到几小时进行一次调度。
长程调度的频率非常低,一般每几小时到几天进行一次调度。
4 调度的对象:
短程调度的对象是就绪队列中的进程,其选择策略主要是根据进程的优先级、剩余 CPU 时间等因素进行选择。
中程调度的对象是内存中的进程,其选择策略主要是根据进程的内存占用情况、运行时间等因素进行选择。
长程调度的对象是新的进程请求,通常批处理系统提交的进程大多可以立即执行,这些进程会被保存到大容量存储设备(通常是磁盘)的缓冲池,长程调度中该池中悬着进程加载到内存,以便执行。其选择策略主要是根据作业的类型、优先级等因素进行选择。
Question 2:
3.2 Describe the actions taken by a kernel to context-switch between processes.
3.2 描述内核在进程之间切换上下文时执行的操作。
Answer:
在操作系统中,内核在进行进程之间的切换时,需要执行以下操作:
- 保存当前进程的上下文信息:内核会将当前进程的 CPU 寄存器中的信息保存到该进程的 PCB(进程控制块)中,包括程序计数器(PC)、堆栈指针(SP)、通用寄存器和状态寄存器等。
- 选择新进程并恢复其上下文信息:内核会选择一个新的进程,并将该进程的上下文信息从其对应的 PCB 中恢复到 CPU 寄存器中,使得该进程可以继续执行。
- 更新进程状态:内核会更新当前进程的状态,标记其为就绪状态或阻塞状态等,然后将其插入到就绪队列或阻塞队列中。
- 切换内核栈:内核会在从当前进程切换到新进程时,切换内核栈,以确保内核在执行期间可以使用正确的内核栈。
- 执行调度算法:内核会根据调度算法选择下一个要运行的进程,然后切换到该进程的上下文中,并将其标记为当前运行的进程。
需要注意的是,进程切换是一个耗费资源的操作,因为需要保存和恢复大量的上下文信息。因此,操作系统通常会尽量减少进程切换的次数,以提高系统的性能和响应速度。
Question 3:
3.5 What are the benefits and the disadvantages of each of the following? Consider both the system level and the programmer level. a. Synchronous and asynchronous communication b. Automatic and explicit buffering c. Send by copy and send by reference d. Fixed-sized and variable-sized messages
3.5 以下各项的优点和缺点是什么?同时考虑系统级别和程序员级别。 a.同步和异步通信 b.自动和显式缓冲 c. 通过副本发送和通过引用发送 d. 固定大小和可变大小的消息
Answer:
a. 同步和异步通信:
同步通信的优点是在程序员级别上比较容易理解和控制,因为程序员可以明确知道在哪里等待消息,等待多长时间以及如何处理消息。此外,同步通信还可以带来更简单的程序结构和更可预测的性能。但在系统级别上,同步通信可能会导致死锁和资源竞争等问题。
异步通信的优点是可以提高系统的并发性和响应性,因为程序可以继续执行其他操作而无需等待通信操作完成。此外,在系统级别上,异步通信也可以降低系统开销,因为操作系统可以通过事件驱动的方式来管理异步操作。但是,在程序员级别上,异步通信可能会比同步通信更难以理解和控制。
b. 自动和显式缓冲:
自动缓冲的优点是可以降低程序员的工作量和减少通信延迟,因为缓冲可以自动处理。此外,自动缓冲还可以减少通信操作的数量,从而提高系统性能。但是,在程序员级别上,自动缓冲可能会使程序难以调试和排错。
显式缓冲的优点是可以更灵活地控制缓冲区的大小和内容,从而提高系统的可靠性和可调试性。此外,显式缓冲还可以使程序员更容易地处理缓冲区溢出等问题。但是,在系统级别上,显式缓冲可能会增加通信延迟和降低系统性能。
c. 通过副本发送和通过引用发送:
通过副本发送的优点是可以避免共享内存导致的数据竞争等问题,从而提高系统的并发性和可靠性。此外,通过副本发送还可以使程序员更容易地理解和控制数据的传输。但是,在程序员级别上,通过副本发送可能会浪费大量的内存和 CPU 时间。
通过引用发送的优点是可以节省内存和 CPU 时间,从而提高系统性能和可扩展性。此外,通过引用发送还可以使程序员更容易地共享数据和管理数据的生命周期。但是,在系统级别上,通过引用发送可能会导致数据共享的问题,例如竞争条件和死锁等。
d. 固定大小和可变大小的消息:
固定大小的消息的优点是可以提高系统的可靠性和性能,因为它们的大小是固定的,所以操作系统可以更容易地管理内存和缓存。此外,在程序员级别上,固定大小的消息可以更容易地理解和控制。但是,在系统级上,固定大小的消息可能会导致浪费和限制消息的灵活性。
可变大小的消息的优点是可以更灵活地传输数据,从而提高系统的可扩展性和灵活性。此外,在程序员级别上,可变大小的消息可以更容易地处理各种数据类型和大小。但是,在系统级别上,可变大小的消息可能会导致更多的开销和更复杂的处理逻辑,因为操作系统需要动态管理内存和缓存。
总的来说,以上这些选择都有其优点和缺点,需要根据具体的应用场景和需求进行选择。在系统级别上,需要考虑性能、可靠性、可扩展性和安全性等因素。在程序员级别上,需要考虑易用性、可读性、可维护性和可测试性等因素。