流水线CPU设计与实现
一. 实验目的
1) 了解流水线CPU基本功能部件的设计与实现方法,
2) 了解提高CPU性能的方法。
3) 掌握流水线MIPS微处理器的工作原理。
4) 理解数据冒险、控制冒险的概念以及流水线冲突的解决方法。(本设计完成冒险检测及数据转发处理)
5) 掌握流水线MIPS微处理器的测试方法。
二. 实验内容
要求:
1.至少支持add、sub、and、or、addi、andi、ori、lw、sw、beq、bne十一条指令。(本实验报告完成了31条指令)
2.采用5级流水线技术(可选:具有数据前推机制),寄存器堆的写操作提前半个时钟周期,下降沿读取,上升沿写入数据。(已完成数据转发和冒险现象处理)
实现:
本实验实现31条MIPS指令,详细内容见下表,并实现了冒险检测及数据的转发处理,以下实验报告中称本流水线设计为LVCPU(因为本人姓吕)
三. 实验原理
- 流水线介绍
流水线是数字系统中一种提高系统稳定性和工作速度的方法,广泛应用于现代CPU的架构中。根据MIPS处理器的特点,将整体的处理过程分为取指令(IF)、指令译码(ID)、执行(EX)、存储器访问(MEM)和寄存器会写(WB)五级,对应多周期的五个处理阶段。一个指令的执行需要5个时钟周期,每个时钟周期的上升沿来临时,此指令所代表的一系列数据和控制信息将转移到下一级处理。(但是在LVCPU中,指令存储器是调用的IP核,在单周期实验中我们已经发现IP核会有1个周期的Latency,为了解决这个延迟的问题,我们在下降沿的时候取指令,这样就可以获得正确的逻辑)

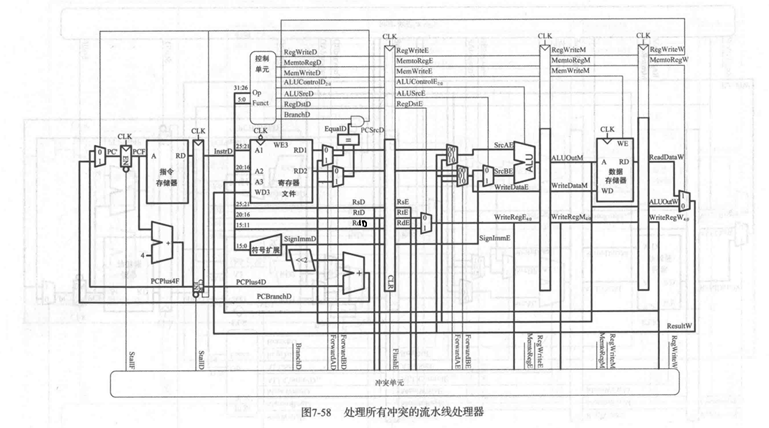
(教材中的图,信号比较全,但是LVCPU中信号并不与其一致)
- MIPS指令集
本次实验共涉及三种类型的MIPS指令,分别为R型、I型和J型,三种类型的MIPS指令格式定义如下:
-
R(register)类型的指令从寄存器堆中读取两个源操作数,计算结果写回寄存器堆;
-
I(immediate)类型的指令使用一个 16位的立即数作为一个源操作数;
-
J(jump)类型的指令使用一个 26位立即数作为跳转的目标地址(target address);
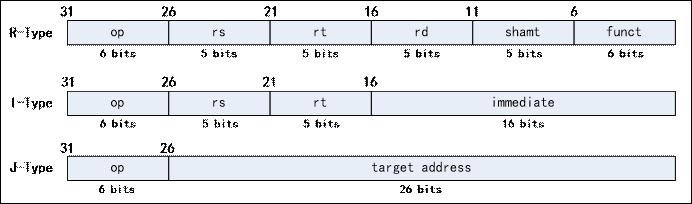
一条指令的执行过程一般有下面的五个阶段,指令的执行过程就是这五个状态的重复过程:

在本次实验中,完成了下列31条指令的功能,包括R型、I型和J型。
MIPS的31种指令
助记符 | 指 令 格 式 | 示 例 | 示例含义 | 操作及解释 | |||||
BIT # | 31..26 | 25..21 | 20..16 | 15..11 | 10..6 | 5..0 | |||
R-类型 | op | rs | rt | rd | shamt | func | |||
add | 000000 | rs | rt | rd | 00000 | 100000 | add $1,$2,$3 | $1=$2+S3 | (rd)←(rs)+(rt); rs=$2,rt=$3,rd=$1 |
addu | 000000 | rs | rt | rd | 00000 | 100001 | addu $1,$2,$3 | $1=$2+S3 | (rd)←(rs)+(rt); rs=$2,rt=$3,rd=$1,无符号数 |
sub | 000000 | rs | rt | rd | 00000 | 100010 | sub $1,$2,$3 | $1=$2-S3 | (rd)←(rs)-(rt); rs=$2,rt=$3,rd=$1 |
subu | 000000 | rs | rt | rd | 00000 | 100011 | subu $1,$2,$3 | $1=$2-S3 | (rd)←(rs)-(rt); rs=$2,rt=$3,rd=$1,无符号数 |
and | 000000 | rs | rt | rd | 00000 | 100100 | and $1,$2,$3 | $1=$2&S3 | (rd)←(rs)&(rt); rs=$2,rt=$3,rd=$1 |
or | 000000 | rs | rt | rd | 00000 | 100101 | or $1,$2,$3 | $1=$2|S3 | (rd)←(rs) | (rt); rs=$2,rt=$3,rd=$1 |
xor | 000000 | rs | rt | rd | 00000 | 100110 | xor $1,$2,$3 | $1=$2^S3 | (rd)←(rs)^(rt); rs=$2,rt=$3,rd=$1 |
nor | 000000 | rs | rt | rd | 00000 | 100111 | nor $1,$2,$3 | $1= ~($2 | S3) | (rd)←~((rs) | (rt)); rs=$2,rt=$3,rd=$1 |
slt | 000000 | rs | rt | rd | 00000 | 101010 | slt $1,$2,$3 | if($2<$3) $1=1 else $1=0 | if (rs< rt) rd=1 else rd=0;rs=$2,rt=$3, rd=$1 |
sltu | 000000 | rs | rt | rd | 00000 | 101011 | sltu $1,$2,$3 | if($2<$3) $1=1 else $1=0 | if (rs< rt) rd=1 else rd=0;rs=$2,rt=$3, rd=$1, 无符号数 |
sll | 000000 | 00000 | rt | rd | shamt | 000000 | sll $1,$2,10 | $1=$2<<10 | (rd)←(rt)<<shamt,rt=$2,rd=$1,shamt=10 |
srl | 000000 | 00000 | rt | rd | shamt | 000010 | srl $1,$2,10 | $1=$2>>10 | (rd)←(rt)>>shamt, rt=$2, rd=$1, shamt=10, (逻辑右移) |
sra | 000000 | 00000 | rt | rd | shamt | 000011 | sra $1,$2,10 | $1=$2>>10 | (rd)←(rt)>>shamt, rt=$2, rd=$1, shamt=10, (算术右移,注意符号位保留) |
sllv | 000000 | rs | rt | rd | 00000 | 000100 | sllv $1,$2,$3 | $1=$2<<$3 | (rd)←(rt)<<(rs), rs=$3,rt=$2,rd=$1 |
srlv | 000000 | rs | rt | rd | 00000 | 000110 | srlv $1,$2,$3 | $1=$2>>$3 | (rd)←(rt)>>(rs), rs=$3,rt=$2,rd=$1, (逻辑右移) |
srav | 000000 | rs | rt | rd | 00000 | 000111 | srav $1,$2,$3 | $1=$2>>$3 | (rd)←(rt)>>(rs), rs=$3,rt=$2,rd=$1, (算术右移,注意符号位保留) |
jr | 000000 | rs | 00000 | 00000 | 00000 | 001000 | jr $31 | goto $31 | (PC)←(rs) |
I-类型 | op | rs | rt | immediate | |||||
addi | 001000 | rs | rt | immediate | addi $1,$2,10 | $1=$2+10 | (rt)←(rs)+(sign-extend)immediate,rt=$1,rs=$2 | ||
addiu | 001001 | rs | rt | immediate | addiu $1,$2,10 | $1=$2+10 | (rt)←(rs)+(sign-extend)immediate,rt=$1,rs=$2 | ||
andi | 001100 | rs | rt | immediate | andi $1,$2,10 | $1=$2&10 | (rt)←(rs)&(zero-extend)immediate,rt=$1,rs=$2 | ||
ori | 001101 | rs | rt | immediate | ori $1,$2,10 | $1=$2|10 | (rt)←(rs)|(zero-extend)immediate,rt=$1,rs=$2 | ||
xori | 001110 | rs | rt | immediate | xori $1,$2,10 | $1=$2^10 | (rt)←(rs)^(zero-extend)immediate,rt=$1,rs=$2 | ||
lui | 001111 | 00000 | rt | immediate | lui $1,10 | $1=10*65536 | (rt)←immediate<<16 & 0FFFF0000H,将16位立即数放到目的寄存器高16位,目的寄存器的低16位填0 | ||
lw | 100011 | rs | rt | offset | lw $1,10($2) | $1=Memory[ $2+10] | (rt)←Memory[(rs)+(sign_extend)offset], rt=$1,rs=$2 | ||
sw | 101011 | rs | rt | offset | sw $1,10($2) | Memory[ $2+10] =$1 | Memory[(rs)+(sign_extend)offset]←(rt), rt=$1,rs=$2 | ||
beq | 000100 | rs | rt | offset | beq $1,$2,40 | if($1=$2) | if ((rt)=(rs)) then (PC)←(PC)+4+( (Sign-Extend) offset<<2), rs=$1, rt=$2 | ||
bne | 000101 | rs | rt | offset | bne $1,$2,40 | if($1≠$2) | if ((rt)≠(rs)) then (PC)←(PC)+4+( (Sign-Extend) offset<<2) , rs=$1, rt=$2 | ||
slti | 001010 | rs | rt | immediate | slti $1,$2,10 | if($2<10) | if ((rs)<(Sign-Extend)immediate) then (rt)←1; else (rt)←0, rs=$2, rt=$1 | ||
sltiu | 001011 | rs | rt | immediate | sltiu $1,$2,10 | if($2<10) | if ((rs)<(Zero-Extend)immediate) then (rt)←1; else (rt)←0, rs=$2, rt=$1 | ||
J-类型 | op | address | |||||||
j | 000010 | address | j 10000 | goto 10000 | (PC)←( (Zero-Extend) address<<2), address=10000/4 | ||||
jal | 000011 | address | jal 10000 | $31=PC+4 goto 10000 | ($31)←(PC)+4; (PC)←( (Zero-Extend) address<<2), address=10000/4 | ||||
add和addu区别是有无溢出检测
addiu和sltiu虽然是无符号比较,但是立即数imm扩展的时候仍然是符号扩展
四.实验器材
电脑一台,Xilinx Vivado 软件一套,Basys3板一块。
五. 实验过程与结果
1. CPU的设计
CPU分成5个模块,IF,ID,EX,MEM,WB;
吸取了单周期设计的经验,我们将每个部分都模块化设计,便于调试,分成以下模块:
1.PC:负责 PC 更新, 仅在 clk 或者 rst 为 posedge 时更新 PC。
2.Next_PC:计算下一条指令地址,送到PC模块
3.BranchTest:判断分支指令是否满足条件跳转
4.IF_ID:流水线寄存器
5.4选1选择器MUX4(以下模块例化MUX4即可)
-
FORWARD_A:转发 ALU 操作数 A
-
FORWARD_B:转发 ALU 操作数 B
-
FORWARD_C:转发分支判断的操作数 A
-
FORWARD_D:转发分支判断的操作数 B
-
FORWARD_E:转发跳转指令的跳转地址
-
WR_REG:选择写寄存器的地址
-
WR_REG_DATA:选择写寄存器的数据
6.Register:通用寄存器组
7.SignExtension:立即数扩展
8.SRC_A:选择 ALU 的操作数 A
9.SRC_B:选择 ALU 的操作数 B(MUX2)
10.ControlUnit:产生控制信号
11.ID_EX:流水线寄存器
12.ALU:运算器模块
13.Forwarding:数据前推模块, 产生 5 个转发信号
14.HazardDetection:load-use 冒险检测模块
15.EX_MEM:流水线寄存器
16.MEM_WB:流水线寄存器
17.CPU:连接接线
18.InstructionMemory:指令存储器
19.DataMemory:数据存储器
具体作用见下面的具体设计
1.1流水线冒险问题解决方案
在流水线 CPU 执行过程中, 往往会出现后面的指令要用到前面的指令执行后的结果的情况, 但由于流水线, 前面的指令还未执行完成将结果写回寄存器,后面的指令就需要读取该寄存器的值来进行执行, 这种情况就是数据相关。 对于数据冒险,主要有三个解决办法:硬件阻塞、软件NOP和转发技术(Forwarding)。我们采取数据转发的方式来解决这一类问题。
(1) 对于传入 ALU 的 A口 和 B口两个数据,在指令运行到 EX 阶段才需要考虑,有如下情况:
①当 MEM 阶段指令是需要写回到寄存器的操作,并且与 EX 阶段的指令所要访问的寄存器是同一个,且写回的寄存器不是 0 号寄存器,则将 MEM 阶段的 ALU 运算结果进行转发,转发到EX阶段。
②当 WB 阶段指令是需要写回寄存器的操作,并且与 EX 阶段的指令所要访问的寄存器是同一个,且写回的寄存器不是 0 号寄存器,且不满足条件①,则将要写回寄存器的数据进行转发,转发到EX阶段。
③不存在数据相关,直接用从寄存器中读出的值即可。
(2) 对于 Load-Use 数据冒险:当 EX 阶段的指令是 load 指令,并且 load 的数据存放将要存放的寄存器与 ID 阶段指令要访问的寄存器相同,说明此时会有Load-Use数据冒险,这时需要插入一个stall, 即清空 ID-EX 寄存器的控制信号, 并且保持 IF-ID 寄存器的值不变以及保持PC 值不变。这样子下一次从IF-ID寄存器中读出来的值仍然是原本ID阶段该执行的指令。
(3) 对于分支指令,首先我们采取分支预测的方式,在 IF 阶段读取到分支指令时,总是预测分支指令跳转成功, 当指令执行到 ID 阶段,解码出分支指令的判断条件以及数据来源,我们依旧采取数据转发的方式,将正确的数据进行转发,来对分支指令是否跳转进行判断,所以需要将数据转发再提前一个阶段。
①当 EX 阶段指令是要写回寄存器操作,且写回的寄存器不是 0 号寄存器,并且与 ID 阶段的指令所要访问的寄存器是同一个,则将 EX 阶段的 ALU 运算结果进行转发。
②当 MEM 阶段指令是要写回寄存器操作,且写回的寄存器不是 0 号寄存器,并且与 ID 阶段的指令所要访问的寄存器是同一个,且不满足条件①则将 MEM阶段的 ALU 运算结果进行转发。
③当 WB 阶段指令是要写寄存器操作,且写回的寄存器不是 0 号寄存器,并且与 ID 阶段的指令所要访问的寄存器是同一个,且不满足条件②,则将要写回寄存器的数据进行转发。
④不存在数据相关,直接转发从寄存器中读出的值即可。
(4) 对于跳转指令,情况与分支指令类似,只是不需要判断是否需要跳转而是直接跳转即可。因此j,jal,jr后都会先顺序读取PC,然后在ID阶段解码后,产生IF_Flush信号将其冲刷掉,重新计算PC的值并在下一周期取到指令
1.2分支预测的设计
对于分支指令,由于在单周期 CPU 中,判断分支指令是否跳转需要到 EX 阶段执行完成,而如果在流水线 CPU 中遇到分支指令,插入气泡等待分支指令执行完成再决定下一条指令无疑会浪费许多时间, 所以我们采取分支预测的方式,在 IF 阶段取到指令后,判断若是分支指令,则默认预测分支指令跳转,而当分支指令执行到 ID 阶段后,通过解码获得分支指令的判断条件以及数据来源后,通过数据转发对应的数据进行判断,如果判断结果是跳转成功则说明预测成功,继续执行。如果判断结果是不应该跳转,则这时由于我们预测分支指令跳转成功,所以需要将已经取入 IF 阶段的指令进行清空。将此时 ID 阶段即分支指令的下一条指令 PC 传回
2.各模块具体设计
(1)指令存储器(IM)
调用系统的ip核,用Mars编写汇编程序后,转为16进制的指令,然后写到coe文件中,导入ip核。需要注意的是,IP核中Port A Options-Port A Optional Output Registers-Primitives Output Register不要勾选,因为勾选后会使得IP核的Latency为2,使得PC无法从0开始。
(2)数据存储器模块(DM)
只有lw和sw指令需要用到,传入读取/写入内存的地址,写入使能信号,写入的数据,输出从内存读取的数据
(3)Register:通用寄存器组
寄存器组是指令操作的主要对象,MIPS 处理器里一共有 32 个 32 位的寄存器,故可以声明一个包含 32 个 32 位的寄存器数组
(4)数码管显示模块(display)
七段译码显示的内容是16位的,而ALU的运算结果是32位的,将运算结果分为高十六位和低十六位,分别传进七段译码模块;在顶层模块可用一个开关,来选择是显示高16位还是低16位;sm_wei 选择哪一个数码管亮,sm_duan 选择数码管的哪一段亮,sm_wei 变换的速度是 1 秒 1000 次,使人眼看起来数码管是同时显示数值的。
display输入的时钟是高频时钟,在模块内部需要分频使得容易看
(5)流水线寄存器:IF_ID
输入:
PCWrite: PC 是否有效, 无效时保持 IF-ID 阶段指令不变
IF_Flush 控制是否清空 IF 阶段的指令
PC_IF IF阶段指令地址
Instruction_IF IF 阶段指令
输出:
PC_ID ID阶段指令地址
Instruction_ID ID阶段指令
(6)流水线寄存器:ID_EX
输入
stall控制是否清空 ID 阶段产生的控制信号, load-use 冒险
WriteRegSignal_ID ID 阶段指令写入寄存器地址的选择信号
WriteRegDataSignal_ID ID 阶段指令写入寄存器数据的选择信号
AluSrc1Signal_ID ID 阶段指令操作数 A 选择信号
AluSrc2Signal_ID ID 阶段指令操作数 B 选择信号
AluOpcode_ID ID 阶段指令 ALU 的操作符
MemWrite_ID ID 阶段指令是否写内存
MemRead_ID ID 阶段指令是否读内存
RegWrite_ID ID 阶段指令是否写寄存器
ReadRegData1_ID ID 阶段指令从 rs 选择的寄存器读出的数据
ReadRegData2_ID ID 阶段指令从 rt 选择的寄存器读出的数据
Shamt_ID ID 阶段指令移位指令的位移量
Imm32_ID ID 阶段指令扩展后的 32 位立即数
RegSource_ID ID 阶段指令 rs
RegTarget_ID ID 阶段指令 rt
RegDst_ID ID 阶段指令 rd
Instruction_ID ID 阶段指令
PC_ID ID 阶段指令地址
JumpSignal_ID ID 阶段指令标记分支指令和跳转指令信号
输出
ReadRegData1_EX EX 阶段指令从 rs 选择的寄存器读出的数据
ReadRegData2_EX EX 阶段指令从 rt 选择的寄存器读出的数据
Shamt_EX EX 阶段指令移位指令的位移量
Imm32_EX EX阶段指令扩展后的32位立即数
RegSource_EX EX 阶段指令 rs
RegTarget_EX EX 阶段指令 rt
RegDst_EX EX 阶段指令 rd
Instruction_EX EX 阶段指令
PC_EX EX 阶段指令地址
WriteRegSignal_EX EX 阶段指令写入寄存器地址的选择信号
WriteRegDataSignal_EX EX 阶段指令写入寄存器数据的选择信号
AluSrc1Signal_EX EX 阶段指令操作数 A 选择信号
AluSrc2Signal_EX EX 阶段指令操作数 B 选择信号
AluOpcode_EX EX 阶段指令 ALU 的操作符
MemWrite_EX EX 阶段指令是否写内存
MemRead_EX EX 阶段指令是否读内存
RegWrite_EX EX 阶段指令是否写寄存器
JumpSignal_EX EX 阶段指令标记分支指令和跳转指令信号
(7)流水线寄存器:EX_MEM
输入:
MemRead_EX EX 阶段是否要读内存
MemWrite_EX EX 阶段是否要写内存
RegWrite_EX EX 阶段是否写寄存器
WriteRegDataSignal_EX EX 阶段写寄存器数据的选择信号
AluResult_EX EX 阶段指令运算结果
WriteMemData_EX EX 阶段写内存数据
WriteRegAddr_EX EX 阶段写内存地址
Instruction_EX EX 阶段指令
PC_EX EX 阶段指令地址
输出:
MemRead_MEM MEM 阶段是否要读内存
MemWrite_MEM MEM 阶段是否要写内存
RegWrite_MEM MEM 阶段是否写寄存器
WriteRegDataSignal_MEM MEM 阶段写寄存器数据的选择信号
AluResult_MEM MEM 阶段指令运算结果
WriteMemData_MEM MEM 阶段写内存数据
WriteRegAddr_MEM MEM 阶段写内存地址
Instruction_MEM MEM 阶段指令
PC_MEM MEM 阶段指令地址
(8)流水线寄存器:MEM_WB
输入:
RegWrite_MEM MEM 阶段是否写寄存器
WriteRegDataSignal_MEM MEM 阶段写寄存器数据的选择信号
AluResult_MEM MEM 阶段指令运算结果
WriteRegAddr_MEM MEM 阶段写内存地址
Instruction_MEM MEM 阶段指令
PC_MEM MEM 阶段指令地址
输出:
RegWrite_WB WB 阶段是否写寄存器
WriteRegDataSignal_WB WB 阶段写寄存器数据的选择信号
AluResult_WB WB 阶段指令运算结果
WriteRegAddr_WB WB 阶段写内存地址
Instruction_WB WB 阶段指令
PC_WB WB 阶段指令地址
(9)PC:负责 PC 更新, 仅在 clk 或者 rst 为 posedge 时更新 PC
如果是reset,那么PC更新为0x00000000
(10)Next_PC
NextPCSignal :
一.000 顺序执行,
二.001 branch分支,地址为PC+4+offset*4,(后补两个0即左移两位,相当于乘4)也即:
3’b001: NextPC = NextPC_IF + { {14{JumpAddr_IF[15]}}, JumpAddr_IF[15:0], 2’b00};//branch
因为需要分支预测,在IF阶段我们就要由Opcode判断是不是branch指令,如果是的话就要马上算出跳转地址,所以这里的JumpAddr是IF阶段指令的后15位imm,
三.010 分支预测失败,取ID阶段寄存器中的PC(流水线寄存器中存的都是当前指令的PC)+4传到NextPC模块
四.011 j 和jal,要将PC的高4位与 指令的后25位左移两位 拼接在一起(左移两位即乘4)
3’b011: NextPC = {PC_ID[31:28], JumpAddr_ID[25:0], 2’b00};//j jal
五.100 jr,将31号寄存器中值取出来,即为跳转地址
(11)BranchTest
由于我们增加了分支预测的功能,所以我们在IF阶段也需要判断是不是branch类型的指令,如果IF阶段是branch指令的话,不管是否满足跳转的条件,我们下一个地址都要假设发生跳转,如果IF阶段不是branch指令的话,那么就顺序执行PC+4。
在ID阶段,控制器ControlUnit已经根据Funct码和Opcode得出是何种指令,并输出JumpSignal标记是何种跳转操作,若为jal、j、jr指令,则需要将IF阶段的指令冲刷掉(IF/ID寄存器中值全清空为0),因为在IF阶段的指令是顺序执行的而不是跳转的地址。如果是branch指令且在ID阶段发现不满足跳转条件(beq两寄存器值不等,bne两寄存器值相等),那么也需要冲刷IF阶段,并从ID阶段的寄存器中取出ID阶段的PC,加4后送到NextPC模块
(12)ControlUnit:产生控制信号
利用指令Funct码和Opcode码解码得出具体指令,R型指令的Opcode为0,然后要根据Funct码来区分是哪一个R型指令,I型指令和J型指令直接根据Opcode码的出。在单周期实验中我用的是MainControl和ALUControl结合的方法,MainControl中区分指令类型,ALUControl中利用Funct码确定ALU的运算,运用的思想是将一个庞大的逻辑电路分成多个较小的逻辑电路的方法,但是在流水线实验中,接线太多,为了节省接口,我直接将整个控制器写成一个大的模块,并将单周期中J、Jal、Jr、Branch等信号集成为JumpSignal:
| JumpSignal | |
|---|---|
| 000 | 顺序 |
| 001 | 分支指令Branch |
| 010 | J |
| 011 | Jr |
| 111 | Jal |
一共产生11个控制信号:
-
RegWrite,寄存器写回使能信号,为1有效
-
MemWrite,内存写使能信号,为1有效
-
MemRead,内存读使能信号,为1有效
-
SignExt ,符号扩展,1为符号扩展,0为零扩展
-
AluOpcode,确定ALU中操作:
| AluOpcode | alu 操作符 |
|---|---|
| 00000 (0) | NOP(JR/J/JAL) |
| 00001 (1) | ADDU(not overflow detect)/ADDIU/LW/SW |
| 00010 (2) | SUBU(not overflow detect)/BEQ/BNE |
| 00011 (3) | ADD/ADDI |
| 00100 (4) | SUB |
| 00101 (5) | AND/ANDI |
| 00110 (6) | OR/ORI |
| 00111 (7) | XOR/XORI |
| 01000 (8) | NOR |
| 01001 (9) | SLT/SLTI |
| 01010 (10) | SLTU/SLTIU |
| 01011 (11) | SLL |
| 01100 (12) | SRL |
| 01101 (13) | SRA |
| 01110 (14) | SLLV |
| 01111 (15) | SRLV |
| 10000 (16) | SRAV |
| 10001 (17) | LUI |
-
JumpSignal,见上面
-
AluSrc1Signal,ALU的A口的数据来源,为1选则shamt字段,移位指令需要,为0选Rs寄存器中数据
-
AluSrc2Signal,ALU的B口的数据来源,为1则选立即数imm,为0选择Rt寄存器中值
-
WriteRegDataSignal,写入寄存器的数据,00是ALU运算结果,01是内存中读出来的值,10是PC+4(jal指令)
-
WriteRegSignal,写入寄存器地址,00为Rd,01为Rt,10为31号寄存器
-
NextPCSignal,确定下一指令如何取,000为顺序执行,001为branch,010分支预测失败,选ID阶段的PC加4作为下一地址,011为j和jal,100为jr
产生的信号表如下:
R-type:
| instruction | RegWrite | MemWrite | SignExt | AluOpcode | JumpSignal | AluSrc1Signal | AluSrc2Signal | WriteRegDataSignal | WriteRegSignal | MemRead |
|---|---|---|---|---|---|---|---|---|---|---|
| ADD | 1 | 0 | 0 | 00011 | 000 | 0 | 0 | 00 | 00 | 0 |
| ADDU | 1 | 0 | 0 | 00001 | 000 | 0 | 0 | 00 | 00 | 0 |
| SUB | 1 | 0 | 0 | 00100 | 000 | 0 | 0 | 00 | 00 | 0 |
| SUBU | 1 | 0 | 0 | 00010 | 000 | 0 | 0 | 00 | 00 | 0 |
| AND | 1 | 0 | 0 | 00101 | 000 | 0 | 0 | 00 | 00 | 0 |
| OR | 1 | 0 | 0 | 00110 | 000 | 0 | 0 | 00 | 00 | 0 |
| XOR | 1 | 0 | 0 | 00111 | 000 | 0 | 0 | 00 | 00 | 0 |
| NOR | 1 | 0 | 0 | 01000 | 000 | 0 | 0 | 00 | 00 | 0 |
| SLT | 1 | 0 | 0 | 01001 | 000 | 0 | 0 | 00 | 00 | 0 |
| SLTU | 1 | 0 | 1 | 01010 | 000 | 0 | 0 | 00 | 00 | 0 |
| SLL | 1 | 0 | 0 | 01011 | 000 | 1 | 0 | 00 | 00 | 0 |
| SRL | 1 | 0 | 0 | 01100 | 000 | 1 | 0 | 00 | 00 | 0 |
| SRA | 1 | 0 | 0 | 01101 | 000 | 1 | 0 | 00 | 00 | 0 |
| SLLV | 1 | 0 | 0 | 01110 | 000 | 0 | 0 | 00 | 00 | 0 |
| SRLV | 1 | 0 | 0 | 01111 | 000 | 0 | 0 | 00 | 00 | 0 |
| SRAV | 1 | 0 | 0 | 10000 | 000 | 0 | 0 | 00 | 00 | 0 |
| JR | 0 | 0 | 0 | 00000 | 011 | 0 | 0 | 00 | 00 | 0 |
I-type
| instruction | RegWrite | MemWrite | SignExt | AluOpcode | JumpSignal | AluSrc1Signal | AluSrc2Signal | WriteRegDataSignal | WriteRegSignal | MemRead |
|---|---|---|---|---|---|---|---|---|---|---|
| ADDI | 1 | 0 | 1 | 00011 | 000 | 0 | 1 | 00 | 01 | 0 |
| ADDIU | 1 | 0 | 1 | 00001 | 000 | 0 | 1 | 00 | 01 | 0 |
| ANDI | 1 | 0 | 0 | 00101 | 000 | 0 | 1 | 00 | 01 | 0 |
| ORI | 1 | 0 | 0 | 00110 | 000 | 0 | 1 | 00 | 01 | 0 |
| XORI | 1 | 0 | 0 | 00111 | 000 | 0 | 1 | 00 | 01 | 0 |
| LUI | 1 | 0 | 0 | 10001 | 000 | 0 | 1 | 00 | 01 | 0 |
| LW | 1 | 0 | 1 | 00001 | 000 | 0 | 1 | 01 | 01 | 1 |
| SW | 0 | 1 | 1 | 00001 | 000 | 0 | 1 | 00 | 00 | 0 |
| BEQ | 0 | 0 | 0 | 00010 | 001 | 0 | 0 | 00 | 01 | 0 |
| BNE | 0 | 0 | 0 | 00010 | 001 | 0 | 0 | 00 | 01 | 0 |
| SLTI | 1 | 0 | 1 | 01001 | 000 | 0 | 1 | 00 | 01 | 0 |
| SLTIU | 1 | 0 | 1 | 01010 | 000 | 0 | 1 | 00 | 01 | 0 |
J-type
| instruction | RegWrite | MemWrite | SignExt | AluOpcode | JumpSignal | AluSrc1Signal | AluSrc2Signal | WriteRegDataSignal | WriteRegSignal | MemRead |
|---|---|---|---|---|---|---|---|---|---|---|
| J | 0 | 0 | 0 | 00000 | 010 | 0 | 0 | 00 | 00 | 0 |
| JAL | 1 | 0 | 0 | 00000 | 111 | 0 | 0 | 10 | 10 | 0 |
(13)4选1选择器MUX4(以下模块例化MUX4即可)
- FORWARD_A:转发 ALU 操作数 A
00: EX 阶段指令从 rs 寄存器读出的值
01: WB 阶段要写入寄存器的值
10: MEM 阶段指令的运算结果
11:0(其实要用的是3选1,但是4选1可以兼容,就不用再写一个模块了)
- FORWARD_B:转发 ALU 操作数 B
00: EX 阶段指令从 rt 寄存器读出的值
01: WB 阶段指令要写入寄存器的值
10: MEM 阶段指令的运算结果
11:0
- FORWARD_C:转发分支判断的操作数 A
00: ID 阶段指令从 rs 寄存器读出的值
01: EX 阶段指令的运算结果
10: MEM 阶段指令的运算结果
11: WB 阶段指令要写入寄存器的值
- FORWARD_D:转发分支判断的操作数 B
00: ID 阶段指令从 rs 寄存器读出的值
01: EX 阶段指令的运算结果
10: MEM 阶段指令的运算结果
11: WB 阶段指令要写入寄存器的值
- FORWARD_E:转发跳转指令的跳转地址
00: ID 阶段指令从 rs 寄存器读出的值
01: WB 阶段指令要写入寄存器的值
10: EX 阶段指令的运算结果
11: MEM 阶段指令的运算结果
- WR_REG:选择写寄存器的地址
00:Rd
01:Rt
10:31号寄存器
11:0(不会选择这个)
- WR_REG_DATA:写寄存器数据
00:WB阶段指令运算结果
01:内存中读出来的数据
10:PC+4(jal指令)
11:0(不会选择这个)
(14)SRC_A:选择 ALU 的操作数 A
如果是jal,那么A口选择PC+4传入,之后要将PC+4写入31号寄存器
如果是移位指令,则选EX阶段移位指令的shamt
其他就选从FORWARD_A选择的Rs数据
(15)SRC_B:选择 ALU 的操作数 B(MUX2)
0:选择由FORWARD_B选择的Rt数据
1:EX阶段指令经过立即数扩展之后的imm
(16)SignExtension:立即数扩展
0:零扩展
{16’d0,Imm16}
1:符号扩展
{{16}{ Imm16[15] }}
(17)ALU:运算器模块
看AluopCode的表即可,如ADDU/ADDIU/LW/SW用的都是同一个加法,不需要溢出检测
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
ALU_NOP: AluResult = AluOperandA;//jal的PC+4从A口传入,之后要写回到31号寄存器
ALU_ADDU: AluResult = AluOperandA + AluOperandB;
ALU_SUBU: AluResult = AluOperandA - AluOperandB;
ALU_ADD: AluResult = AluOperandA + AluOperandB;
ALU_SUB: AluResult = AluOperandA - AluOperandB;
ALU_AND: AluResult = AluOperandA & AluOperandB;
ALU_OR: AluResult = AluOperandA | AluOperandB;
ALU_XOR: AluResult = AluOperandB ^ AluOperandA;
ALU_NOR: AluResult = ~(AluOperandA | AluOperandB);
ALU_SLT: AluResult = (AluOperandA < AluOperandB) ? 32'd1 : 32'd0;
ALU_SLTU: AluResult = ({1'b0, AluOperandA} < {1'b0, AluOperandB}) ? 32'd1 : 32'd0;
ALU_SLL: AluResult = AluOperandB << AluOperandA;
ALU_SRL: AluResult = AluOperandB >> AluOperandA;
ALU_SRA: AluResult = AluOperandB >>> AluOperandA;
ALU_SLLV: AluResult = AluOperandB << AluOperandA;
ALU_SRLV: AluResult = AluOperandB >> AluOperandA;
ALU_SRAV: AluResult = AluOperandB >>> AluOperandA;
ALU_LUI: AluResult = AluOperandB << 16;
溢出检测:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
if((AluOpcode == ALU_ADD) || (AluOpcode == ALU_SUB)) begin
if(((AluOperandA[31]^AluOperandB[31])==0)&&(AluOperandA[31]!=AluResult[31])) begin
AluOverflowSignal = 1'b1;
end else begin
AluOverflowSignal = 1'b0;
end
end else begin
AluOverflowSignal = 1'b0;
end
(18)Forwarding:数据前推模块, 产生 5 个转发信号
见实验报告开头的分析
(19)HazardDetection:load-use 冒险检测模块
见实验报告开头的分析
(20)顶层模块LVCPU
对指令的操作都再CPU模块进行,之后在与IM、DM模块连接组成LVCPU模块。
将对应信号接好,加入控制板上的SW来控制,需要实现单步运行or连续运行,显示内容有Instruction、MemReadData、ALUResult、PC,reset。
3.CPU正确性验证
表格中为理论值,图中为仿真波形图
因为流水线CPU的数值是跟着指令走的,所以图中ALU运算的结果并不是刚进入IF阶段的指令的运算结果,在EX阶段运算完后,ALUResult和指令Instruction会一起存进EX/MEM寄存器,所以图中Instruction_MEM即为ALU运算结果的对应指令。测试程序中已经设计好了数据冒险和控制冒险现象并成功解决。
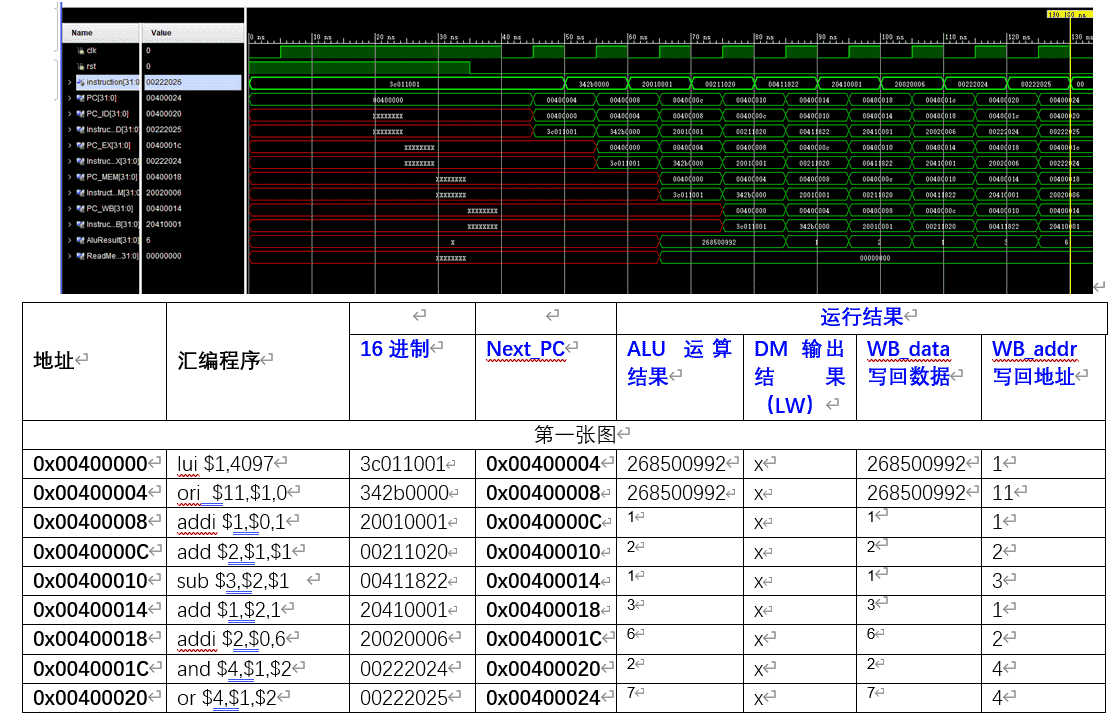
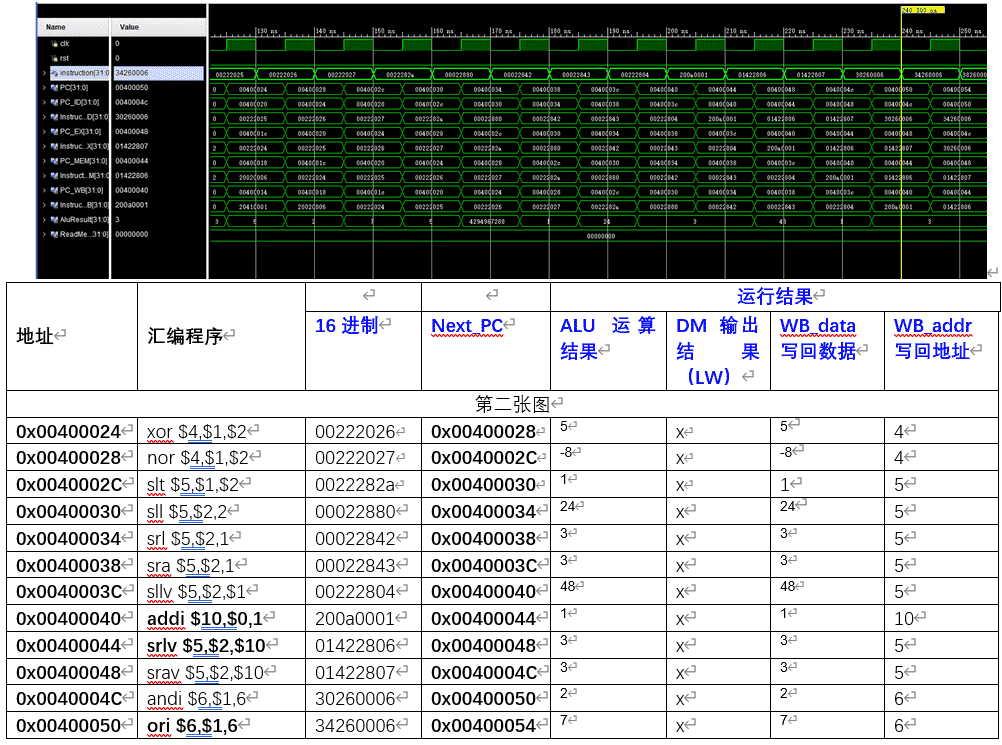
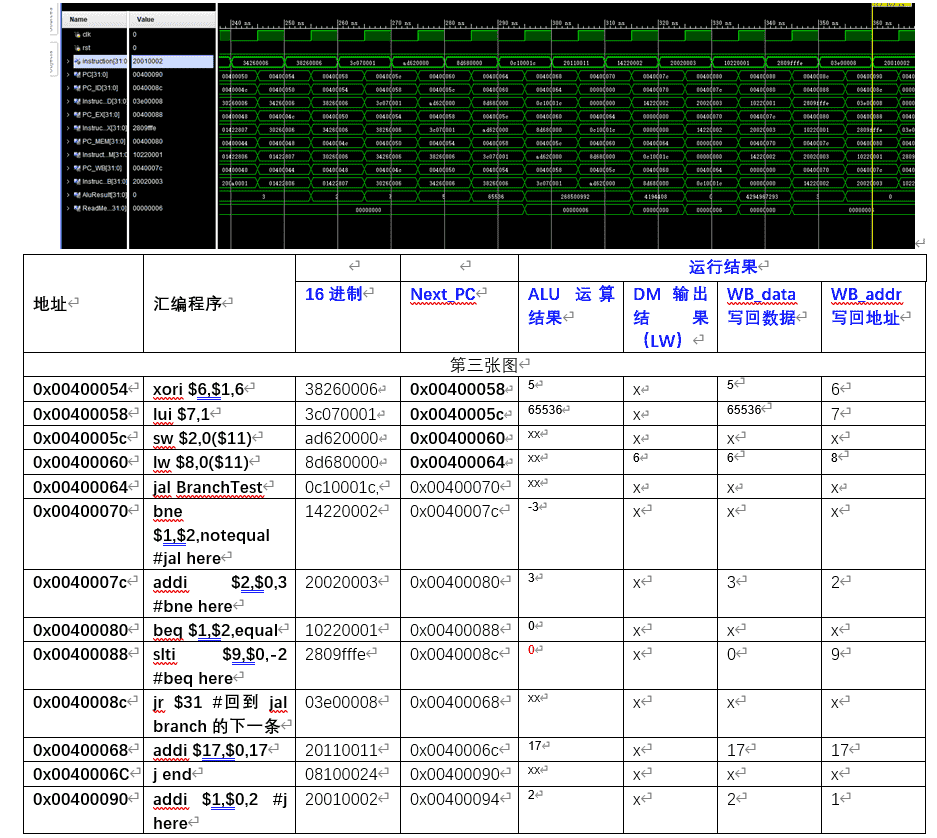
由上述程序段可以看出,LVCPU的仿真逻辑满足我们的流水线CPU设计
经过比对,图中的仿真得到的数据与理论值符合,说明CPU设计正确,需要特别注意的是跳转指令,分析如下:
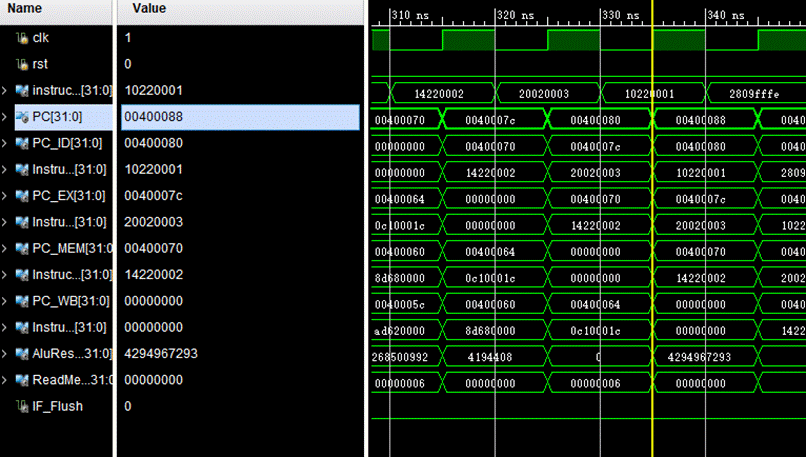
1.0x400064为jal指令,应该要跳转到0x400070的位置,跳转成功,并且看jr指令能否跳转回到0x400068的位置
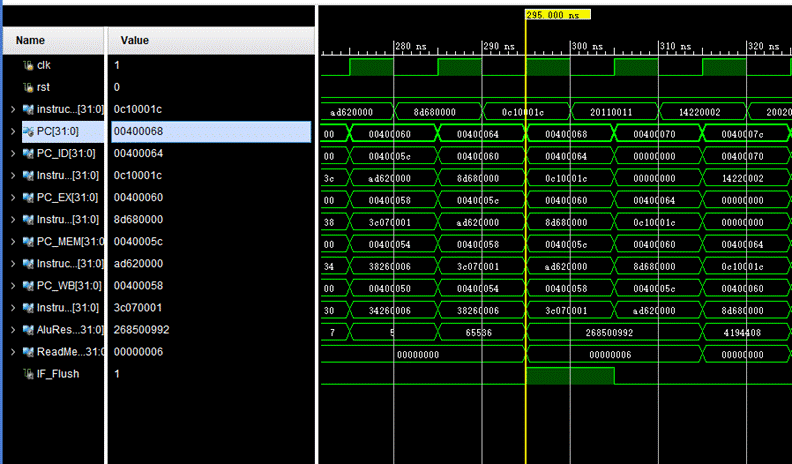
图中我们可以看到在0x400064后先是顺序读取到了0x400068,因为在IF阶段无法得知是J型指令,只有在ID阶段解码后得到Opcode才可以知道,在下一个周期, 0x400064的指令进入了ID阶段,此时经过阶码得知是J型的跳转指令,所以会冲刷IF阶段IF/ID寄存器中指令,让PC回到ID阶段的PC并且计算分支地址(在NextPC中处理),在下一个周期既可以得到正确的PC值,然后取出对应的指令继续运行
2.0x40008c为jr指令,成功跳转回0x400068,是jal指令的下一条,说明jal指令成功跳转的同时也将PC+4的地址记录到了31号寄存器中,jr指令可以成功从31号寄存器读取地址并跳转
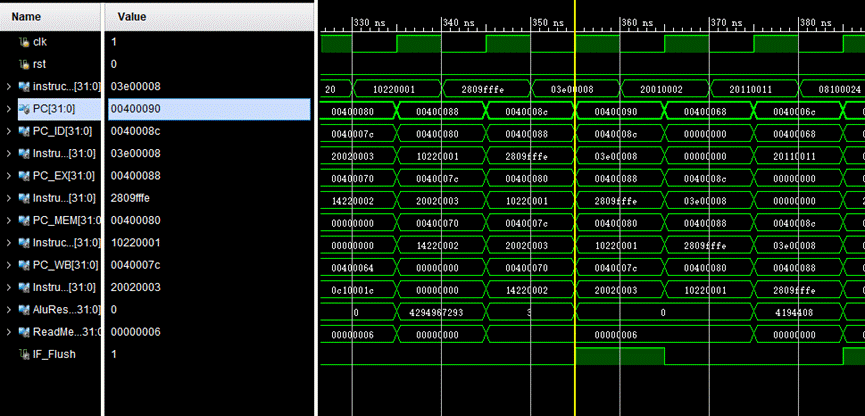
图中我们可以看到在0x40008c后先是顺序读取到了0x400090,因为在IF阶段无法得知是jr指令,只有在ID阶段解码后得到Opcode才可以知道,在下一个周期, 0x40008c的指令进入了ID阶段,此时经过阶码得知是jr指令,所以会冲刷IF阶段IF/ID寄存器中指令,让PC回到ID阶段的PC并且计算分支地址(在NextPC中处理),在下一个周期既可以得到正确的PC值,然后取出对应的指令继续运行。
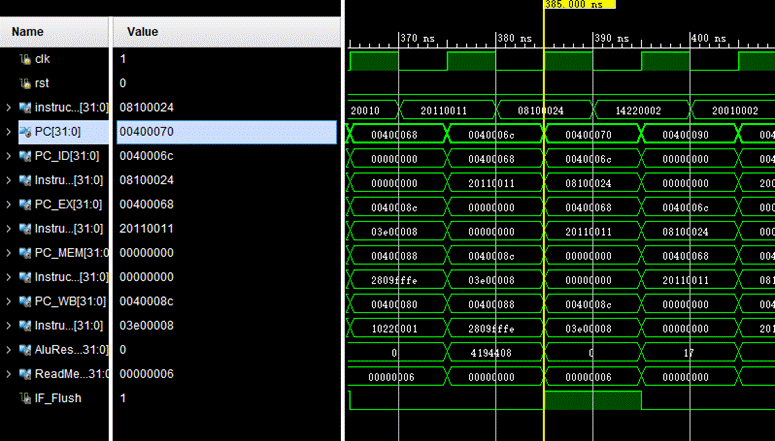
3.0x400070为bne指令:bne $1,$2,notequal #jal here 此时$1的值为6,$2的值为3,要发生跳转,到0x40007c的位置,图中可以看出下一条指令地址为0x40007c,说明成功跳转且可以分辨bne和零标志,因为bne是零标志位1时跳转
并且由于我们采用了分支预测,即遇到branch指令的时候总是先在IF阶段预判跳转发生,所以在下一个IF阶段的PC是branch发生时候的PC,然后等当前的branch指令进入ID阶段阶码并且判断寄存器中的值是否相等,如果符合branch的跳转指令,那么预测成功,继续执行,如果预测失败,即IF阶段中应该不是branch跳转的地址,而是顺序执行,所以我们要冲刷掉IF阶段中取出的指令(冲刷IF/ID寄存器),然后将ID阶段的PC+4拿回到IF阶段(因为流水线寄存器中存的就是当前指令的PC)作为下一个周期IF的取指令地址
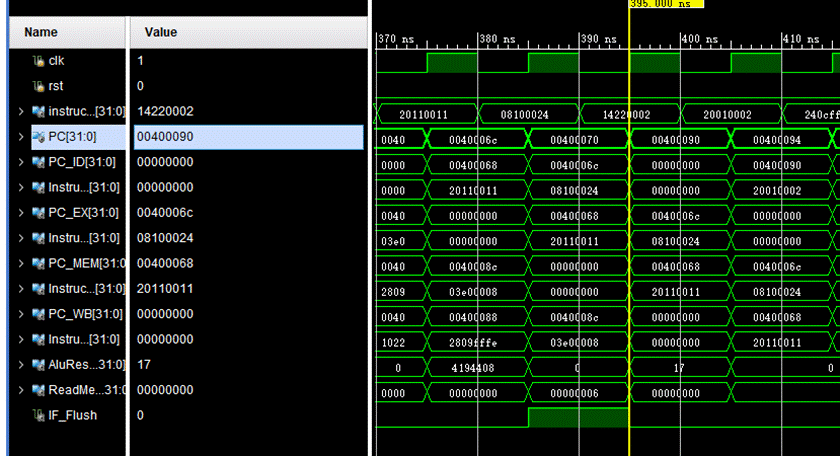
4.0x400080为beq指令:beq $1,$2,equal,此时$1=6,$2=6,会发生跳转,跳转到0x400088的位置,而图中可看出beq下一条指令地址为0x40088,说明成功跳转,也说明了可以区分beq和零标志。只有beq和零标志为0的才会发生跳转。
图中我们可以看到分支预测是成功的,所以不需要冲刷,若预测不成功,做法同上
5.0x40006c是j指令,需要跳转到0x400090的位置,但是在IF阶段并不知道是j型的跳转指令,所以会先按顺序PC+4更新PC,然后读取指令,但是跳转指令到ID阶段时,会解码得出Opcode是跳转指令,此时会将IF中指令冲刷掉,根据J型指令解码的值重新计算PC,然后交给IM取值,重新开始IF阶段。(遇到了控制竞争现象并解决)
图中最后一条IF_Flush在00400070处为1,说明要冲刷掉数据,阻塞一个周期,等下一周期获得正确的PC再取指令,具体过程见jal指令的分析和jr指令的分析
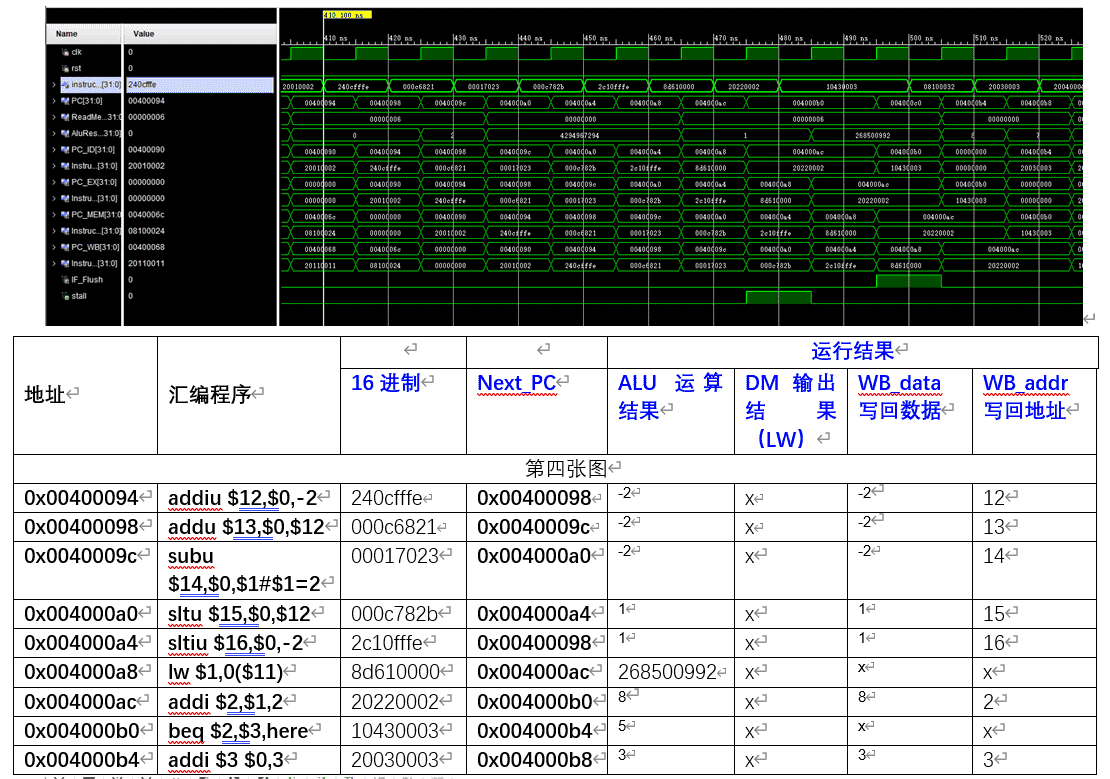
6.还有需要注意的是slti和sltiu,slt和sltu的区别,就是有符号数比较和无符号数比较,这里以slti和sltiu为例:
Instruction_ID:0x400088处为slti:slti $9,$0,-2 #beq here,此时运算结果为0,说明0>-2,所以不小于
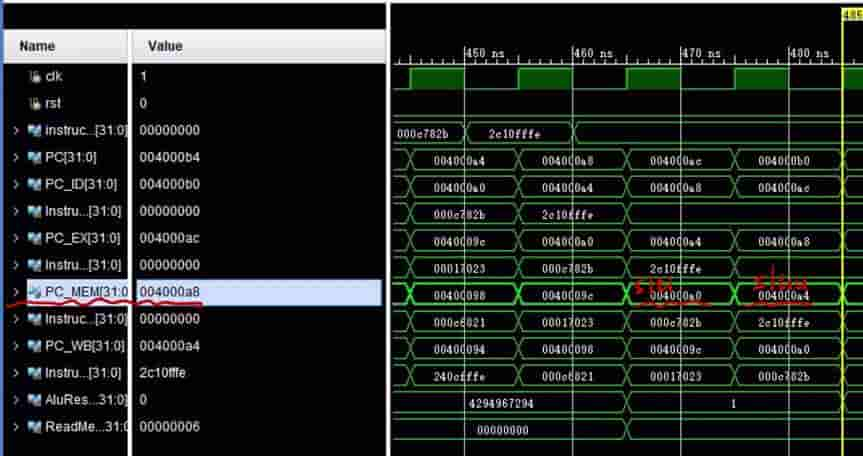
Instruction_ID:0x4000a4(上图)处为sltiu:sltiu $16,$0,-2,此时运算结果为1,说明0<-2成立,这是因为-2以补码形式储存,实际存储的值是fffe,有因为是无符号比较,所以不会认为是-2,而是fffe,即0<fffe,所以可以实现有符号比较和无符号比较
7.装入使用冒险:
0x004000a8:lw $1,0($11)
0x004000ac:addi $2,$1,2
发生了装入使用冒险,会插入一个阻塞的周期,即清空 ID-EX 流水段的控制信号, 并且保持 IF-ID 流水段的值不变以及保持PC 值不变

图中可以看到addi的后一条指令,即PC=0x004000b0的指令持续了两个周期,就是阻塞了一个周期,使得lw的值写入寄存器后再让流水线继续执行,并运算正确
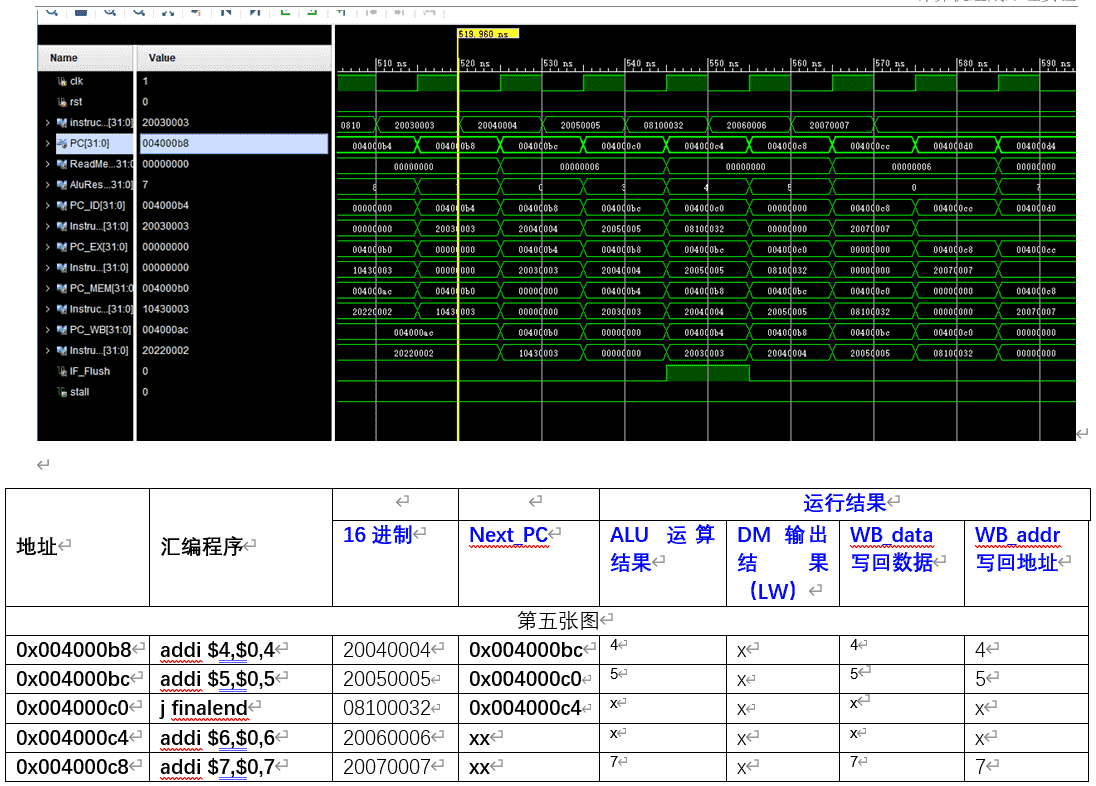
8.分支预测失败,0x004000b0:beq $2,$3,here,此处不会发生跳转
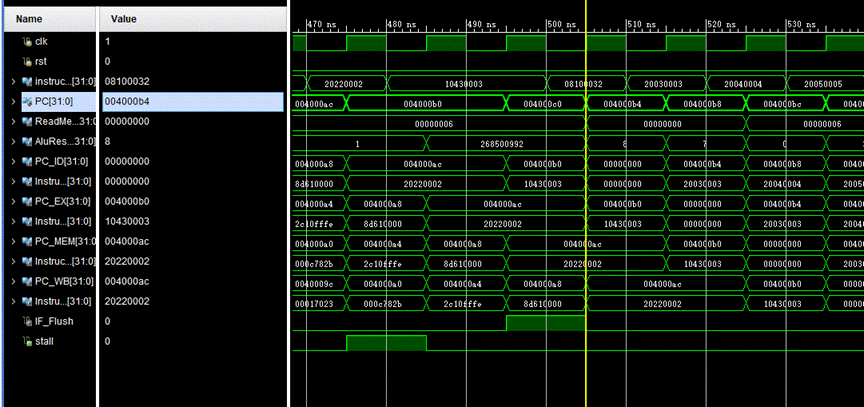
图中可以看到,遇到分支指令我们默认是会发生跳转,所以下一条指令不是顺序执行,而是取到了跳转后的PC,0x004000c0,但是等取到之后的下一个周期,即beq进入ID阶段发现不需要跳转,于是将IF/ID寄存器数据冲刷掉,将在ID阶段中指令的PC+4传回给NextPC(寄存器中存的都是当前指令的PC)
地址 | 汇编程序 | 运行结果 | ||||||
16进制 | Next_PC | ALU运算结果 | DM输出结果(LW) | WB_data写回数据 | WB_addr写回地址 | |||
0x00400000 | lui $1,4097 | 3c011001 | 0x00400004 | 268500992 | x | 268500992 | 1 | |
0x00400004 | ori $11,$1,0 | 342b0000 | 0x00400008 | 268500992 | x | 268500992 | 11 | |
0x00400008 | addi $1,$0,1 | 20010001 | 0x0040000C | 1 | x | 1 | 1 | |
0x0040000C | add $2,$1,$1 | 00211020 | 0x00400010 | 2 | x | 2 | 2 | |
0x00400010 | sub $3,$2,$1 | 00411822 | 0x00400014 | 1 | x | 1 | 3 | |
0x00400014 | add $1,$2,1 | 20410001 | 0x00400018 | 3 | x | 3 | 1 | |
0x00400018 | addi $2,$0,6 | 20020006 | 0x0040001C | 6 | x | 6 | 2 | |
0x0040001C | and $4,$1,$2 | 00222024 | 0x00400020 | 2 | x | 2 | 4 | |
0x00400020 | or $4,$1,$2 | 00222025 | 0x00400024 | 7 | x | 7 | 4 | |
0x00400024 | xor $4,$1,$2 | 00222026 | 0x00400028 | 5 | x | 5 | 4 | |
0x00400028 | nor $4,$1,$2 | 00222027 | 0x0040002C | -8 | x | -8 | 4 | |
0x0040002C | slt $5,$1,$2 | 0022282a | 0x00400030 | 1 | x | 1 | 5 | |
0x00400030 | sll $5,$2,2 | 00022880 | 0x00400034 | 24 | x | 24 | 5 | |
0x00400034 | srl $5,$2,1 | 00022842 | 0x00400038 | 3 | x | 3 | 5 | |
0x00400038 | sra $5,$2,1 | 00022843 | 0x0040003C | 3 | x | 3 | 5 | |
0x0040003C | sllv $5,$2,$1 | 00222804 | 0x00400040 | 48 | x | 48 | 5 | |
0x00400040 | addi $10,$0,1 | 200a0001 | 0x00400044 | 1 | x | 1 | 10 | |
0x00400044 | srlv $5,$2,$10 | 01422806 | 0x00400048 | 3 | x | 3 | 5 | |
0x00400048 | srav $5,$2,$10 | 01422807 | 0x0040004C | 3 | x | 3 | 5 | |
0x0040004C | andi $6,$1,6 | 30260006 | 0x00400050 | 2 | x | 2 | 6 | |
0x00400050 | ori $6,$1,6 | 34260006 | 0x00400054 | 7 | x | 7 | 6 | |
0x00400054 | xori $6,$1,6 | 38260006 | 0x00400058 | 5 | x | 5 | 6 | |
0x00400058 | lui $7,1 | 3c070001 | 0x0040005c | 65536 | x | 65536 | 7 | |
0x0040005c | sw $2,0($11) | ad620000 | 0x00400060 | 268500992 | x | x | x | |
0x00400060 | lw $8,0($11) | 8d680000 | 0x00400064 | 268500992 | 6 | 6 | 8 | |
0x00400064 | jal BranchTest | 0c10001c, | 0x00400070 | xx | x | x | x | |
0x00400068 | addi $17,$0,17 | 20110011 | 0x0040006c | 17 | x | 17 | 17 | |
0x0040006c | j end | 08100024 | 0x00400090 | xx | x | x | x | |
0x00400070 | bne $1,$2,notequal #jal here | 14220002 | 0x0040007c | -3 | x | x | x | |
0x00400074 | addi $18,$0,18 #不运行 | 20120012 | xx | xx | x | x | xx | |
0x00400078 | addi $19,$0,20 #不运行 | 20130014 | xx | xx | x | x | xx | |
0x0040007c | addi $2,$0,3 #bne here | 20020003 | 0x00400080 | 3 | x | 3 | 2 | |
0x00400080 | beq $1,$2,equal | 10220001 | 0x00400088 | 0 | x | x | x | |
0x00400084 | addi $19,$0,19#不运行 | 20130013 | xx | xx | x | x | xx | |
0x00400088 | slti $9,$0,-2 #beq here | 2809fffe | 0x0040008c | 0 | x | 0 | 9 | |
0x0040008c | jr $31 #回到jal branch的下一条 | 03e00008 | 0x00400068 | xx | x | x | x | |
0x00400090 | addi $1,$0,2 #j here | 20010002 | 0x00400094 | 2 | x | 2 | 1 | |
0x00400094 | addiu $12,$0,-2 | 240cfffe | 0x00400098 | -2 | x | -2 | 12 | |
0x00400098 | addu $13,$0,$12 | 000c6821 | 0x0040009c | -2 | x | -2 | 13 | |
0x0040009c | subu $14,$0,$1#$1=2 | 00017023 | 0x004000a0 | -2 | x | -2 | 14 | |
0x004000a0 | sltu $15,$0,$12 | 000c782b | 0x004000a4 | 1 | x | 1 | 15 | |
0x004000a4 | sltiu $16,$0,-2 | 2c10fffe | 0x004000a8 | 1 | x | 1 | 16 | |
0x004000a8 | lw $1,0($11) | 8d610000 | 0x004000ac | 268500992 | x | x | x | |
0x004000ac | addi $2,$1,2 | 20220002 | 0x004000b0 | 8 | x | 8 | 2 | |
0x004000b0 | beq $2,$3,here | 10430003 | 0x004000b4 | 5 | x | x | x | |
0x004000b4 | addi $3 $0,3 | 20030003 | 0x004000b8 | 3 | x | 3 | 3 | |
0x004000b8 | addi $4,$0,4 | 20040004 | 0x004000bc | 4 | x | 4 | 4 | |
0x004000bc | addi $5,$0,5 | 20050005 | 0x004000c0 | 5 | x | 5 | 5 | |
0x004000c0 | j finalend | 08100032 | 0x004000c4 | x | x | x | x | |
0x004000c4 | addi $6,$0,6 | 20060006 | xx | x | x | x | x | |
0x004000c8 | addi $7,$0,7 | 20070007 | xx | 7 | x | 7 | 7 | |
4.Basys 3板操作方法
顶层文件输入有6个,
clk接板子上的时钟
step接板子上的SW15,模拟一个上升沿和下降沿
clkORstep接板子上的SW14,为1则是连续运行,时钟为板子上时钟clk,为0则为单步运行,用step驱动
reset接板子上的SW13,为1时,在上升沿来到时清零,为0时,则正常运行
SW2来选择显示数据的高16位和低16位,为1则显示高16位,为0则显示低16位
SW1和SW0同时选择显示的数据:00则为instruction,01则为PC,10则为ALU计算结果,11则为DM中取出来的值
输出有7个
sm_duna选择一个数码管的显示,sm_wei选择是哪一个数据管,数据在4个数码管上显示,显示高16位或者低16位
而输出标志有溢出标志
5.Basys 3板运行CPU
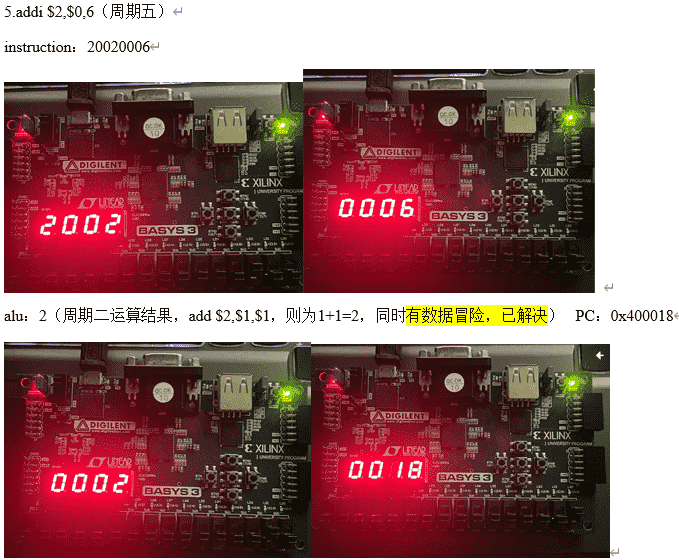
例子:(以下例子的周期几只是相对于例子而言,第一条指令选择从20010001开始)








六. 流水线实验心得(在吸收单周期实验心得下)
1.测试的汇编程序与测试单周期的几乎一样,只是最后增加了Load-Use冒险和分支预测失败的情况,来检测设计是否可行,所以节省了重新写测试汇编程序的时间
2.单周期:在做CPU的时候,我是一类指令一类指令的写的,在开始之前并没有总体规划,所以导致其实很多可以单独用到MUX的地方,都是在顶层文件通过两步来完成的,例如:
1
2
3
assign regWriteAddr = reg_dst ? instruction[15:11] : instruction[20:16];
assign WB_addr = (jal==1'b1)?5'b11111:regWriteAddr;
本来是可以用3选一选择器使得CPU的结构更加的清晰,但是由于没有增加jal指令之前写回地址只有rt和rd,所以只用了一个三元运算符,但是增加jal指令后就要增加31号寄存器,但是要是临时增加一个3选一的MUX又要改很多地方,所以就保留了上述这种不利于阅读的方法,自己看还好,但是不利于其他人的理解。
所以在开始设计CPU的时候最好先花一点时间看看自己都需要哪一些部件,能抽象成为一个模块的最好都抽象出来,便于阅读,也便于自己的修改。
流水线:CPU中,由于吸收了单周期CPU设计时遇到的这个问题,所以开始写verilog之前先认真分析了需要的信号的模块,首先确定了需要完成单周期中已经完成的31条指令,然后将一些在top文件中零散的代码集成为模块,只需要接接线即可,便于流水线的接线
3.传入IM的值是PC[9:2],因为IM中根据字地址寻找指令,而我们规定了数据深度为256位,因此只需要2^8=256,第二位到第九位这8位数就可以了
4.仿真遇到zzzz(高阻态),一般是没有在仿真激励文件中例化。遇到xxxx是因为没有取到值。
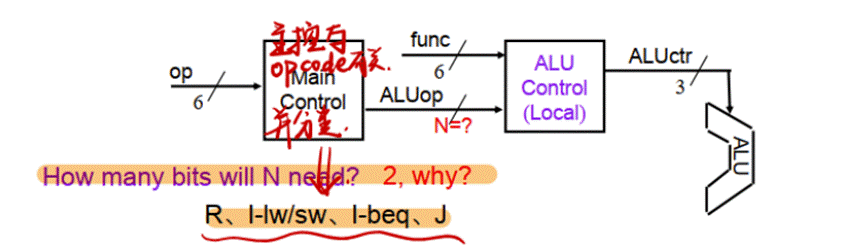
5.为了简化控制器的设计,因此将MainControl和ALUcontrol合成为一个ControlUnit,因为我们分为两个是因为控制器是一个庞大的逻辑电路,所以硬件上实现的时候我们分成两个两个较小的逻辑电路,在Maincontrol中分类指令,在ALUControl中确定ALU运算信号,如下图:
我在单周期中也是这样设计的,所以在流水线中想尝试一下用一个大的模块来完成。
6.由于在开始写代码之前已经确定了要做31条指令,所以就没有像单周期一样把j,jal,jr,branch都列一条信号出来,而是都集成在JumpSignal中,简化了接线。
7.在完成数据转发和Load-Use冒险时,Object的debug功能帮了很大的忙,就不需要再顶层文件先output,然后在激励文件中例化才可以看到了,直接在Run Simulation后,点Scope的模块,在Objects中找到想显示的接线,然后Add to Wave Window,就可以在左边看到,然后点一下最上面一行的圆圈箭头,刷新后即可看到:
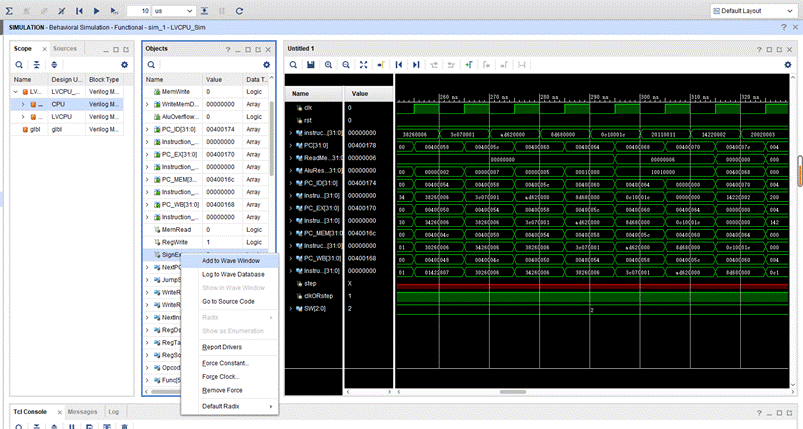
8.提前想好需要什么模块可以省略重复代码,例如MUX4,有7个模块都可以用同一个代码,只需要例化就可以。
9.当仿真报错时直接查看Tcl Console窗口的第一个error:……,因为之后的代码很可能是因为第一个错误引起的,如果不知道报错是怎么意思的话,直接赋值到搜索引擎,一般都可以获得解答,例如我第一次综合的时候报错:multiple driver nets: net cpu/bpm/q[0] has multiple drivers:,然后我搜索了才知道是因为我在一个模块里两次用always来给同一个变量赋值导致错误,因为寄存器输入端是由触发器组成的,用两个always块这个寄存器进行赋值,无论其中经过了怎样的条件判断,最终结果毫无疑问是将两个相独立的触发信号连在了寄存器的CLK端上,一端口接入两信号,这显然已经不是一个符合标准的数字逻辑电路了。所以这样的语句是无法被综合成电路的。
10.当只有一种情况的时候,直接使用assign语句,千万不要使用always@(*)块直接assign WBaddr=5’d0;
11.区分output和output reg
output对应assign语句赋值的变量
output reg对应always @(*)块赋值的变量
如果将assign改为always@(*)块,记得将output改为output reg
12.记得所有if_else语句最后要加else begin_end,避免产生锁存器