4-4 流水线冒险处理
流水线需要能够检测和处理竞争问题
- 结构竞争—硬件资源使⽤冲突(即同一周期使用同一部件)
- 已解决:1.指令和数据分开存储。2.寄存器读口和写口分开
-
数据竞争—数据存储器或者寄存器内容因指令关联⽽不可获得RAW(写后读冒险) , load-use(装入使用冒险)
- 控制竞争—因跳转分⽀指令(beq、bne、j、jr、jal)使得PC⽆法及时确定
流⽔线的控制信号:控制信号如何随流⽔线运⾏?
流水线控制信号设计
- 将各个资源和状态(流⽔级)联系起来
- 从设计上要避免structural hazards的出现: 保证资源是够⽤的
- 在各个级别之间增加寄存器
- 找到所有的数据竞争和控制竞争问题
- 如果是寄存器关联引起的=> data hazard: forward or stall to resolve them
- 如果是和PC有关的竞争=> control hazard: we’ll see next time
- 在合适的阶段使控制信号有效
- 合适的测试设计
- if you don’t test it, it won’t work
数据竞争和控制竞争问题
- 如果是寄存器关联引起的=> data hazard: forward or stall to resolve them
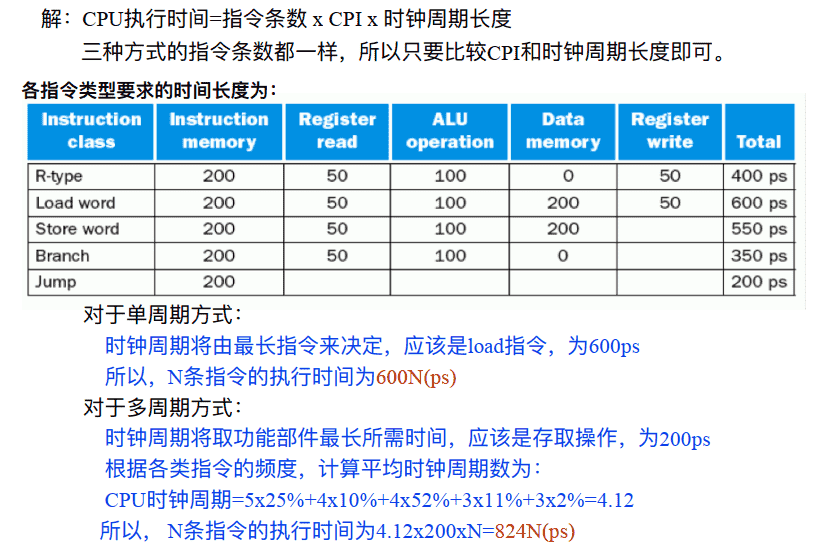
- RAW型 写后读 数据冒险
- load-use型 装入使用冒险
- 如果是和PC有关的竞争=> control hazard:
数据竞争
数据竞争有两种:
- 读后写:可以完全用转发处理,不需要阻塞
- 装入使用:需要阻塞一个周期
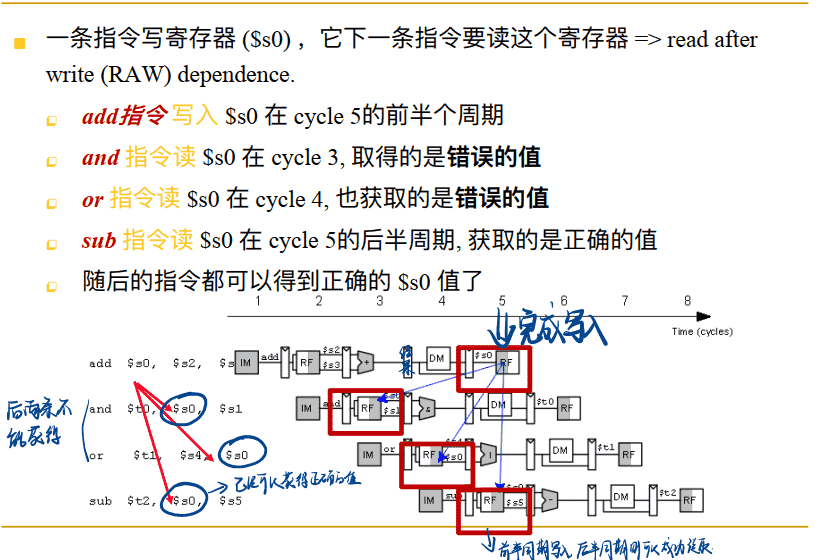
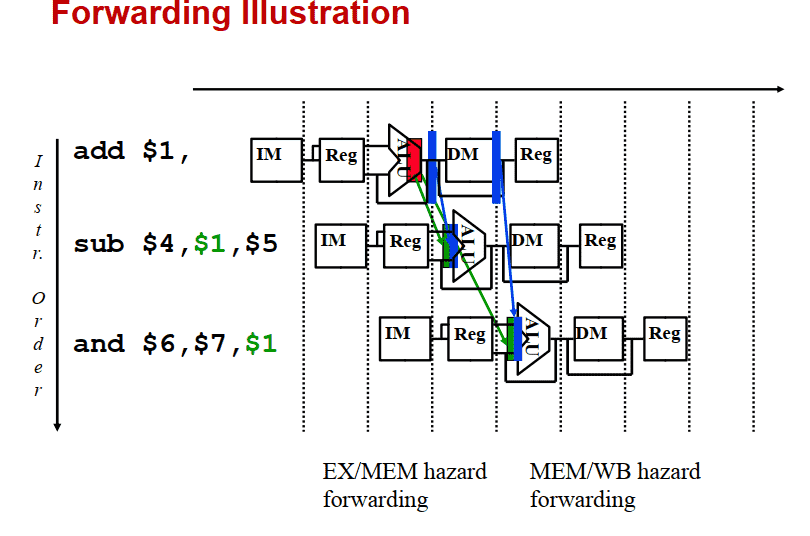
RAW (写后读) 数据冒险–可由转发处理
解决
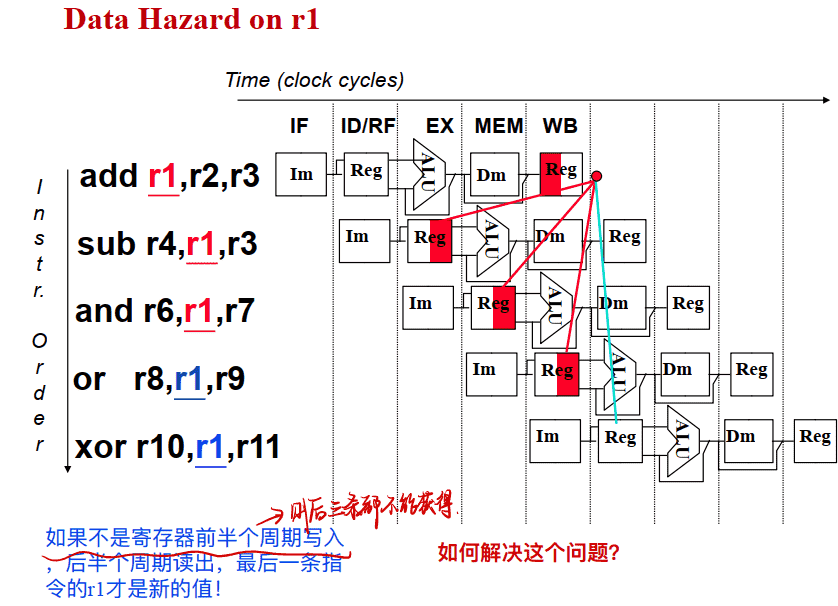
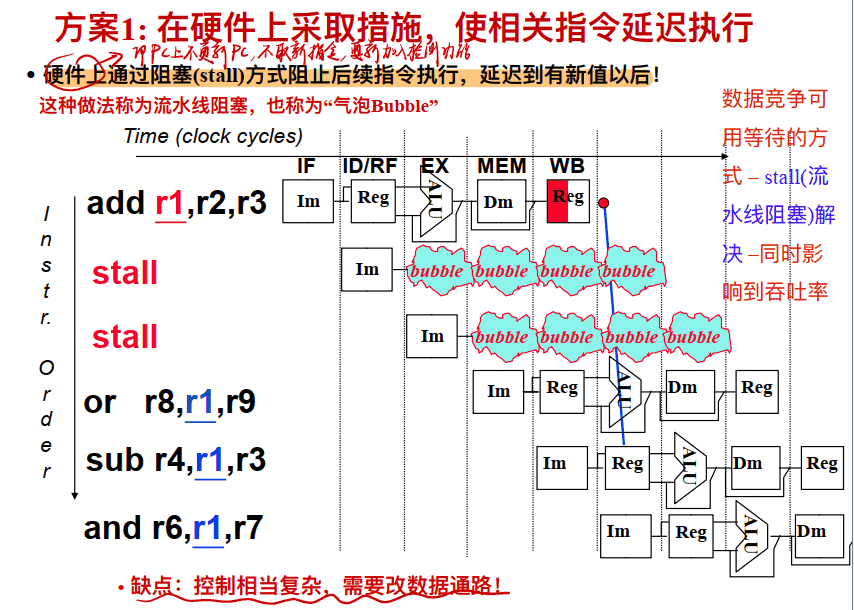
方案1: 在硬件上采取措施, 使相关指令延迟执行
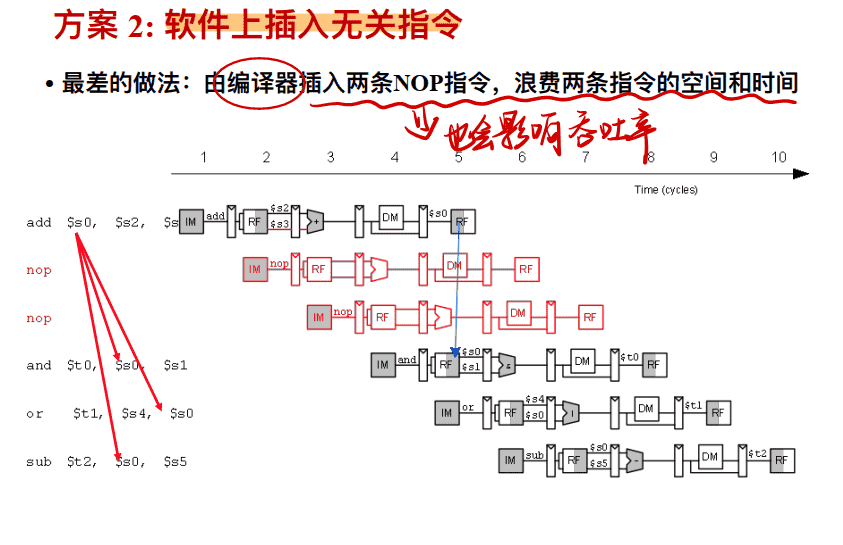
⽅案 2: 软件上插⼊⽆关指令
方案3(最优): 利用DataPath中的中间数据转发(Forwarding)处理(也叫旁路Bypassing)
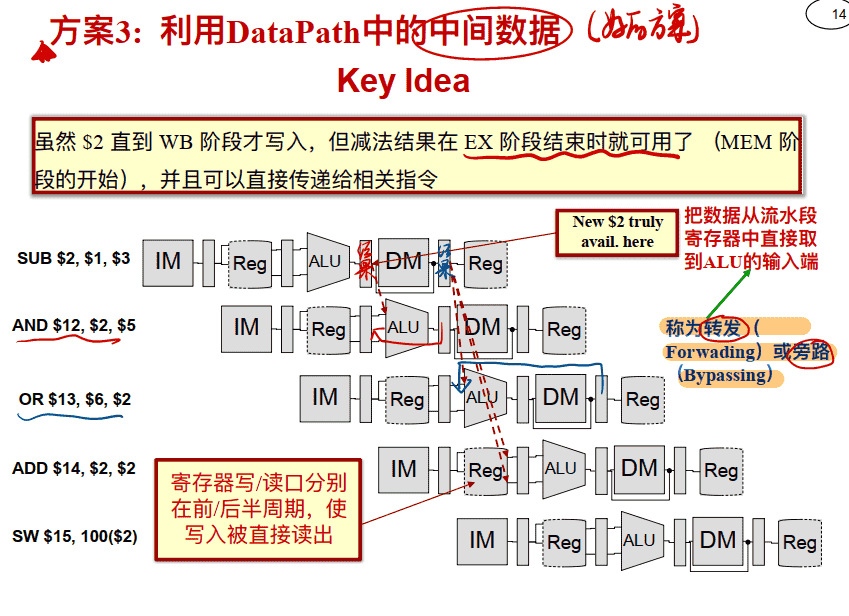
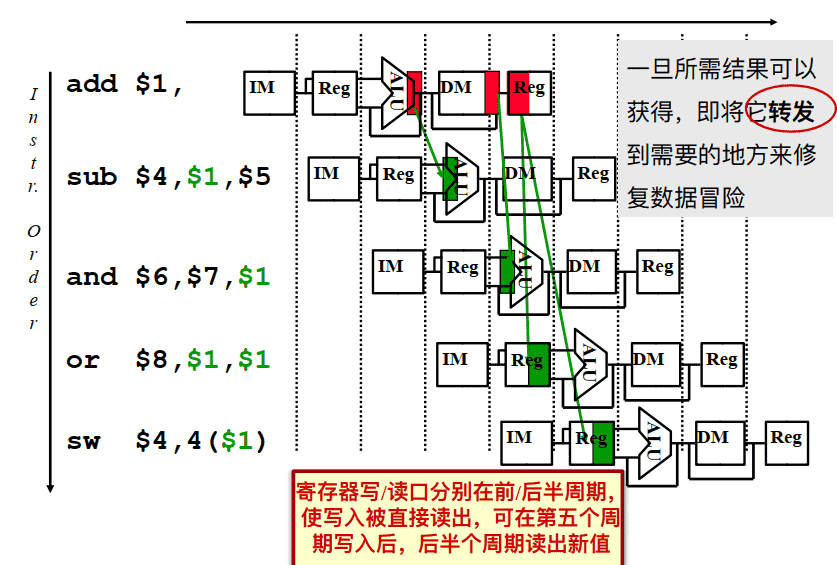
转发处理 Data Forwarding (aka Bypassing) 介绍
- 从存在于任何流⽔线状态寄存器中的数据最早点获取结果, 并将其转发给该周期需要它的功能单元(例如, ALU)
- 对于 ALU 功能单元: 输⼊可以来⾃任何流⽔线寄存器, ⽽不仅仅是来⾃ ID/EX, 通过 • 对ALU的输⼊端加选择器 • 把在EX/MEM 或 MEM/WB 流⽔线寄存器中的Rd写数据连接到执⾏阶段ALU的Rs或者Rt选择输⼊端 • 添加合适的硬件控制选择器
- 其他功能单元可能需要类似的转发逻辑(例如, DM) 即使在存在数据依赖关系的情况下, 使⽤转发也可以实现 CPI 为1
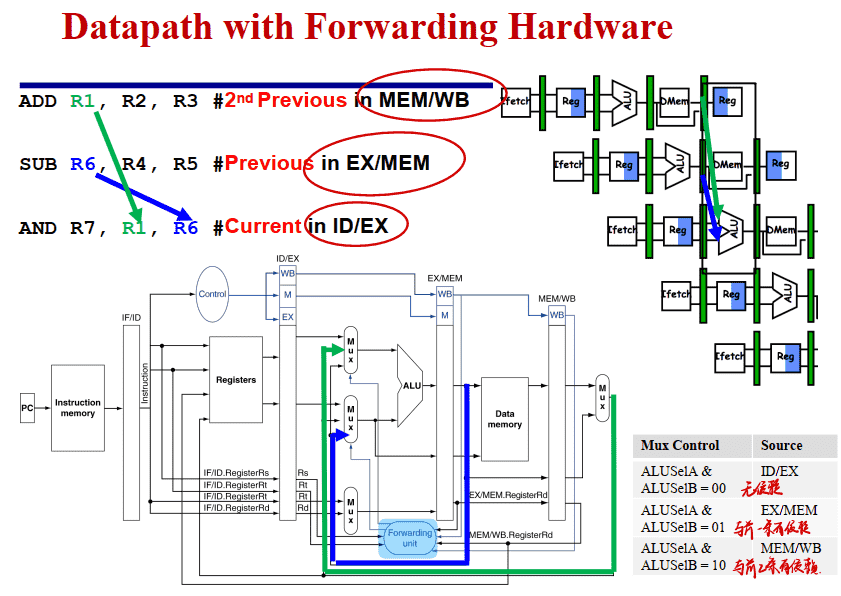
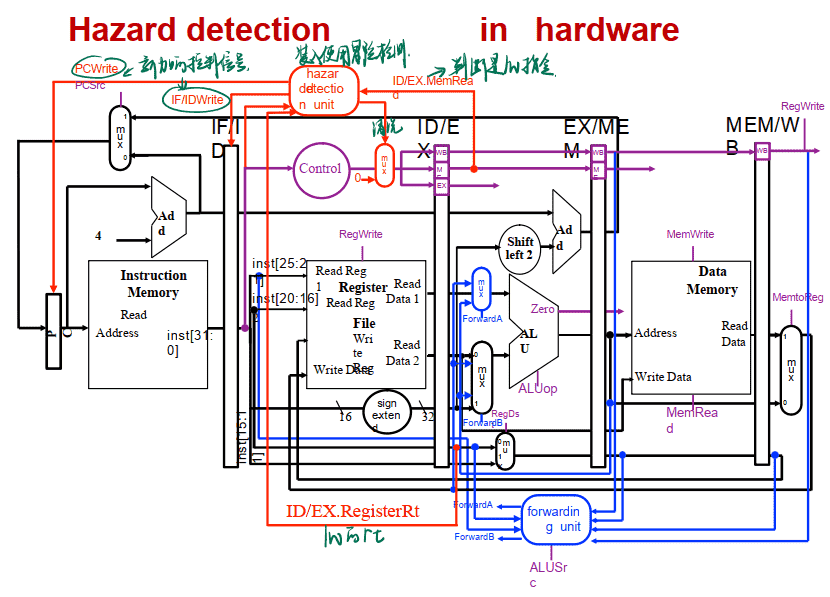
硬件实现转发
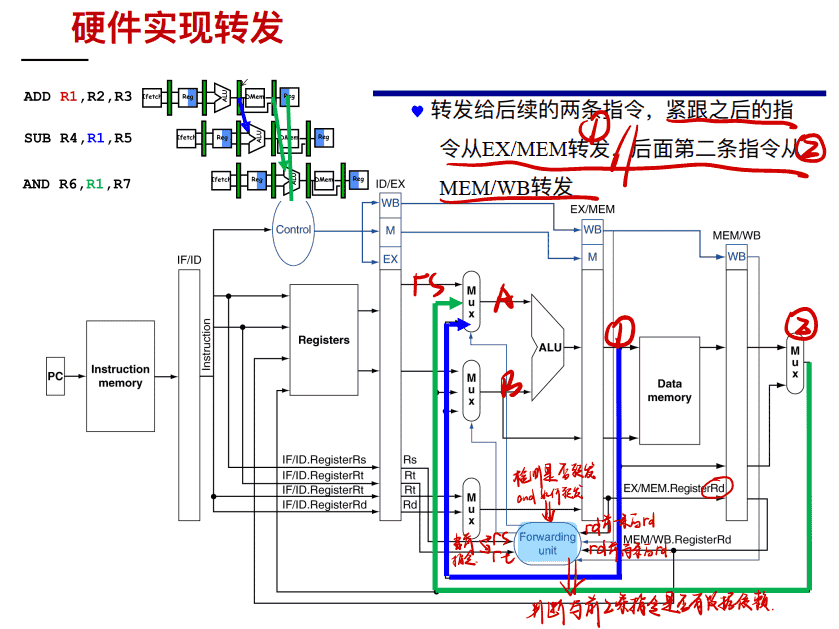
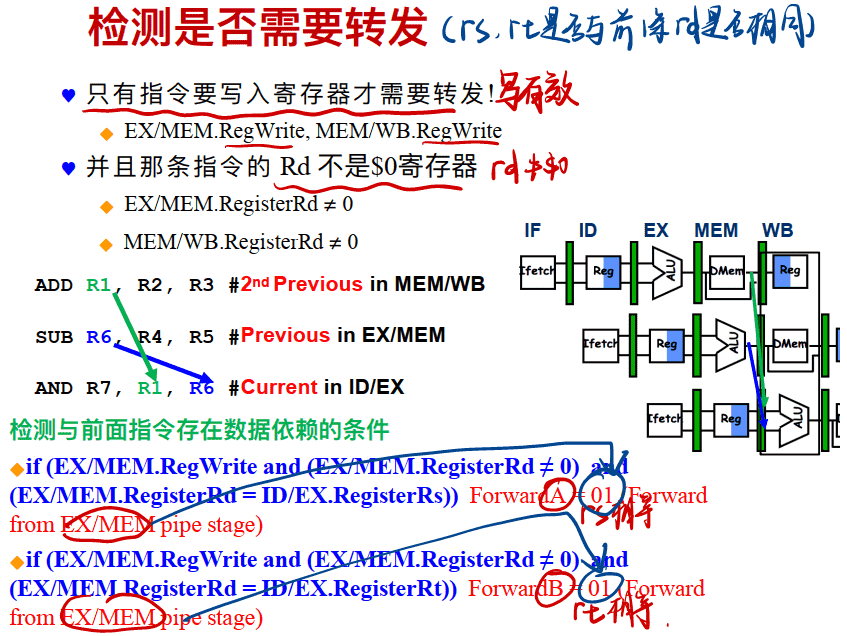
检测 RAW 冒险
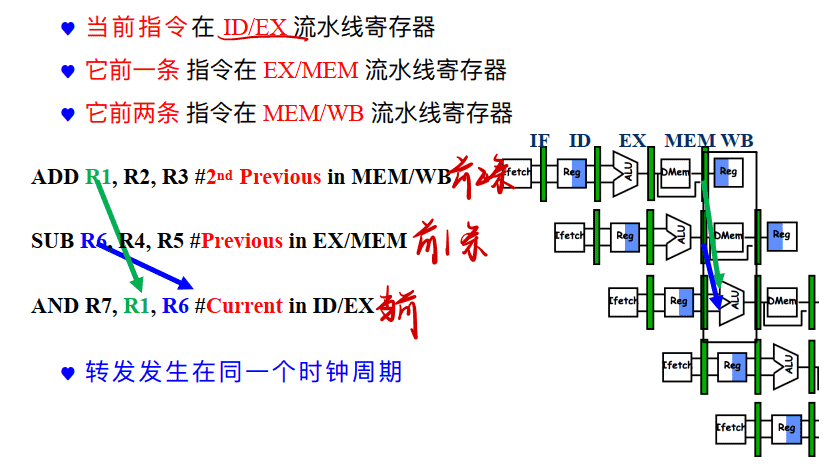
转发处理:
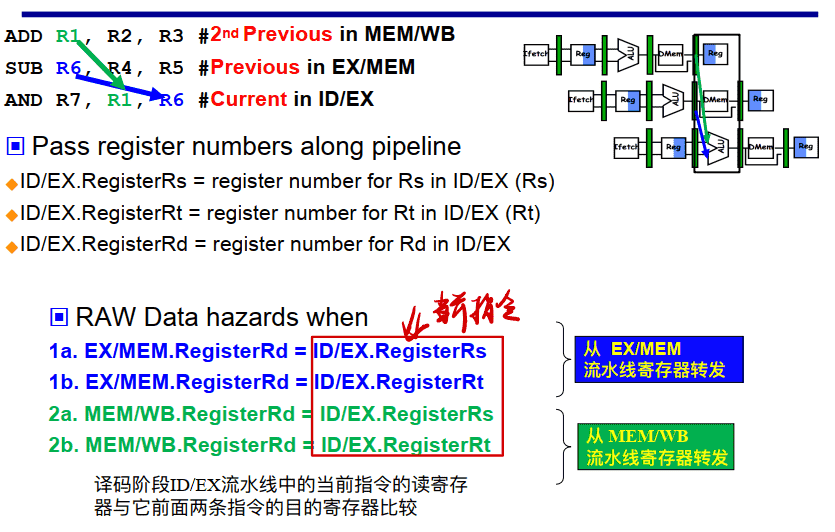
检测是否需要转发
==即如果ID/EX的Rs或Rt等于EX/MEM中的Rd,则要从EX/MEM寄存器转发==
==若ID/EX的Rs或Rt等于MEM/WB中的Rd,则要从MEM/WB寄存器转发==
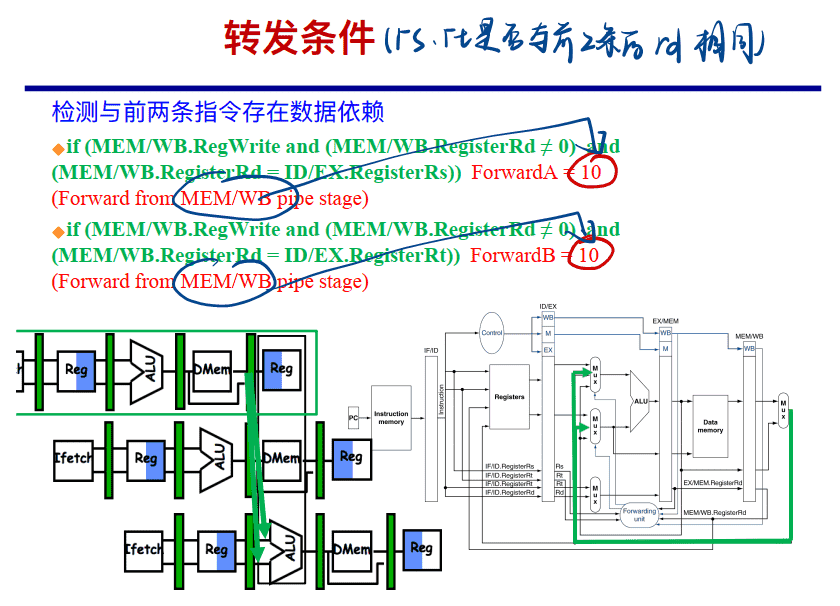
加了转发的数据通路图(不完全)
例子:
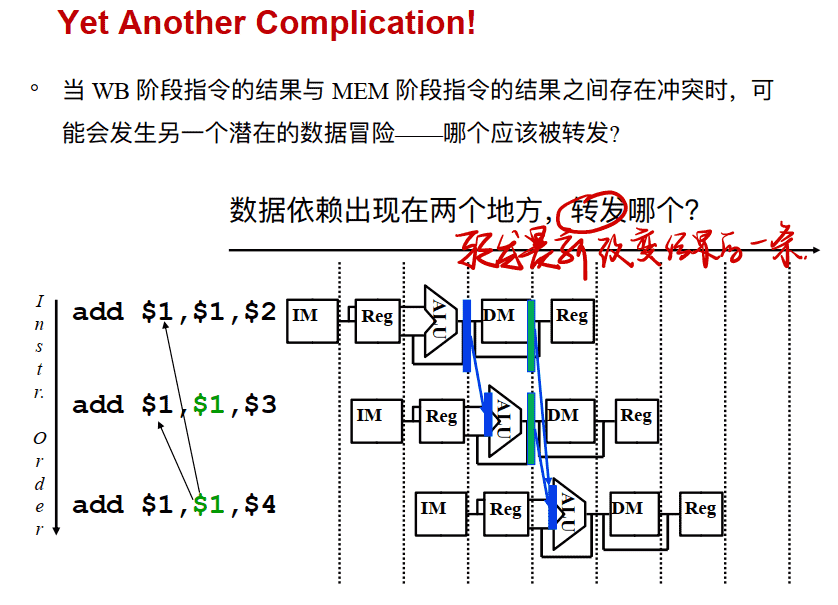
Yet Another Complication!
Corrected Data Forwarding Control Conditions

原本:
==即如果ID/EX的Rs或Rt等于EX/MEM中的Rd,则要从EX/MEM寄存器转发==
==若ID/EX的Rs或Rt等于MEM/WB中的Rd,则要从MEM/WB寄存器转发==
为了保证是最新的,还要保证一点:
==ID/EX的Rs或Rd(本条)等于MEM/WB中Rd(上两条)且不等于EX/MEM中的Rd(上一条)==
有了转发转置的数据通路图(完全)
Load-Use 装入使用冒险–转发不能解决所有数据冒险
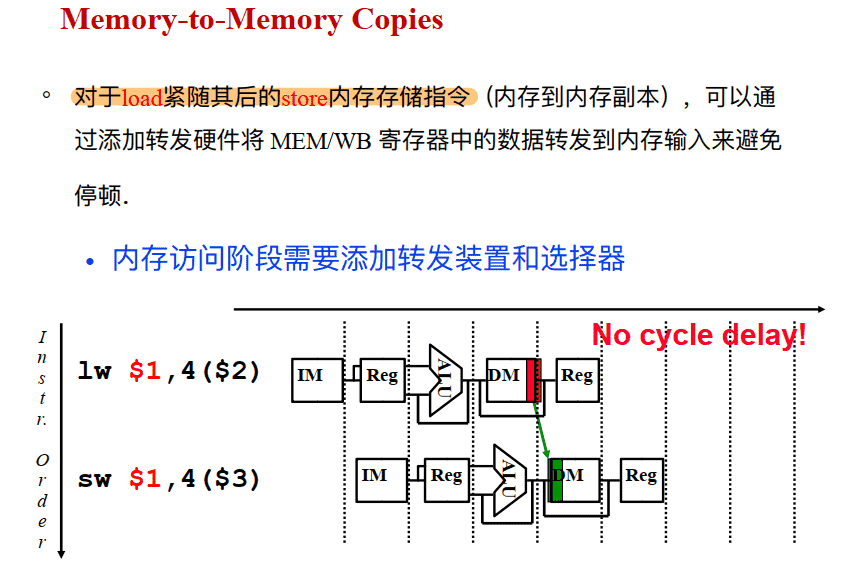
==lw指令必须阻塞一个周期,但是如果lw后是sw,则不用==
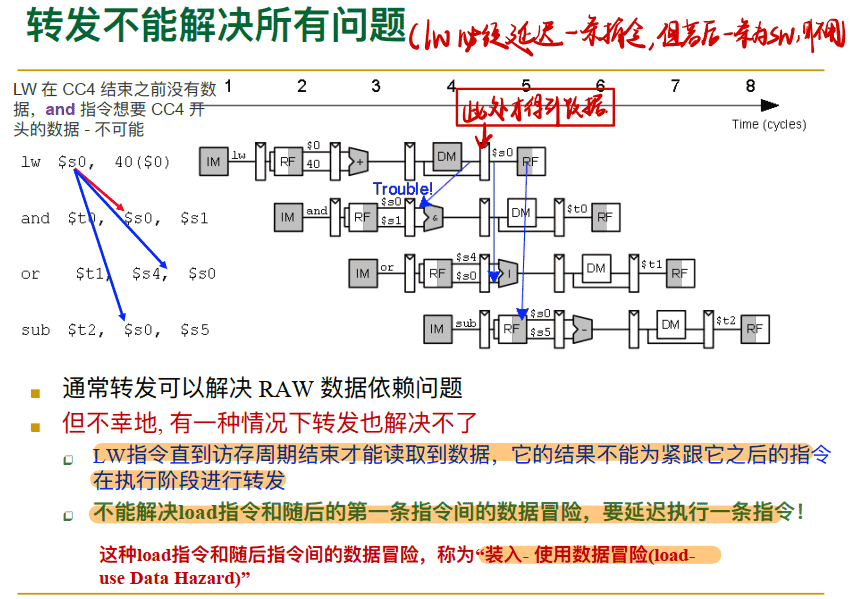
==lw指令后的数据冒险是装入使用冒险,无法用转发处理,必须阻塞一个周期==
例子:
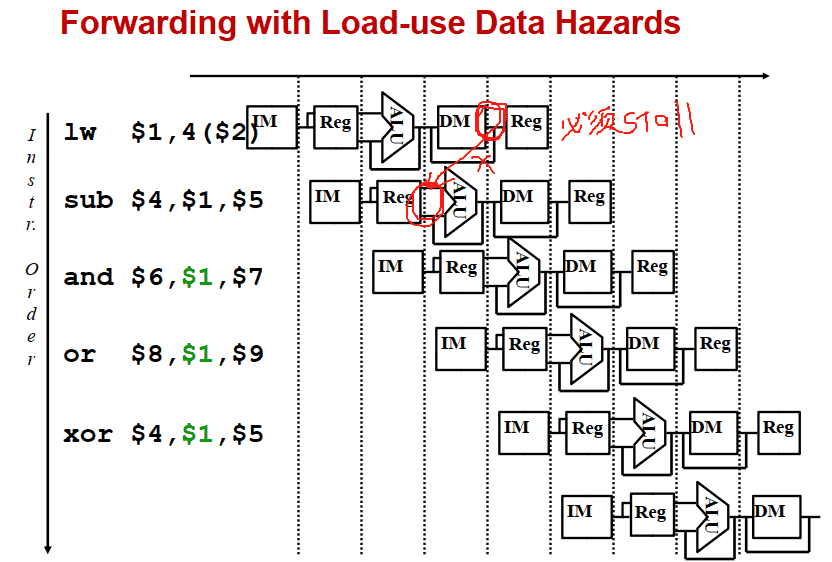
装入使用冒险 Load-use Hazard 检测

==如果lw指令后的第一条指令的Rs或Rt(在IF/ID中)与lw指令的Rt(lw的写入寄存器是Rt,在ID/EX中)相同,那么即要阻塞一个周期以解决装入使用冒险==(当前指令在IF/ID寄存器,前一条指令在ID/EX寄存器)
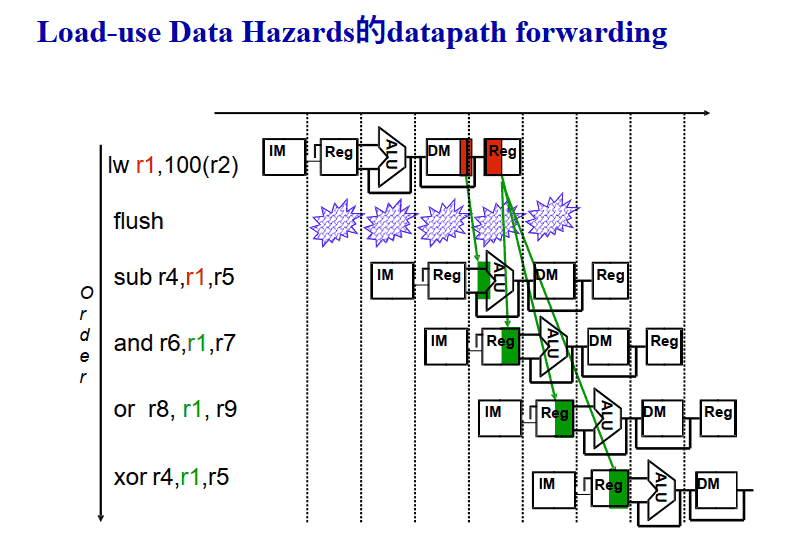
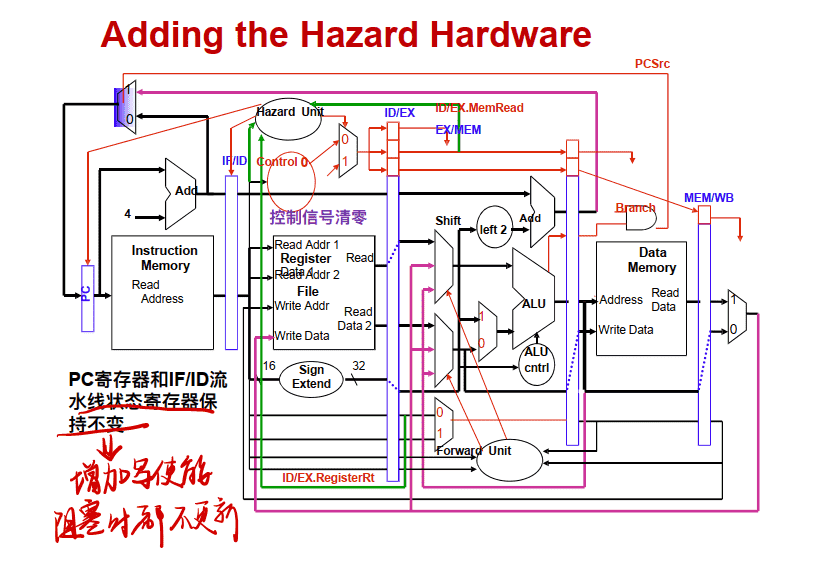
如何实现Stall 阻塞?
- 装入使用冒险必须实现阻塞功能才能使forward发挥作⽤
- 阻⽌IF and ID 阶段的指令进⼊EX阶段执⾏, 只要不让PC寄存器变化和IF/ID流⽔线状态寄存器保持不变就可以了
- 只要让前⾯的hazard检测电路来控制这些寄存器的写⼊就可以了
- 从EX开始的后半段在阻塞时应处于清空状态:执⾏NOP(为了不改变寄存器中的值,之后的指令要洗刷掉)
- 将 ID/EX pipeline register中与EX,MEM,WB有关的控制信号清零,不⼯作状态
- 由Hazard检测电路控制选择使⽤正常的控制信号还是直接为0.
- 假定控制信号为0总是使电路不⼯作或者不影响电路状态的变化
Adding the Hazard Hardware
方案4: 编译器进行指令顺序调整来解决load-use
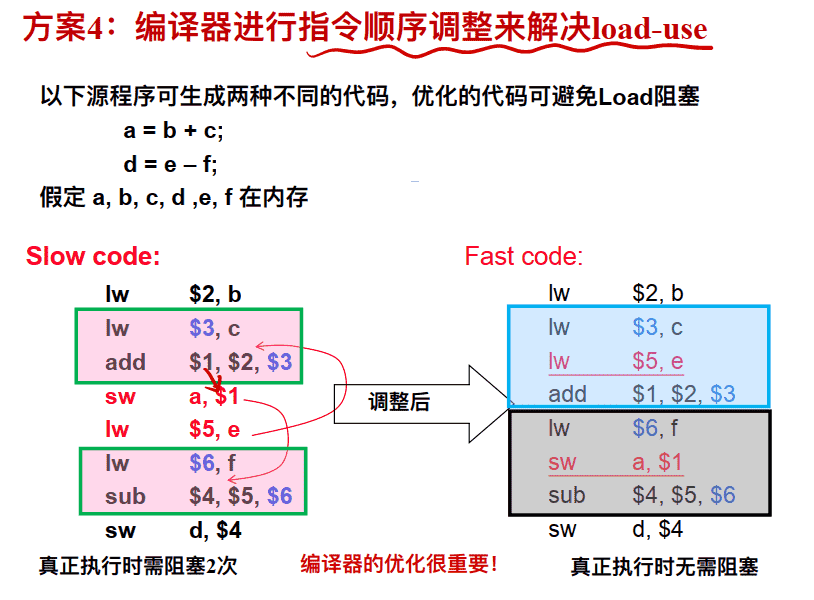
编译器进⾏指令顺序调整例子 :
例1:
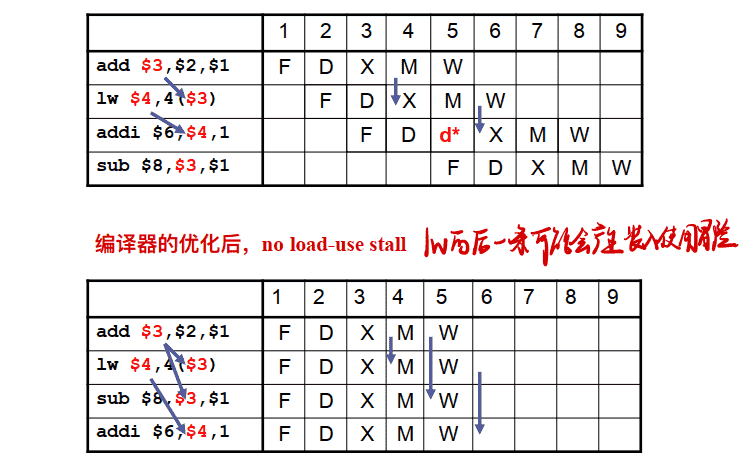
例2:

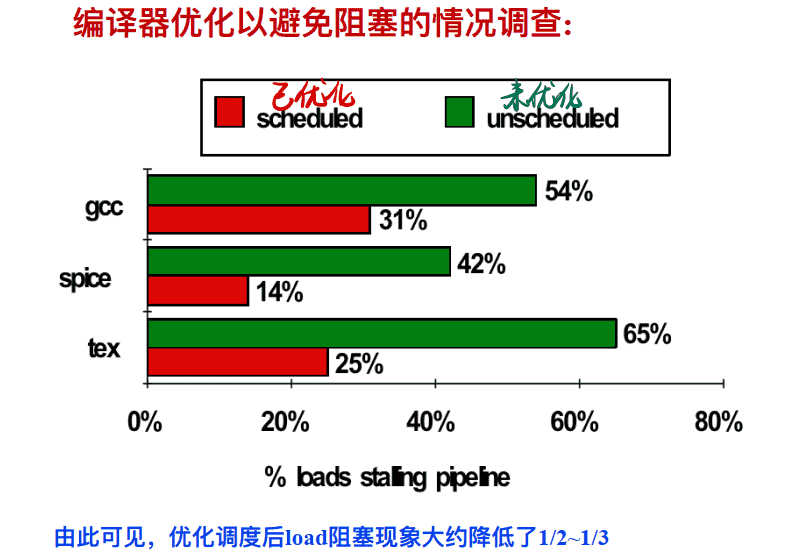
编译器优化以避免阻塞的情况调查:
总结: 数据冒险的解决方法
-
⽅法1: 合理实现寄存器堆的读/写操作(已经是解决结构冒险的方法了)
- 前半时钟周期写, 后半时钟周期读, 若同⼀个时钟内前⾯指令写⼊的数据正好是后⾯指令所读数据, 则不会发⽣数据冒险
-
⽅法2: 硬件阻塞(stall)
-
⽅法3: 软件插⼊“NOP”指令
-
⽅法4: 转发(Forwarding或Bypassing 旁路) 技术
- 若相关数据是ALU结果, 则可通过转发解决
- 若相关数据是上条指令DM读出内容(lw)则不能通过转发解决,随后指令需被阻塞⼀个时钟或加NOP指令
-
⽅法5: 编译优化: 调整指令顺序–可用于调整装入使用冒险
实现“转发”和“阻塞” 要修改数据通路: (1) 检测何时需要“转发” , 并控制实现“转发” (2) 检测何时需要“阻塞”, 并控制实现“阻塞”
==即数据冒险中,RAW写后读的数据冒险可以完全由转发处理,不需要阻塞, 但是Load-Use装入使用冒险必须要一个周期的阻塞(lw指令后是sw的话不需要阻塞,可转发处理)==
控制竞争
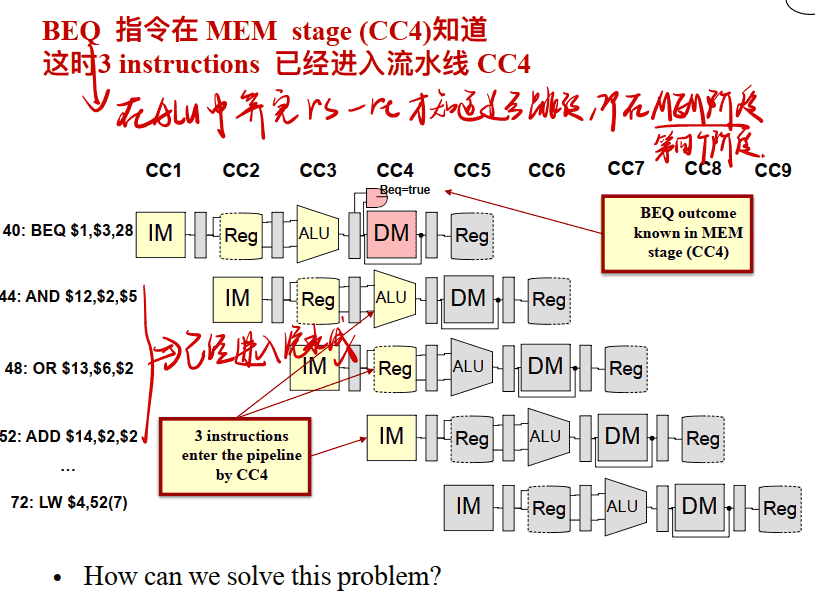
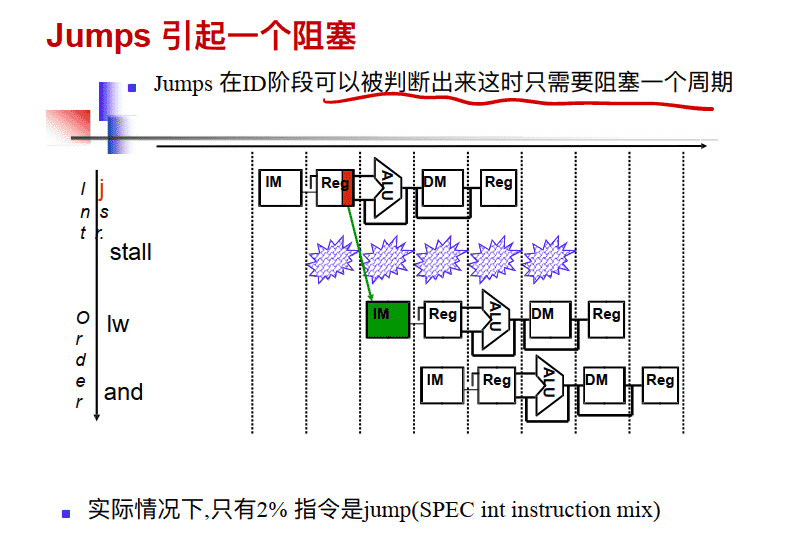
- 当指令流向不是预期的⽅式 有条件的分⽀ (beq, bne)需阻塞3个周期 ⽆条件的跳转 (j)
- 可能的解决⽅案 Stall 将判断提前是否跳转 预测 延迟决定(即延迟分⽀)(requires compiler support)
- 控制竞争不像数据竞争那样频繁的发⽣, 但是也没有像forwarding这样解决它的那么有效的⽅式
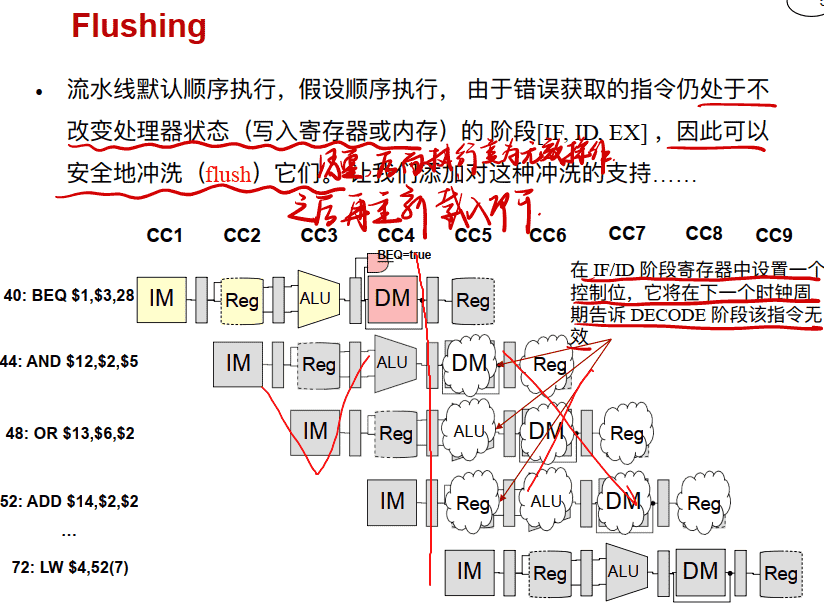
Flushing
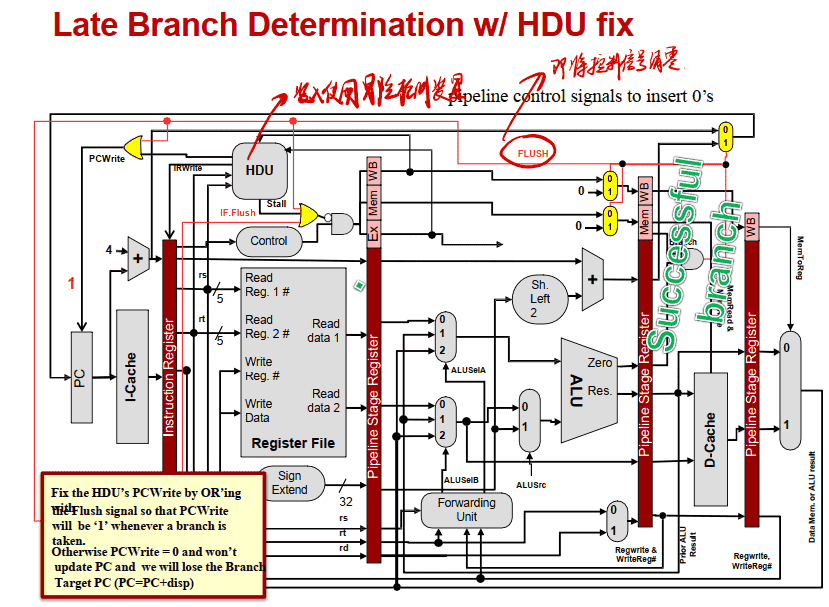
提前进⾏分⽀决定
- 将分⽀判断放在EX阶段中(原本在EX阶段计算是否相等,在MEM阶段判断是否跳转) 可以将STALL减少为2个 Adds an and gate and a 2x1 mux to the EX timing path
- 增加硬件以在ID阶段就进⾏⽐较运算和有效地址的运算, 这样可以使STALL减少为1 与RF的读操作同时 需要⼀个⽐较器, 多路选择器等电路 需要在ID阶段引⼊forwarding hardware 电路
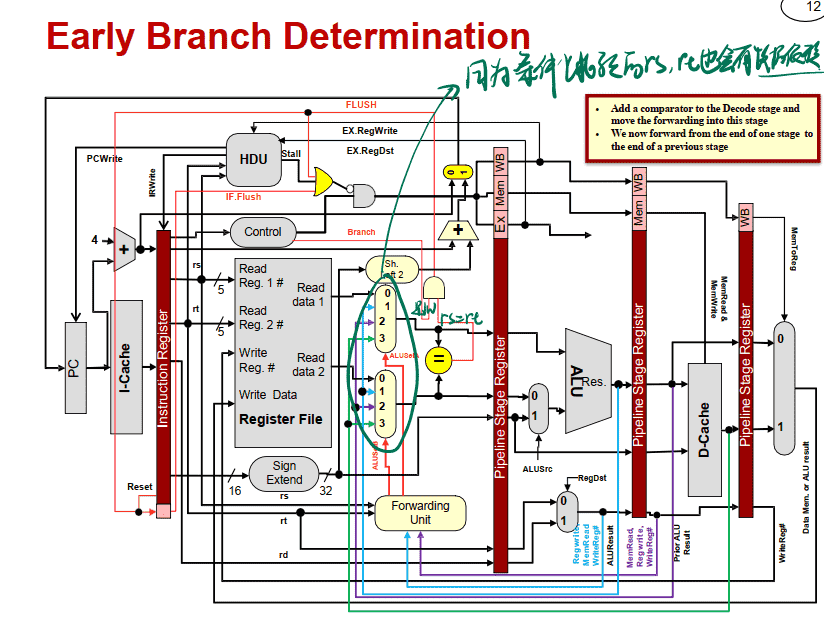
将分⽀判断放在ID阶段中
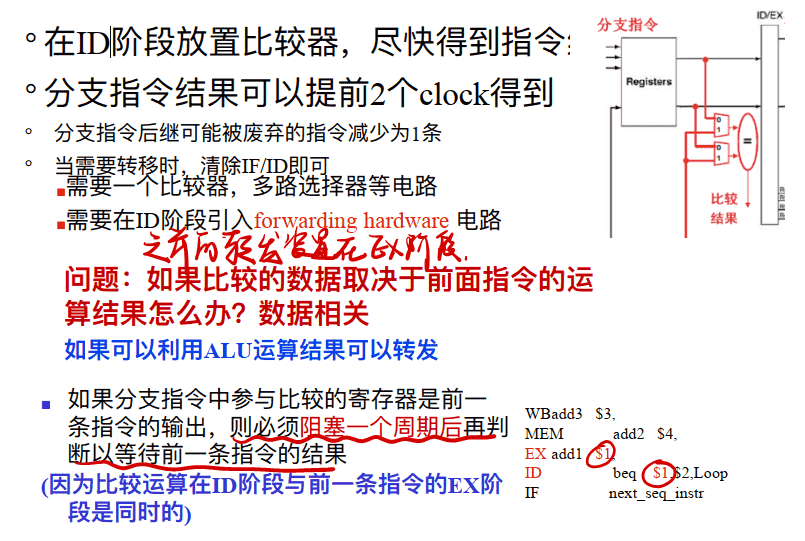
==如果分⽀指令中参与⽐较的寄存器是前⼀条指令的输出, 则必须阻塞⼀个周期后再判断以等待前⼀条指令的结果(因为⽐较运算在ID阶段与前⼀条指令的EX阶段是同时的)==
分支判断提前到ID阶段的数据通路图
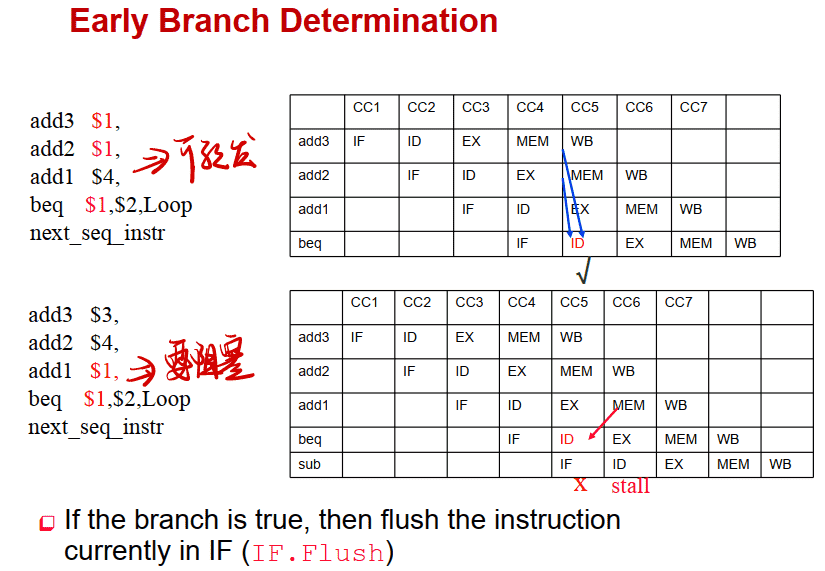
分支判断中的数据冒险


==即Branch指令要看前三条指令(假设与上三条指令都有数据冒险)==
- 若有前写后读,那么相隔两条指令的指令可以正常读取,不用转发
- 若可以转发,那么相隔一条指令的指令需要用到转发
- 上一条指令一定要阻塞一个周期
分支预测
通过静态的假定⼀个分⽀判断结果的输出解决分⽀竞争,一般都是假设不发生

分⽀预测——假设总不发⽣
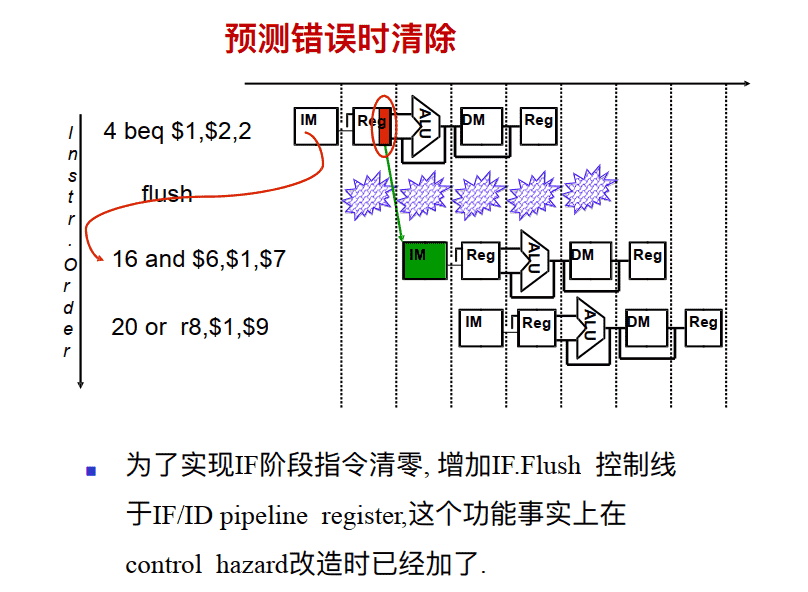
总假设分⽀不发⽣ – 遇到分⽀指令仍然按照正常的流程取指令,如果在流⽔线后期确实分⽀发⽣,则阻塞并清洗(取消已进⼊流⽔线指令)
- 如果分⽀发⽣, 清除分⽀指令后的流⽔线内指令 若在MEM判断跳转则阻塞3个周期 IF, ID, and EX if branch logic in MEM – three stalls 若在ID判断跳转则阻塞1个周期 IF if branch logic in ID – one stall
- 确保这些被清除的指令未改变机器状态– 由于机器状态是被(MemWrite or RegWrite) 控制信号在MEM和 WB阶段改写的, 因此这点可以保证
- 分⽀后继续流⽔线执⾏
分⽀预测——假设总发⽣
通过静态的假定⼀个分⽀判断结果的输出解决分⽀竞争 Predict taken – 总假定分⽀会发⽣和不会发生 发⽣分⽀引起⼀个周期的阻塞 (假定ID阶段的分⽀判断电路已经加上了) 这种策略损失效率 另外的解决⽅案就是再增加硬件进⾏动态预测 Dynamic branch prediction – 利⽤运⾏时的信息进⾏动态预测
分⽀预测——动态预测
再增加硬件进⾏动态预测Dynamic branch prediction – 利⽤运⾏时的信息进⾏动态预测
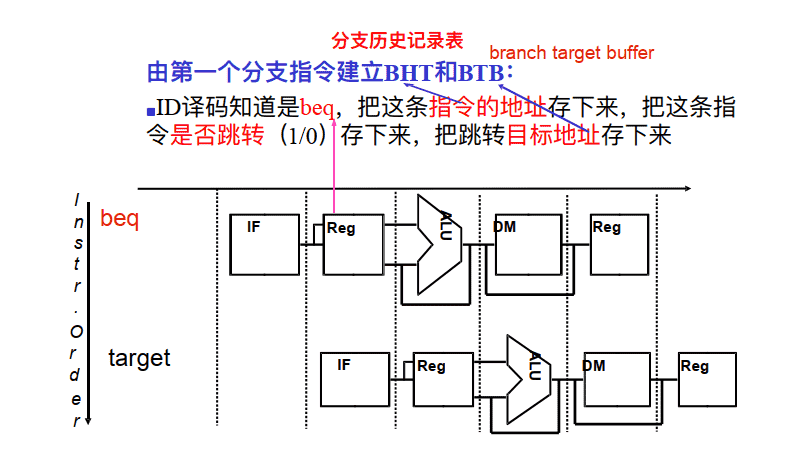
- 需要实现⼀个IF阶段分⽀预测缓存(即 branch historytable (BHT)), 可以以PC的低位地址为索引,以1bit记录 上次是否发⽣了 (因为在ID节点判断是否跳转,所以在ID节点就可以知道是否预测正确,只要是之前分支指令的地址,就先预测为要跳转,)
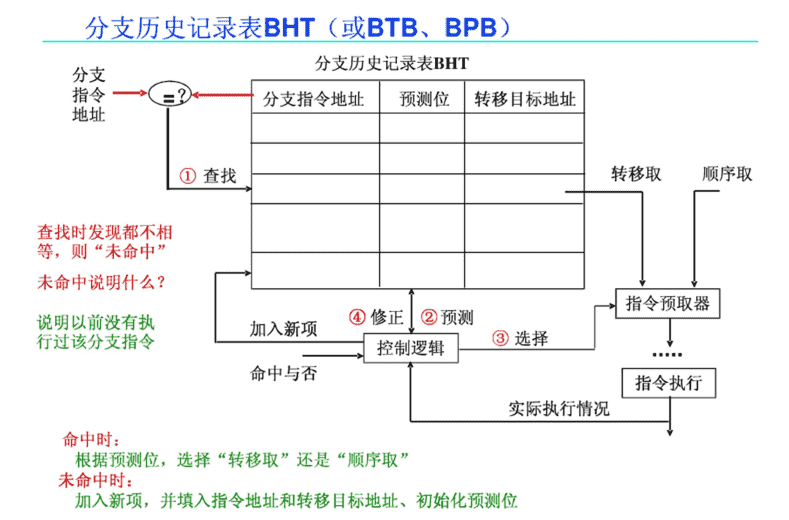
分⽀历史记录表BHT(Branch History Table)
- 每个表项有分⽀地址的地位索引, 故在IF段可以取到预测位:
- 低位地址相同的分⽀指令共享⼀个表项
- 可能取得时其它指令的预测位, 会不会有问题?
- 仅⽤于预测, 不影响执⾏结果
- 低位地址相同的分⽀指令共享⼀个表项
现在⼏乎所有的处理器都采⽤动态预测

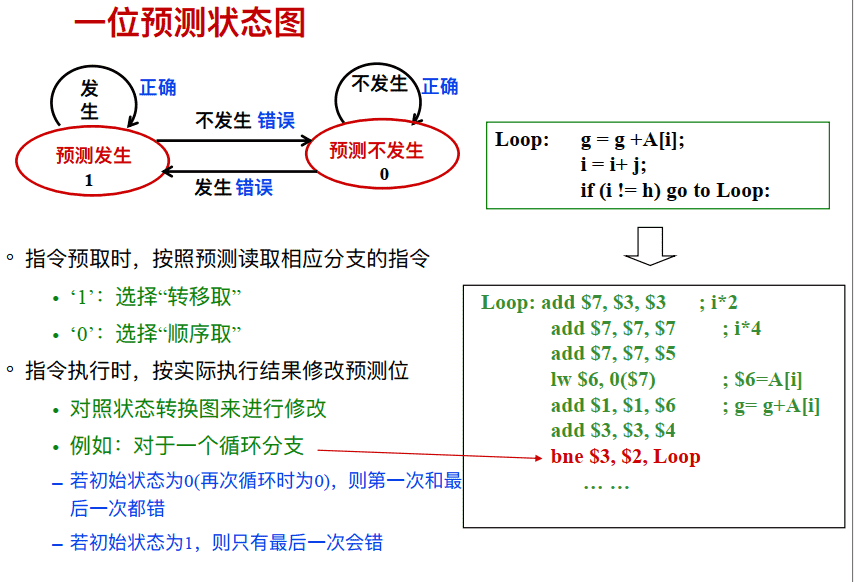
⼀位预测状态图

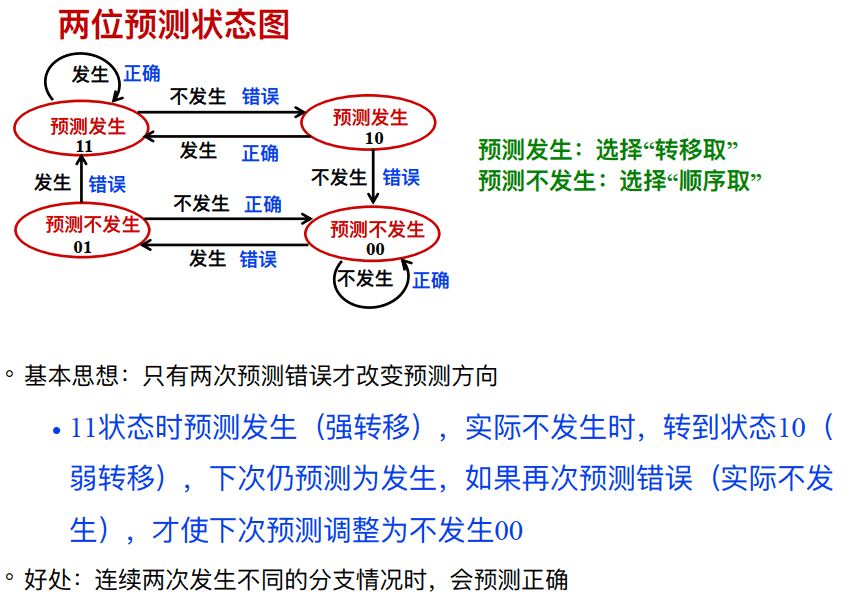
两位预测状态图
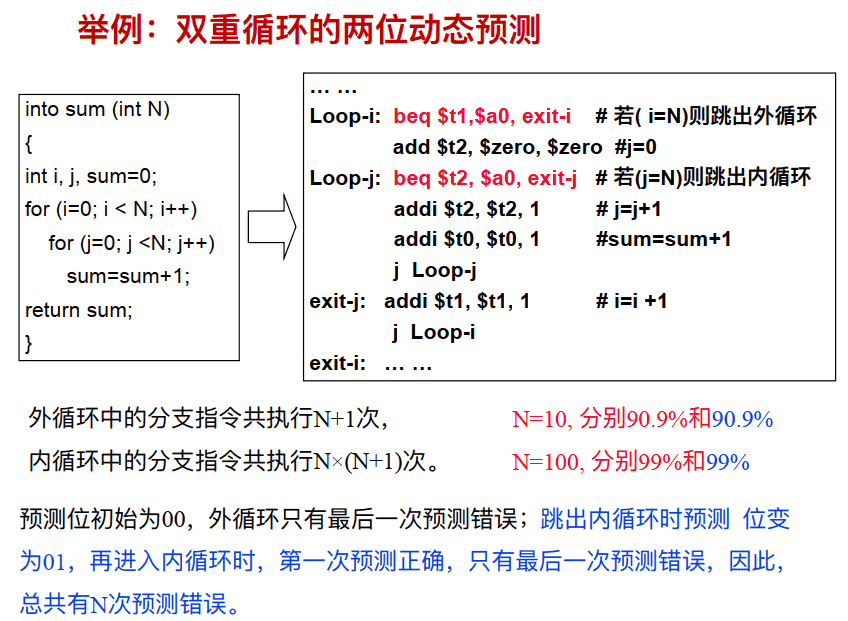
动态分⽀预测过程
-
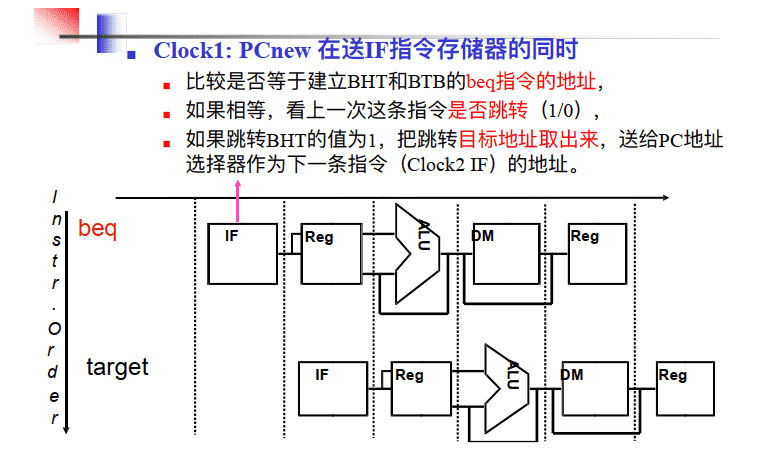
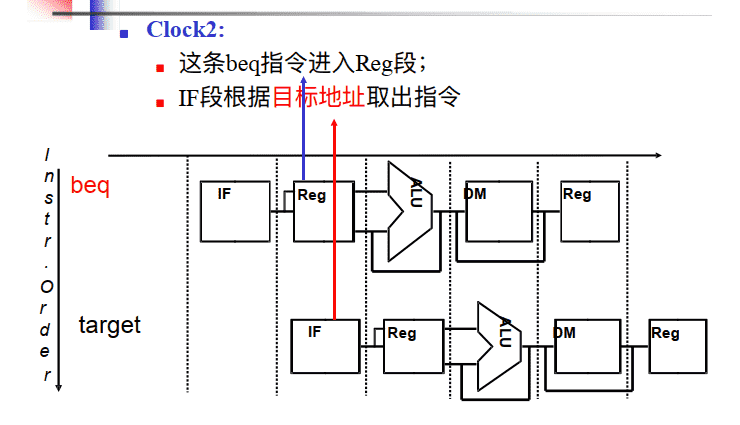
当分支指令到达译码段(ID)时,根据从BHT读出的信息进行分支预测 。若预测正确,就继续处理后续的指令,流水线没有断流。否则,就要作废已经预取和分析的指令,恢复现场,并从另一条分支路径重新取指令。
-
根据运行状况,修改BHT的状态。

Clock 1
Clock 2
延迟分支
- ⾸先还是要将分⽀的判断电路放在ID阶段
- 延迟分⽀技术使得分⽀指令的含义与原来不同,该机制规定分⽀指令后⾯紧跟的指令必须被执行, 无论条件判断结果如何
- MIPS⽀持该机制, 于是MIPS 编译器将⼀条不受分⽀条件影响的指令放在分⽀指令之后, 这样可以隐藏该指令的执⾏时间
- 处理器流⽔线级数增加以后需要更多的延迟分⽀槽数⽬ .
- 延迟分⽀毕竟不如动态分⽀灵活目前已经不那么⼴泛使⽤,但是这是个简单的解决⽅案
- 基本思想:把分⽀指令前⾯的与分⽀指令⽆关的指令调到分⽀指令后⾯执⾏, 以填充延迟时间⽚(也称分⽀延迟槽Branch Delay slot) , 不够时⽤nop操作填充
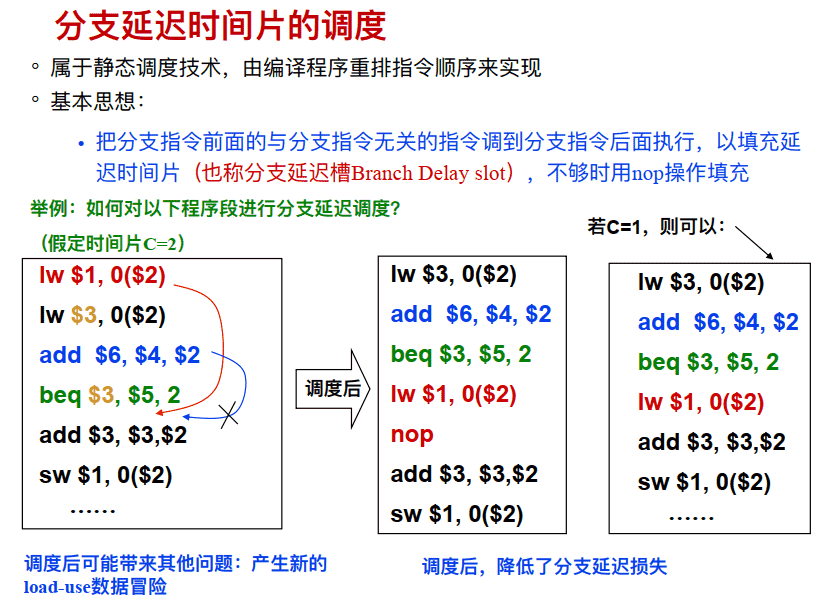
时间片=2即branch指令后两条都一定执行 时间片=1即branch指令后一条一定执行
==要与解决数据冒险中的方案4:通过改变指令顺序解决装入使用冒险区别开==
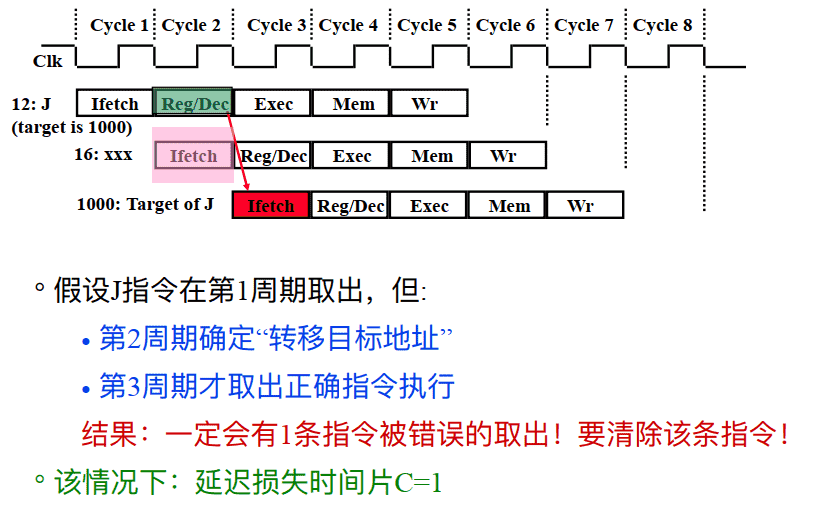
J指令的分⽀延迟(如果在ID段进⾏转移地址计算和回送)
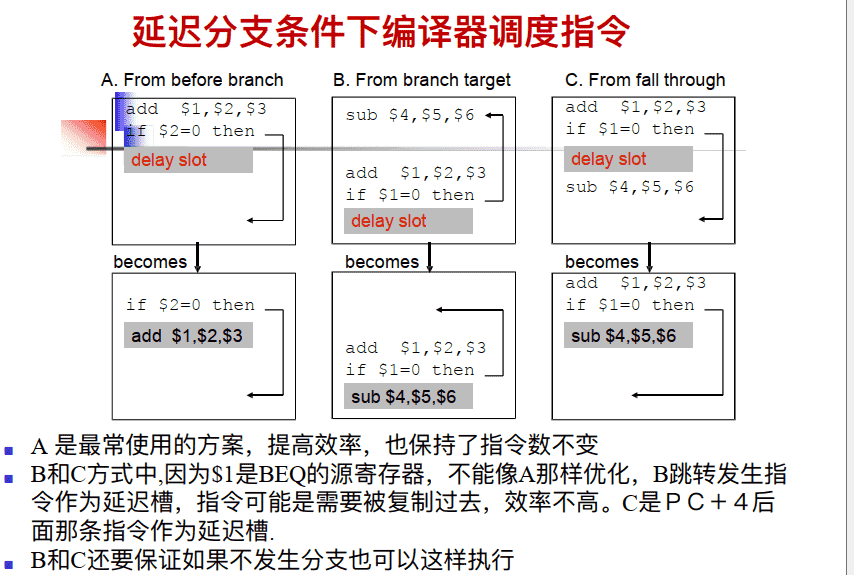
总结:Control Hazard的解决⽅法
- ⽅法1: 硬件上阻塞(stall) 分⽀指令后三条指令的执⾏(阻塞3周期) • 使后⾯三条指令清0或 其操作信号清0, 以插⼊三条NOP指令
- ⽅法2: 软件上插⼊三条“NOP”指令 (以上两种⽅法的效率太低, 需结合分⽀预测进⾏)
- ⽅法3: 分⽀预测(Predict)
- 简单(静态) 预测(预测总是不满足or满足): - 总是预测条件不满⾜(not taken)或满⾜,即: 继续执⾏分⽀指令的后续指令
- 动态预测: - 根据程序执⾏的历史情况, 进⾏动态预测调整, 能达90%的预测准确率 注: 采⽤分⽀预测⽅式时, 流⽔线控制必须确保错误预测指令的执⾏结果不能⽣效, ⽽且要能从正确的分⽀地址处重新启动流⽔线⼯作
- ⽅法4: 延迟分⽀(Delayed branch) (通过编译程序优化指令顺序! ) • 把分⽀指令前⾯与分⽀指令⽆关的指令调到分⽀指令后⾯执⾏, 也称延迟转移另⼀种控制冒险: 异常或中断控制冒险的处理
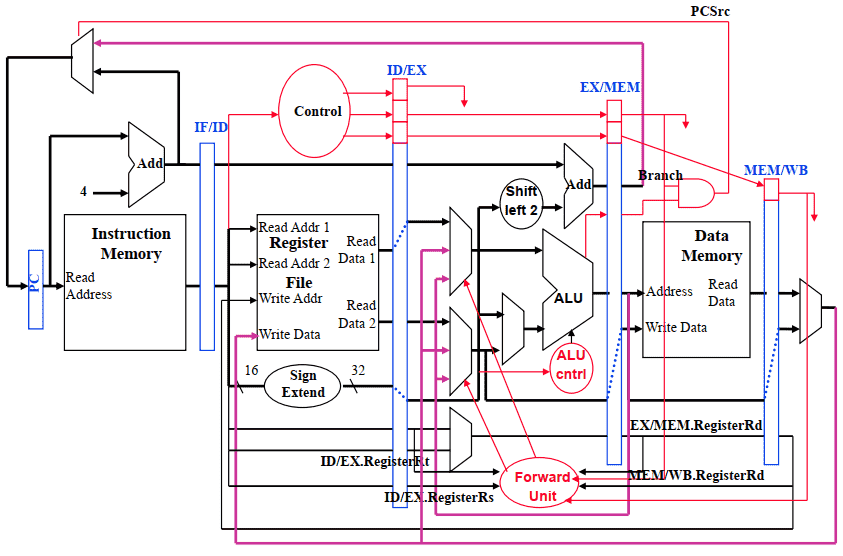
最终的数据通路图
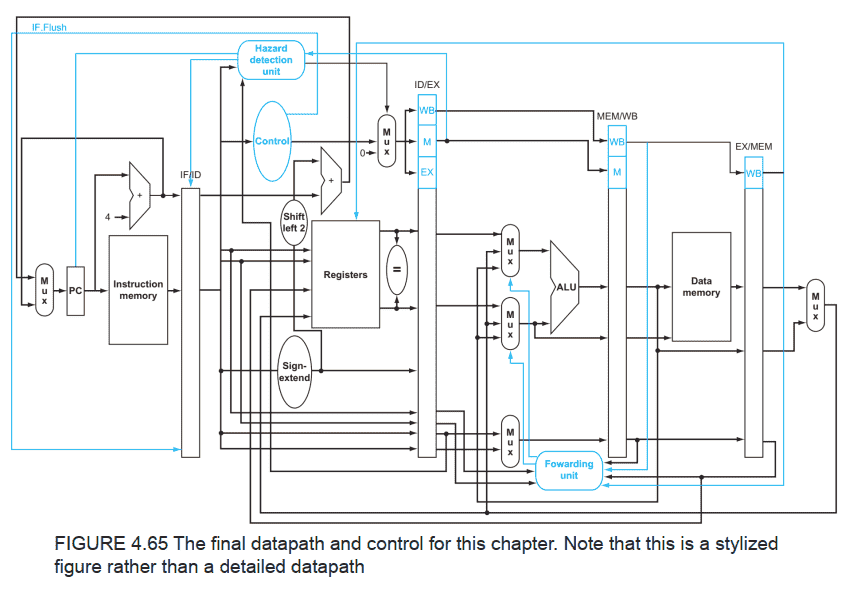
ppt中还有异常处理和高级流水线技术
小结
- Forwarding是解决由于数据关联引起的竞争的有效⽅式
- 保证前⾯的指令是有写⼊操作的, destination 与后⾯指令source⼀样, ⽽且没有更新的数据可以⽤
- 所有可以forward的地⽅需要增加新的硬件, 如果不能forward则等待 EX stage, MEM stage for store, ID stage for early branch
- Load指令需要阻塞 分⽀也可能需要阻塞
- 控制竞争可以通过静态分⽀\动态分⽀\预测等⽅式处理 预测⽅式下, 要解决预测错误时的处理
==需要阻塞的情况:==
- ==数据冒险中装入使用冒险lw后需要一个周期阻塞(如果lw后是sw则不用)==
- ==如果分⽀指令中参与⽐较的寄存器是前⼀条指令的输出, 则必须阻塞⼀个周期后再判断以等待前⼀条指令的结果(因为⽐较运算在ID阶段与前⼀条指令的EX阶段是同时的)即branch前加一个阻塞==
- ==j型指令后一定会有一个周期的阻塞==
易错点:
1
2
3
读写分开,分支指令的比较在ID阶段,有分支延迟槽,实现了转发
lw $t0,0($a0)
beq $t0,0,end
上述应该要2个周期的stall,而不是1个,因为beq是在ID阶段就需要数据,只有EX阶段需要数据的才是只需要stall一个周期。
1
2
lw :IF ID EX MEM WB
beq: 1 2 IF ID EX MEM WB
- 结构冒险(资源冲突) : 多条指令同时使⽤同⼀个功能部件
- 规定每个功能部件在⼀条指令中只能被⽤⼀次
- 规定每个功能部件只能在某个特定的阶段被⽤
- 指令存储器(Code Cache)和数据存储器(Data Cache)分开
- 数据冒险(数据相关) : 前⾯指令的结果是后⾯指令的操作数
- 软件阻塞: (如: 编译器) 在后⾯的数据相关指令前插⼊nop指令
- 硬件阻塞: 在后⾯数据相关指令的特定流⽔段插⼊“⽓泡”以“阻塞”指令继续执⾏, 直到取得所需数据为⽌
- “转发”(旁路) : 把前⾯指令执⾏过程中得到的数据直接传送到后⾯指令。
- 对于取数后直接使⽤的情况(如: Load指令取出的数据是随后的运算指令的操作数) , 则采⽤“阻塞加转发”的⽅式解决数据冒险
- 控制冒险(控制相关) : 返回指令、 分⽀指令等可能改变顺序增量的PC值,由于获取转移⽬标地址的时间较⻓, 使得在⽬标地址产⽣前已经有指令被取到流⽔线中, 如果已经取出执⾏的指令不是正确的指令, 则发⽣控制冒险。
- 软件阻塞: (如: 编译器) 在控制相关指令后⾯插⼊nop指令
- 硬件阻塞: 在控制相关指令后⾯的指令被取出前插⼊“⽓泡”, 使流⽔线停顿若⼲时钟, 直到控制相关指令得到正确的PC值为⽌
- 采⽤“分⽀预测”技术。 简单(静态) 地预测每次分⽀结果都⼀样, 或根据分⽀指令执⾏历史进⾏动态预测, 动态预测能达到90%以上的成功率
- 采⽤延迟分⽀技术。 将前⾯⼀条与分⽀指令⽆关的指令放到分⽀指令后⾯执⾏, 这样, 流⽔线不会发⽣阻塞现象。 这种对指令顺序进⾏调整的⼯作在程序编译阶段完成
三种处理器实现⽅式的⽐较