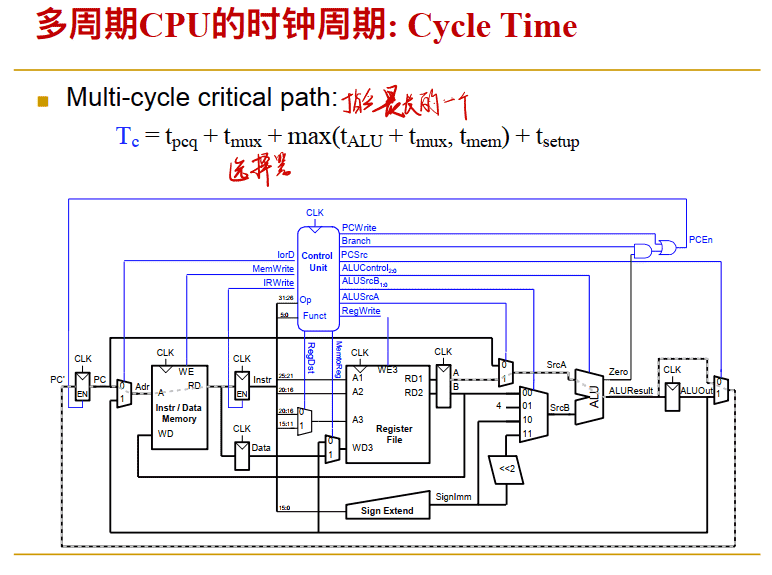
4-2 多周期数据通路
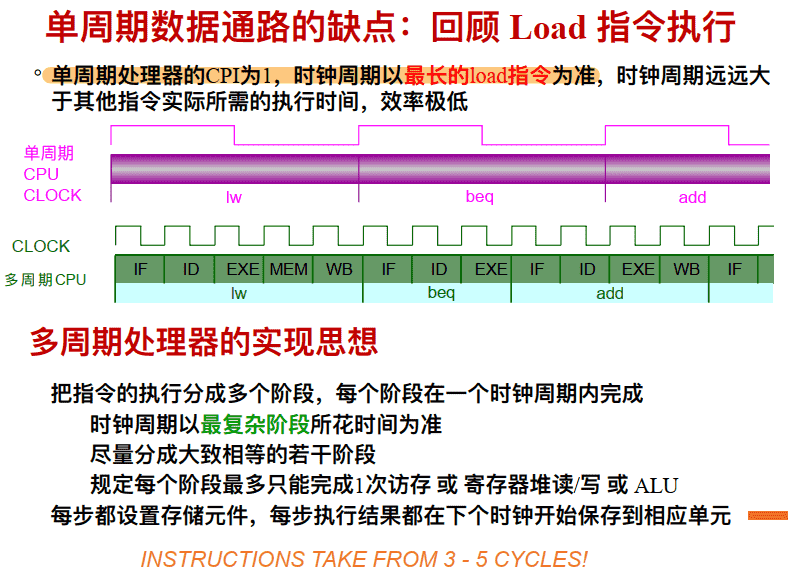
单周期数据通路的时钟周期取决于最长的一条指令(lw)
多周期处理器的实现思想
==多周期数据通路只有一个ALU==
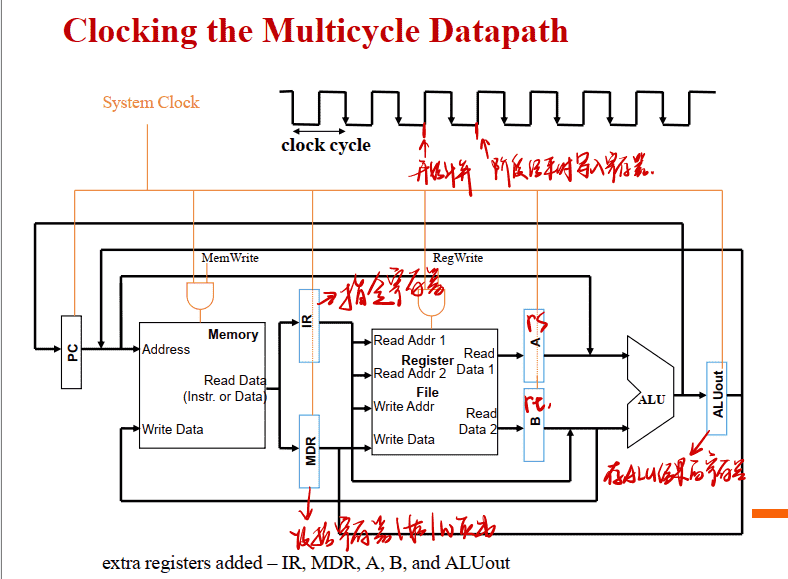
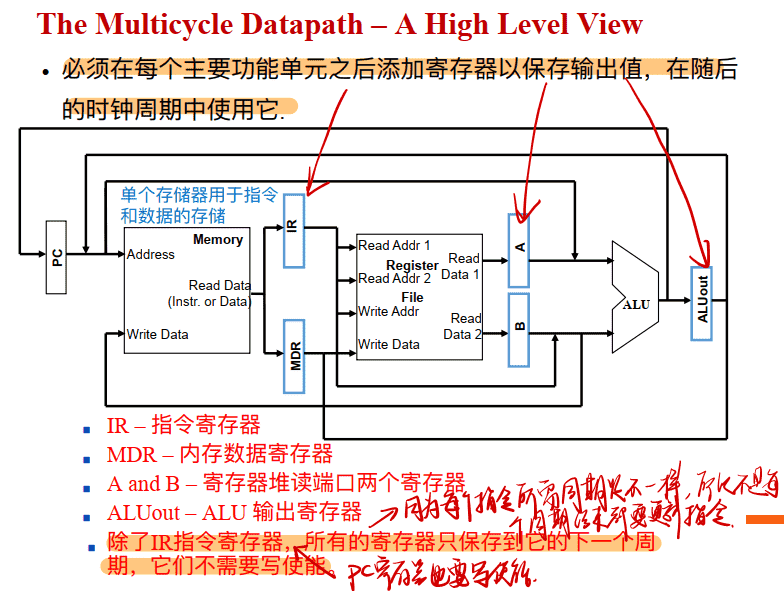
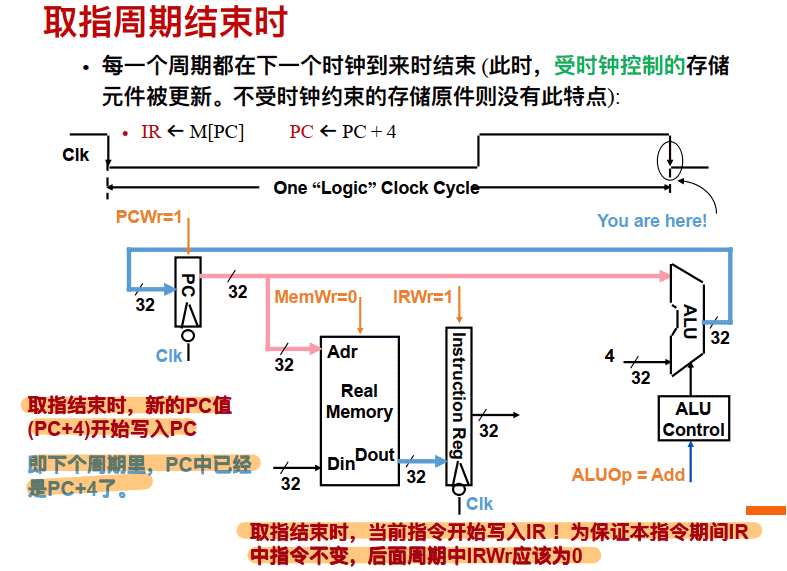
必须在每个主要功能单元之后添加寄存器以保存输出值, 在随后的时钟周期中使⽤它 IR指令寄存器和PC寄存器都要写使能,其他的不用
指令各阶段分析
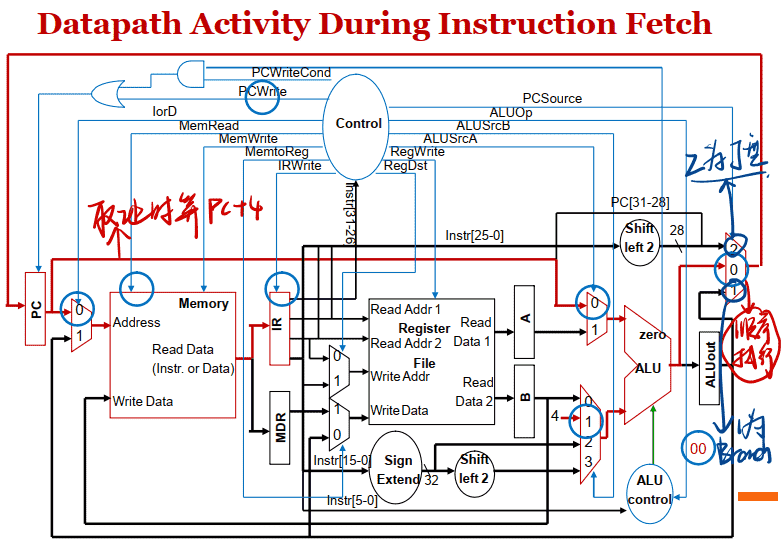
- Instruction Fetch
- Instruction Decode and Register Fetch
- Execution, Memory Address Computation, or Branch Completion
- Memory Access or R-type instruction completion
- Write-Back Step
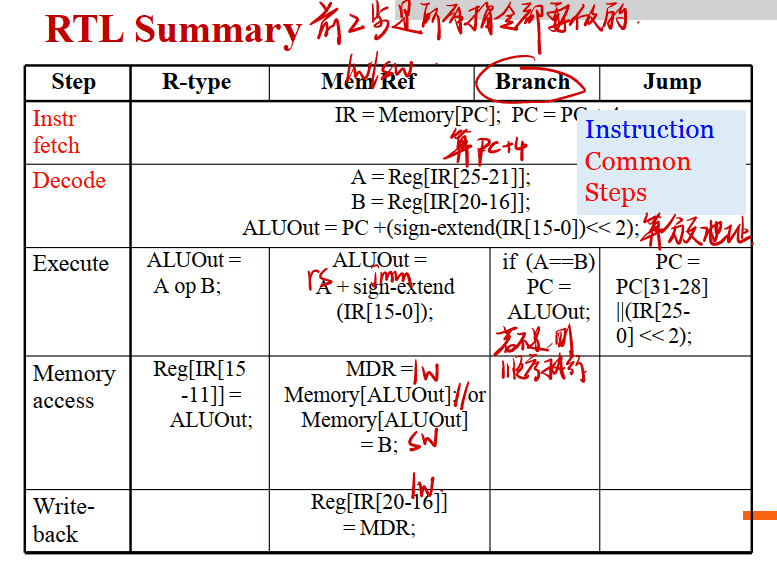
第一个周期(取值周期)(算PC+4)
1.取指令阶段 • 执⾏⼀次存储器读操作 • 读出的内容(指令) 保存到寄存器IR(指令寄存器) 中 • IR的内容不是每个时钟都更新, 所以IR必须加⼀个“写使能”控制 • 在取指令阶段结束时, ALU的输出为PC+4, 并送到PC的输⼊端, 但不能在每个时钟到来时就更新PC, 所以PC也要有“写使能”控制
第二个周期(译码取数周期)(算分支地址,PC=PC+4+4*offset,offset是相对于PC+4而言的)
2.译码/读寄存器堆阶段 • 经过控制逻辑延迟后, 控制信号更新为新值 • 执⾏⼀次寄存器读操作, 并同时进⾏译码 • 期间ALU空闲, 可以考虑“投机计算”分支地址
第三、 四、 五个周期(各指令不同)
3.ALU运算阶段 • ALU运算, 输出结果⼀定要在下个时钟到达之前稳定(如lw指令,则要算imm(rs)的imm+rs) • 如果是分⽀branch指令, 该阶段需决定是否将分⽀地址写⼊PC 4.读存储器阶段 • 由ALU运算结果作为地址访问存储器, 读出数据 5.写结果到寄存器 • 把之前的运算结果或读存储器结果写到寄存器堆中
Multicycle Implementation Overview
-
每条指令每⼀步⽤⼀个时钟周期,因此每条指令花费多个时钟周期
-
不是每条指令都花费同样的时钟周期数
-
多周期CPU
- 更快的时钟频率
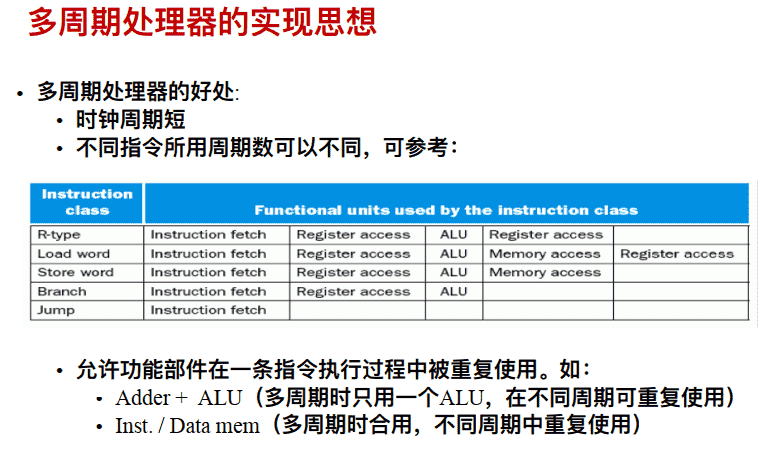
- 不同的指令⽤不同的周期数
- 单个ALU⽤于所有计算
- 单个存储器⽤于指令和数据的存储(冯诺依曼结构,指令和数据在同一内存中)
- 需要增加寄存器暂存数据⽤于跨时钟周期
Our Multicycle Approach
- 状态器件的读写: 寄存器堆或PC每个时钟开始后进⾏读操作, 时钟结束进行写操作。
- 寄存器堆读花差不多~50% 的时钟周期时间, 控制器与其并⾏进⾏。
- 在功能部件前⾯增加选择器, 因为不同的时钟周期共享同⼀个ALU部件。
- 所有的操作在⼀个时钟周期内并⾏进⾏。(每个阶段要在同一周期内完成)
- 与单周期不同的是PC+4, 条件跳转地址计算都在一个ALU上进⾏,指令存储器和数据存储器使⽤同⼀个存储器, 每个时钟周期都进⾏寄存器堆的读操作。
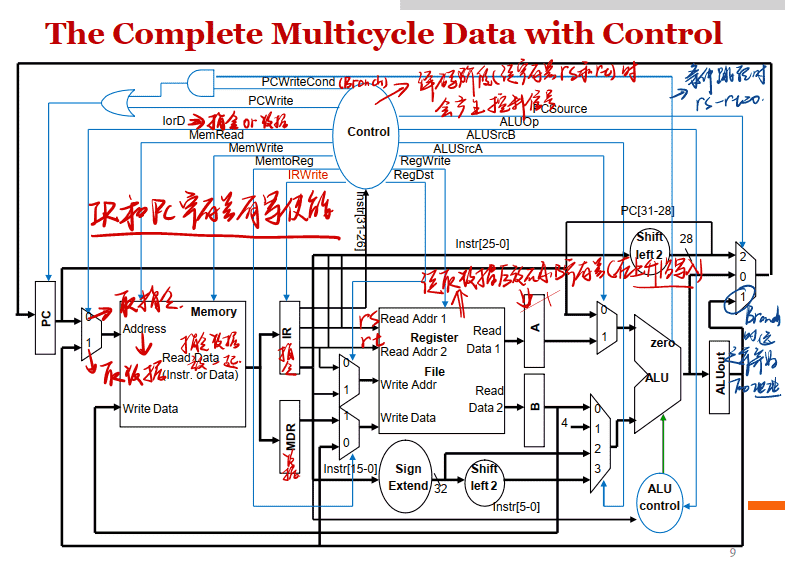
The Complete Multicycle Data with Control
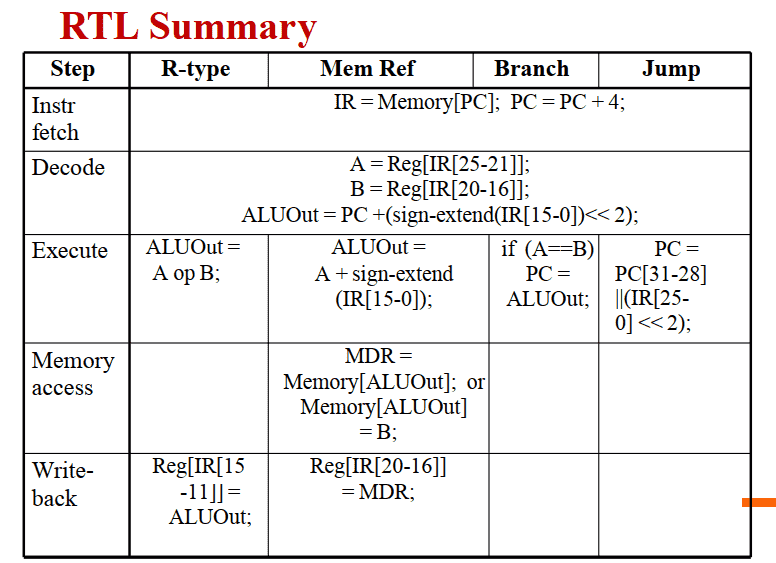
RTL Summary
前两阶段是所有指令都要做的
Step 1:Instruction Fetch (计算PC+4)
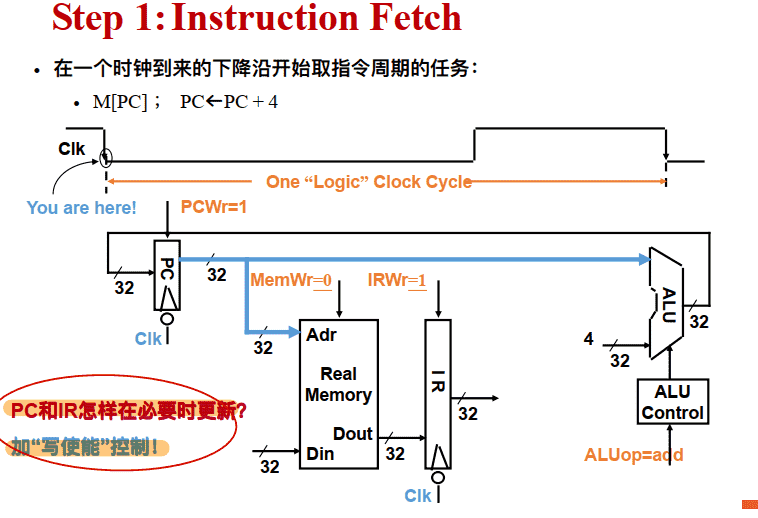
何时更新PC
Datapath Activity During Instruction Fetch
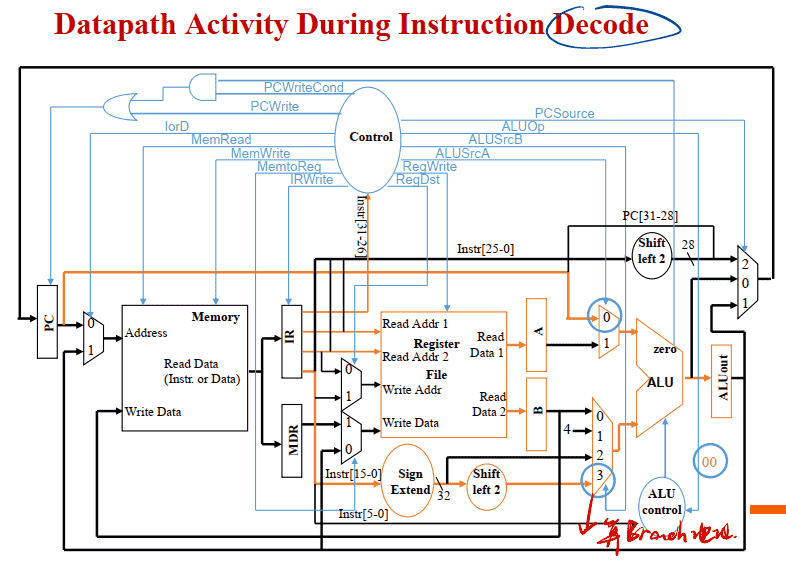
Step 2: Instruction Decode and Register Fetch (计算分支地址)
-
指令未译码, 故只执⾏公共操作, ALU空闲, 可⽤ALU“投机计算”转移地址
-
ALUOut = PC+(sign-extend(IR[15-0])« 2);
-
读出寄存器堆的两个寄存器内容 The RTL: •A = Reg[IR[25-21]]; •B = Reg[IR[20-16]];
请注意, 我们没有根据指令设置任何控制线(因为控制逻辑正忙于“译码”操作码位) , 还不知道它是什么)
Datapath Activity During Instruction Decode
注意这里有个易错点

Step 3 Instruction Dependent Operations
- ALU is performing one of four functions, based on instruction type
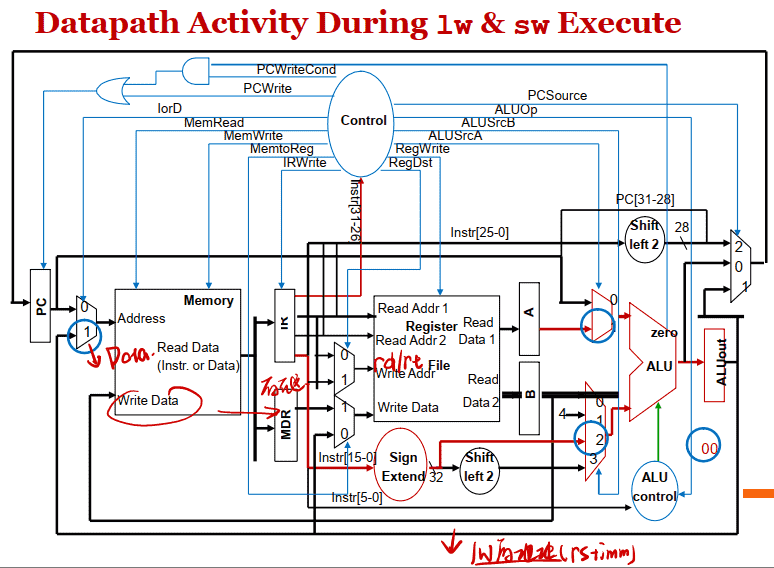
- Memory reference (lwand sw): ALUOut = A + sign-extend(IR[15-0]);
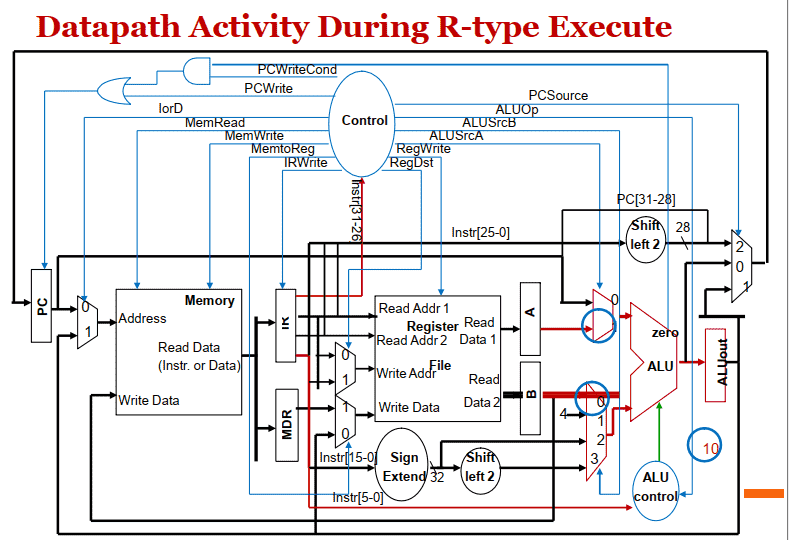
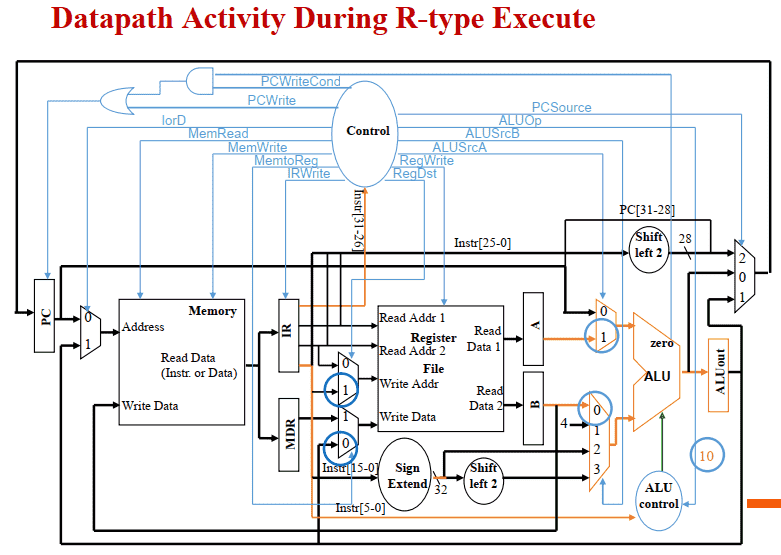
- R-type: ALUOut = A op B;
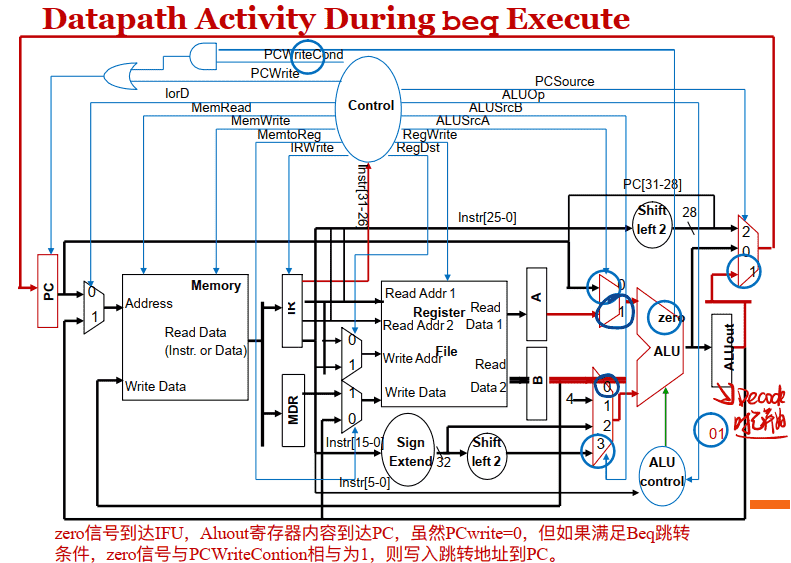
- Branch: if (A==B) PC = ALUOut;
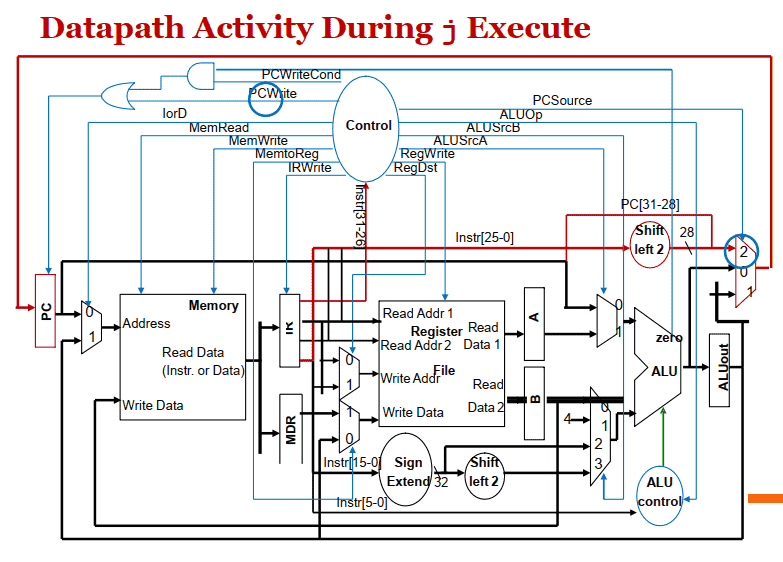
- Jump: PC = PC[31-28] || (IR[25-0] « 2);
- 如果指令译码输出为: Beq 下⾯第三个周期就是Beq指令 的第⼀个执⾏周期!
beq
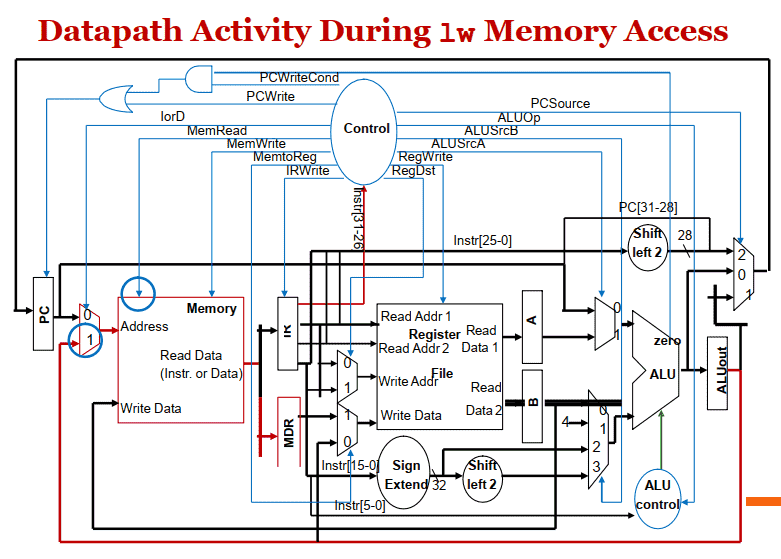
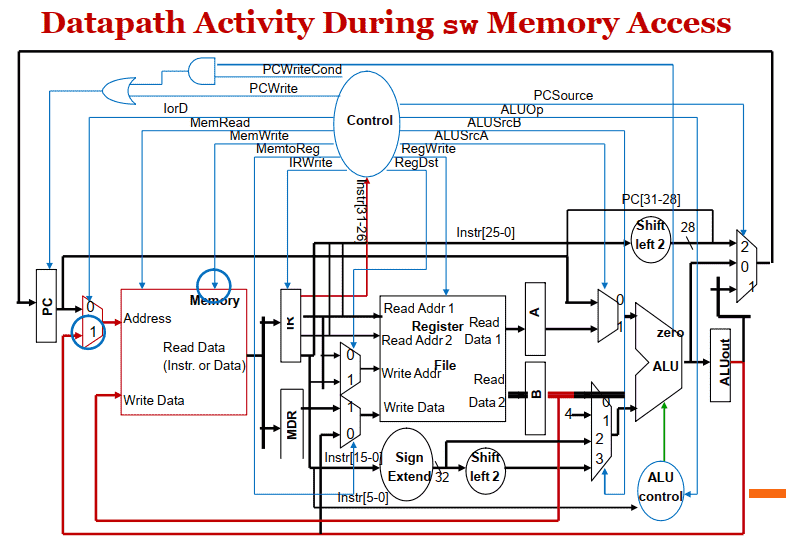
lw & sw
R-type
J型指令
Step 4 (also instruction dependent)
- LW指令, 从内存读出的数据存⼊内存数据寄存器MDR, sw指令把端⼝B读出的内容写⼊内存:
| MDR = Memory[ALUOut]; | – lw |
|---|---|
| Or | |
| Memory[ALUOut] = B; | – sw |
- R-type 计算结果写⼊⽬标寄存器 Reg[IR[15-11]] = ALUOut;
- 请记住, 寄存器写⼊实际上发⽣在时钟周期结束时的边沿
R-type
lw
sw
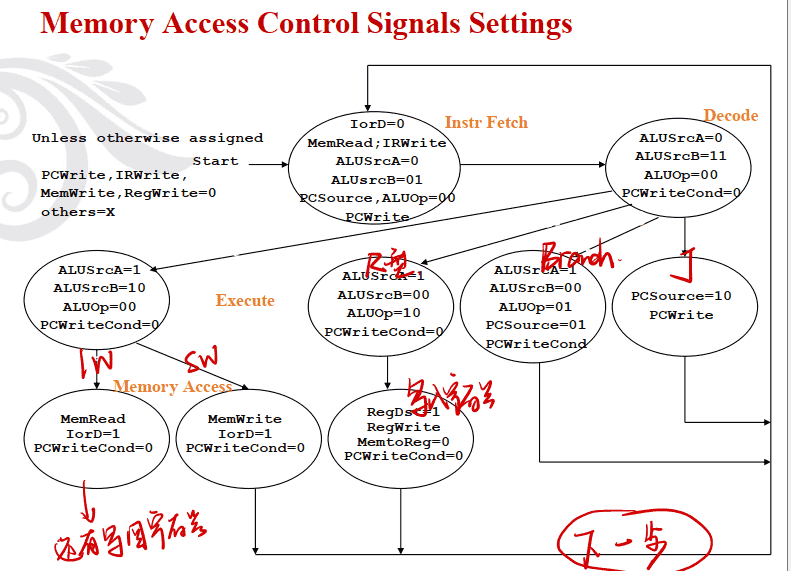
Memory Access Control Signals Settings
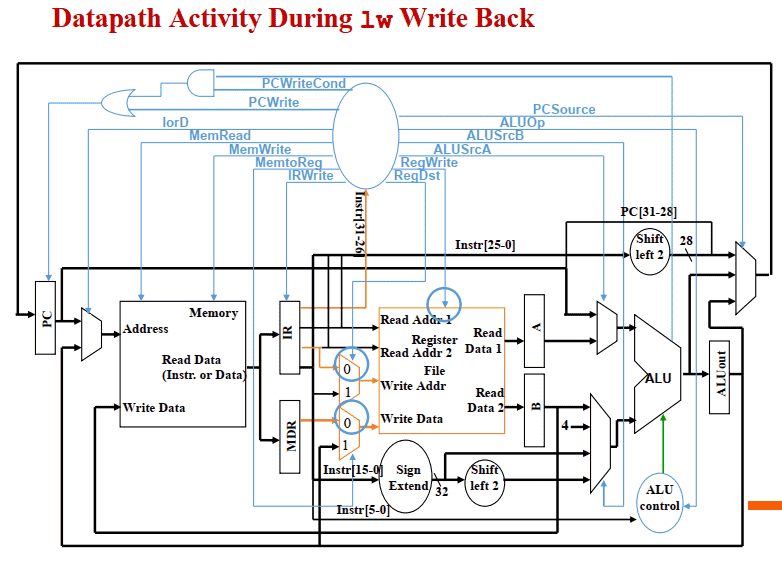
Step 5: Memory Read Completion (Write Back)
lw
控制信号
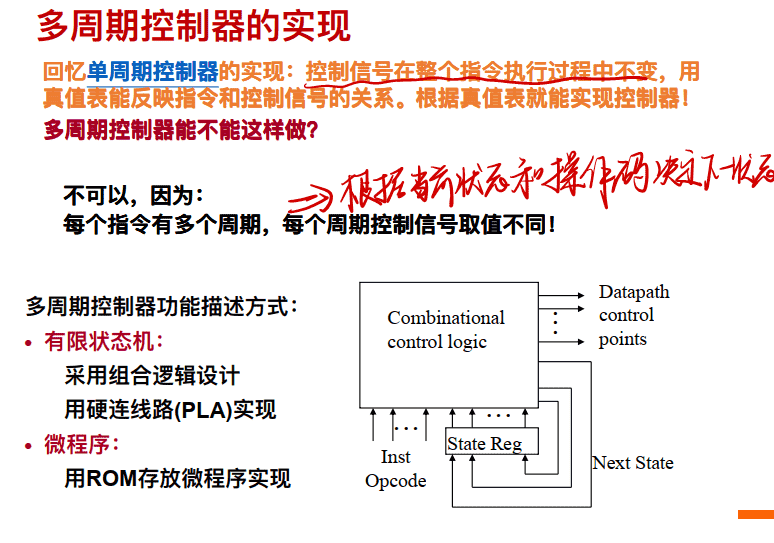
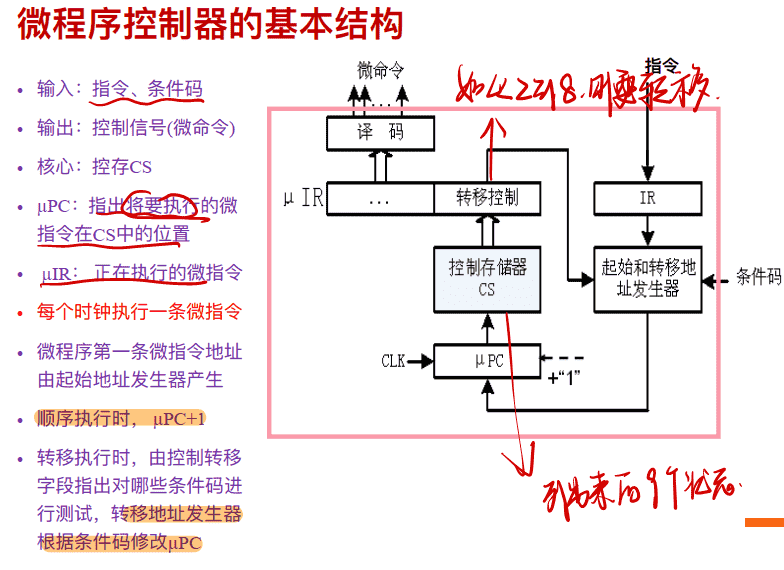
多周期控制器的实现
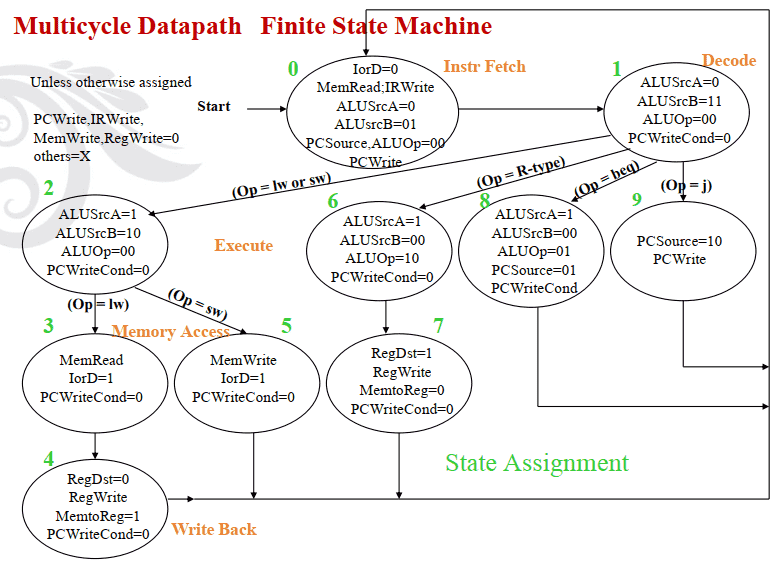
Multicycle Datapath Finite State Machine
Finite State Machine Implementation
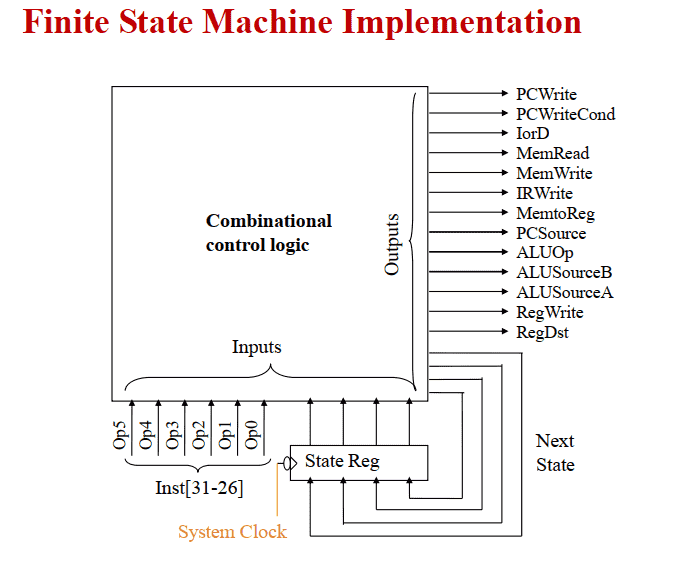
Datapath Control Outputs Truth Table
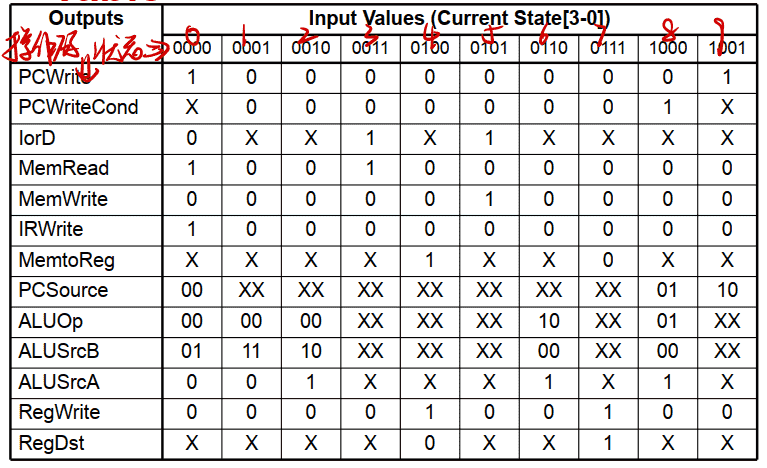
Next State Truth Table
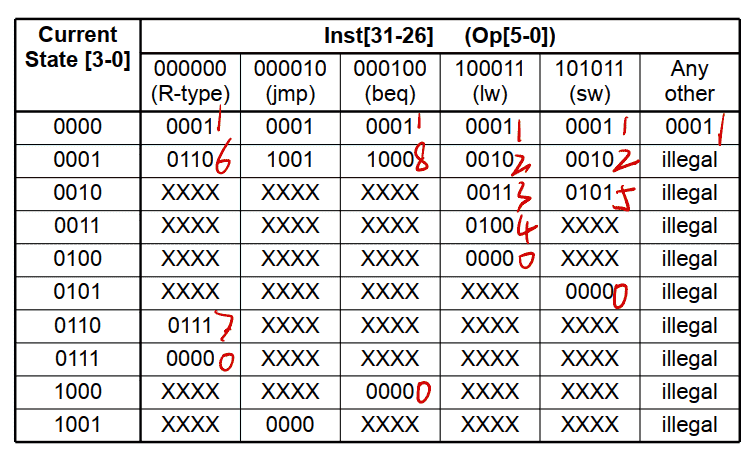
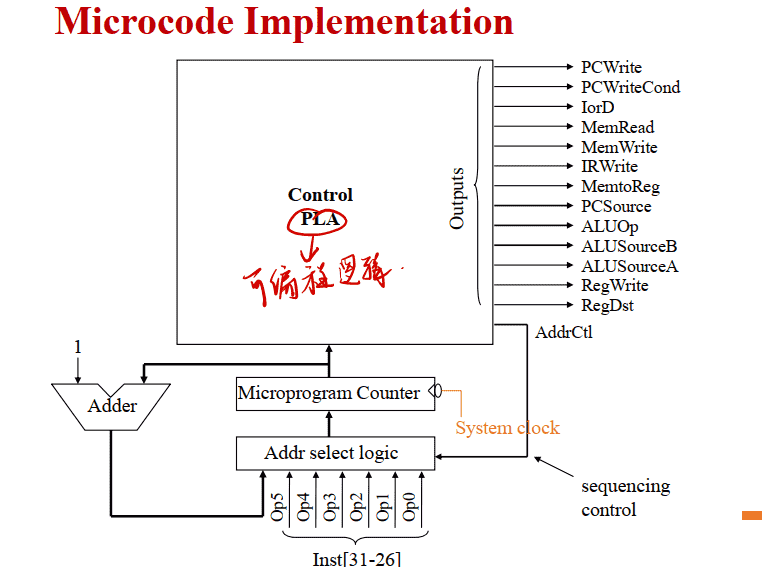
实现技术: PLA(Programmed Logic Arrays)
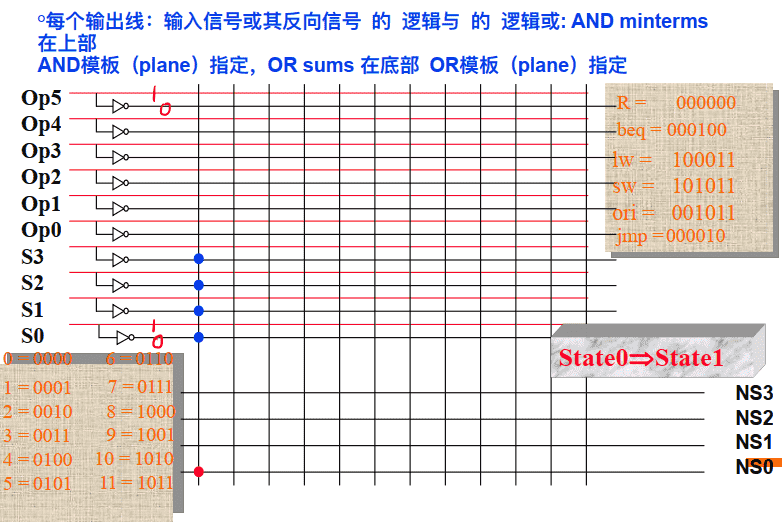
⽤PLA电路实现的组合逻辑控制单元(硬布线⽅式)
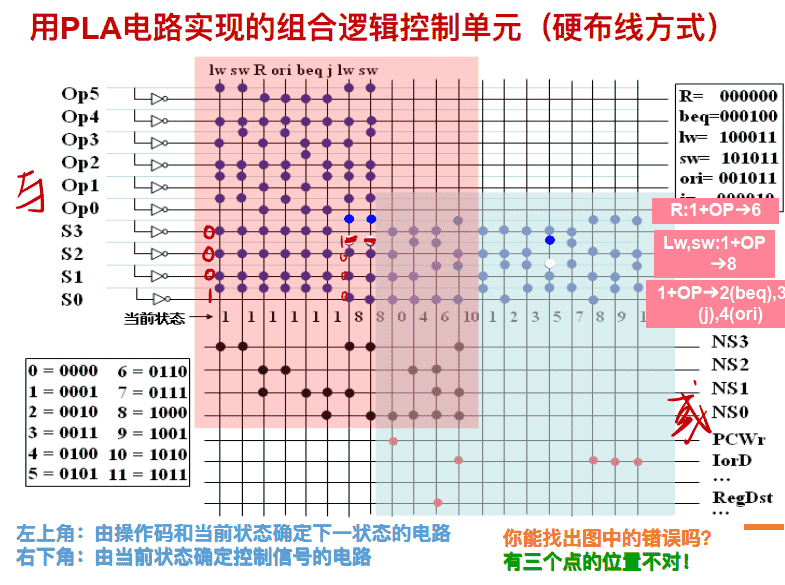
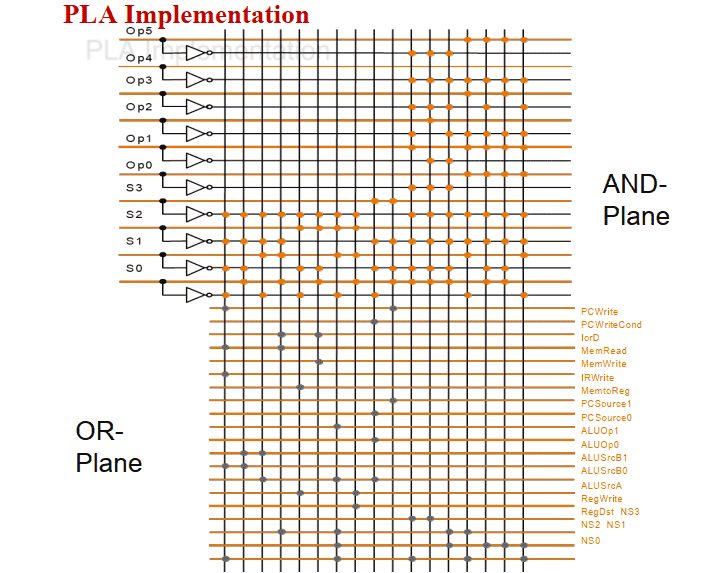
硬连线路设计和微程序设计
-
硬连线路设计的特点: 优点: 速度快, 适合于简单或规整的指令系统, 例如, MIPS指令集。 缺点: 它是⼀个多输⼊/多输出的巨⼤逻辑⽹络。 对于复杂指令系统来说, 结构庞杂, 实现困难; 修改、 维护不易; 灵活性差。 甚⾄⽆法⽤有限状态机描述!
-
简化控制器设计的⼀个⽅法: 微程序设计
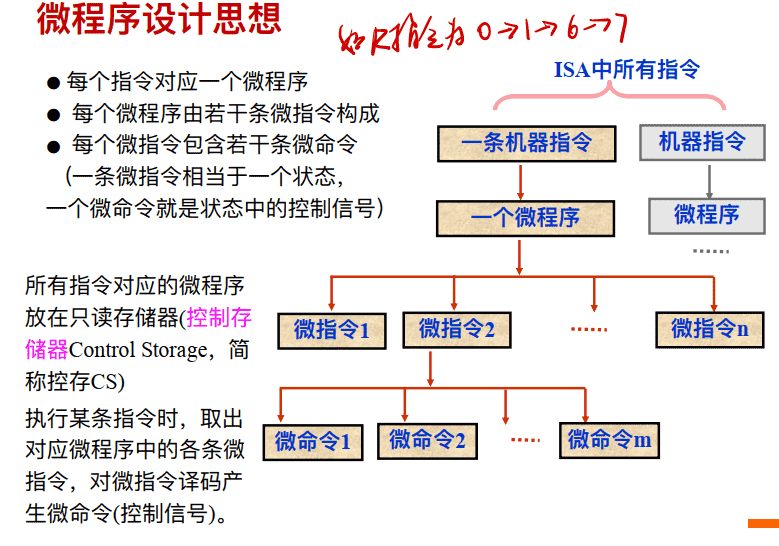
- 微程序控制器的基本思想: • 仿照程序设计的⽅法, 编制每个指令对应的微程序
- 微程序设计的特点: 具有规整性、 可维性和灵活性, 但速度慢
微程序设计
- 控制是处理器设计的⼀个难点, 早期计算机设计⼈员⾯临的最⼤挑战是正确地控制电路
- 数据通路具有较好的规整性和很好的组织
- 存储器具有很⾼的规整性
- 控制不规整, 并且涉及全局
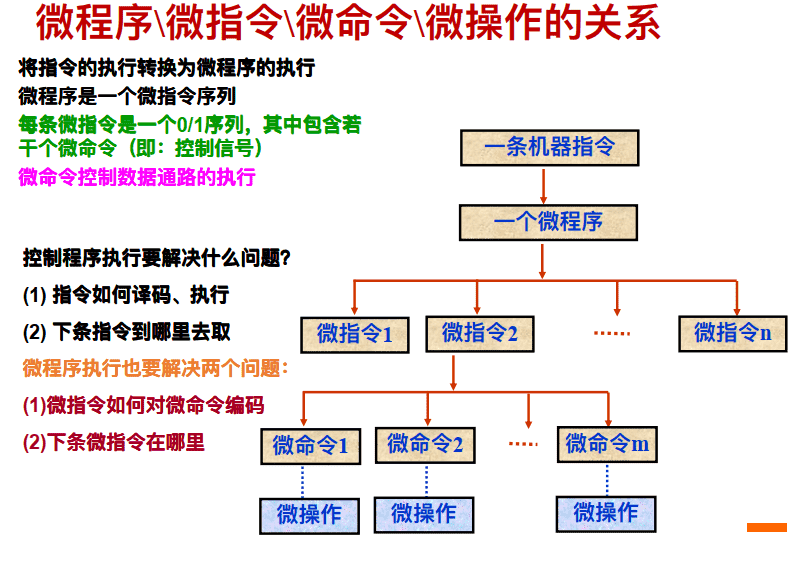
- 微程序设计:⼀种特殊的实现处理器控制部件的策略, 它在寄存器传输操作的级别进⾏“编程”
- 微体系结构(Microarchitecture) :微程序编程⼈员所看到的硬件的逻辑结构和功能特性
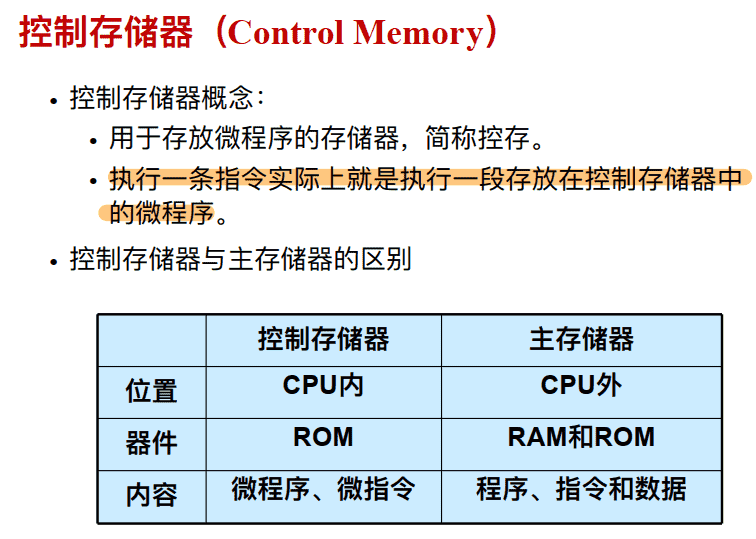
控制存储器(Control Memory)
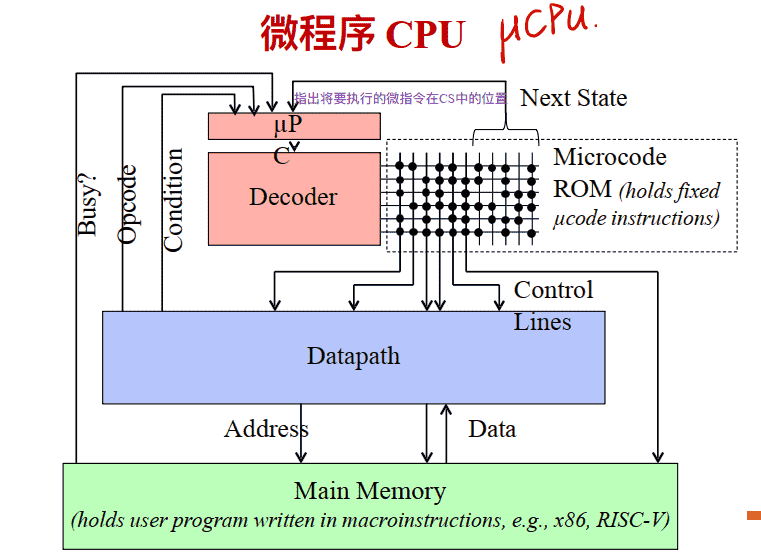
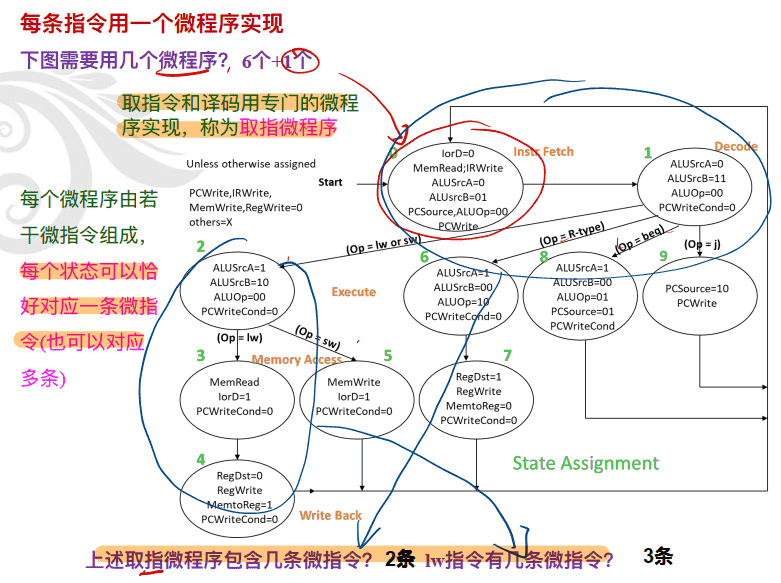
微程序设计思想
微程序控制器的基本结构
Microcode Implementation
微程序\微指令\微命令\微操作的关系
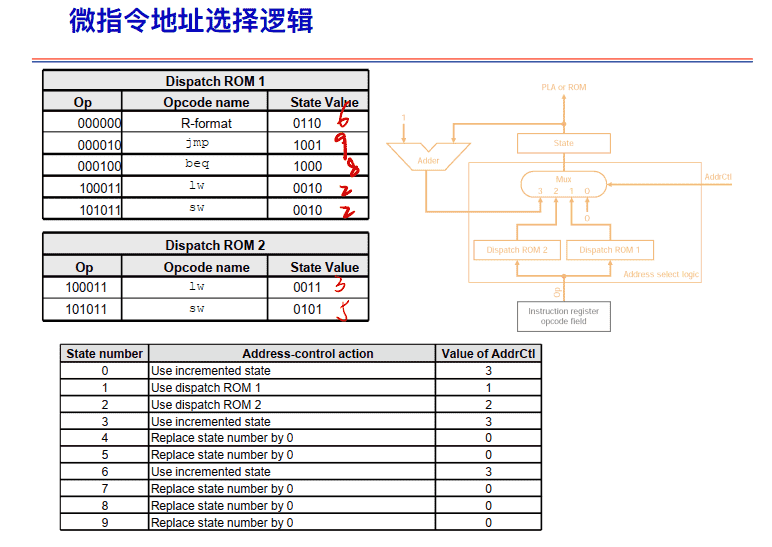
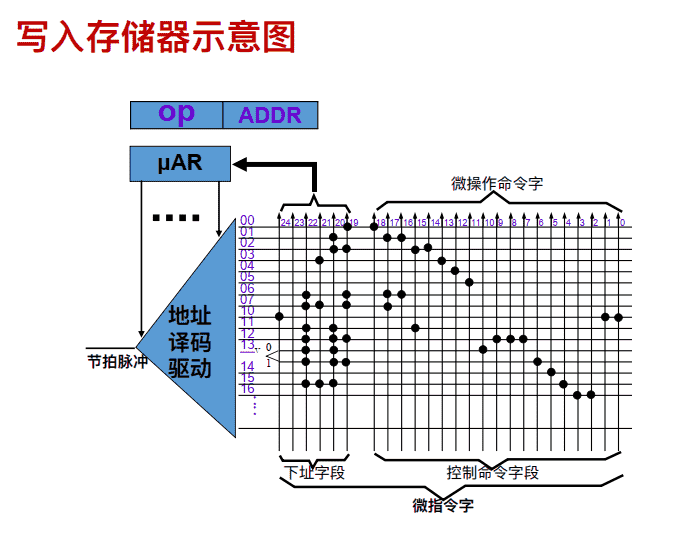
微指令地址选择逻辑
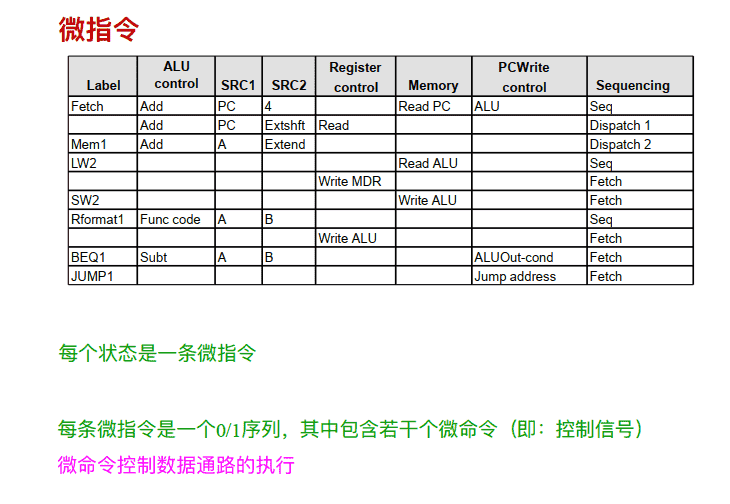
微指令的格式
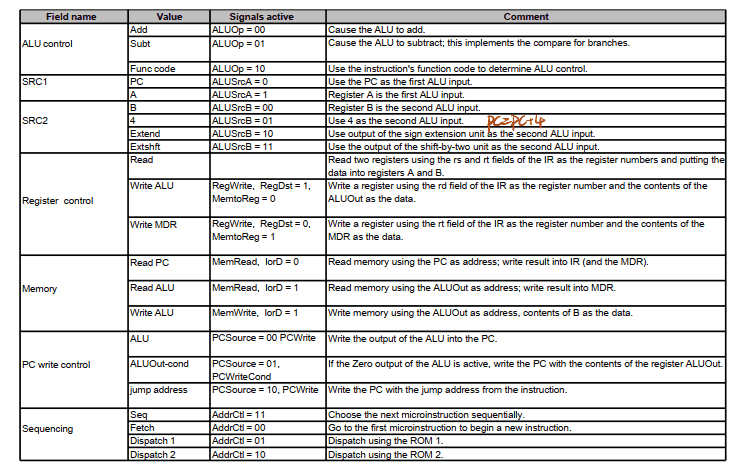
微程序控制器设计的⼀般步骤 (了解)
- 根据指令系统, 列出微操作序列
- 微指令编码
- 控制微程序流
- 确定指令格式
- 微程序写⼊控制存储器
写⼊存储器示意图
意外和中断(Exceptions and Interrupts)

异常和中断的处理


处理器中的异常处理机制


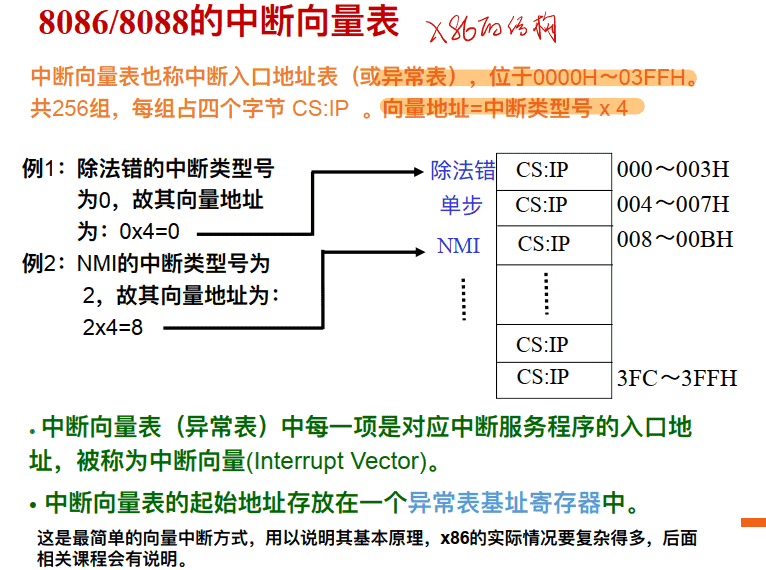
举例-8086/8088中断系统(采⽤向量中断⽅式)

8086/8088的中断向量表
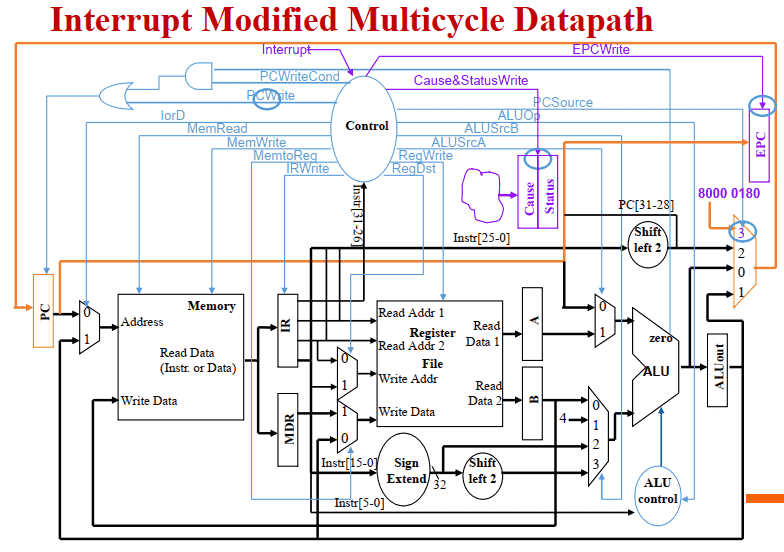
MIPS带异常处理的数据通路设计

Interrupt Modified Multicycle Datapath
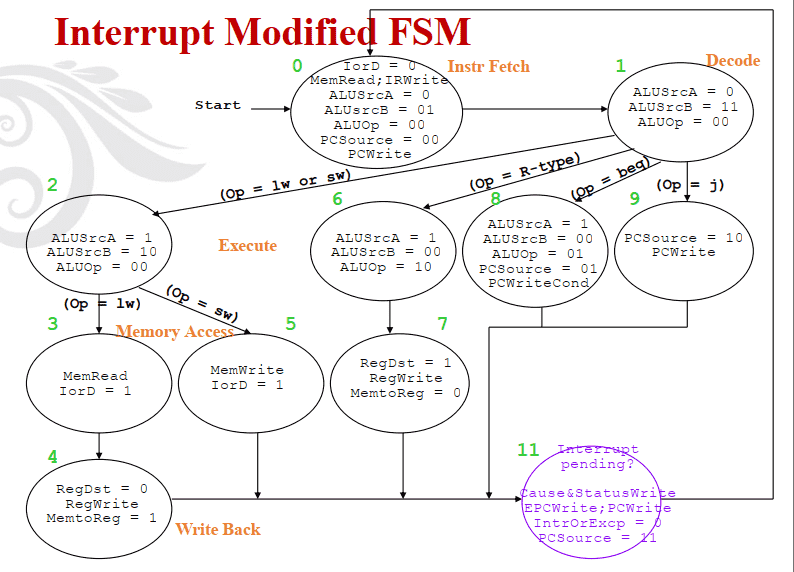
带异常处理的控制器设计

Interrupt Modified FSM
Trap Modified Multicycle Datapath
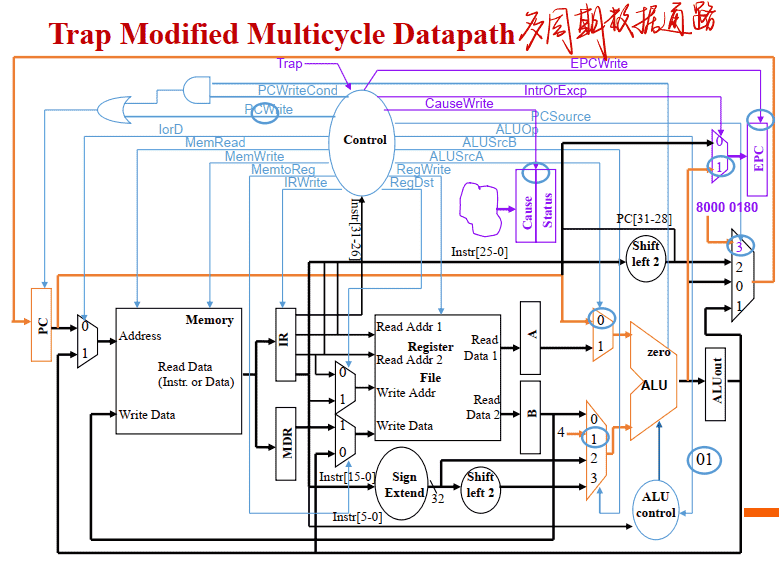
How Control Detects Two Traps
- 未定义指令(RI) – 状态1检测到下⼀个状态没有定义,既没有相应的操作码 • 所有未定义指令的下⼀个状态为新状态 10
- 算数运算溢出(Ov) – ALU溢出信号在状态6出现 (即不再有结果写⼊寄存器操作)
- 需要修正状态图 • 挑战在于处理指令和引发异常的事件之间的交互, 以使控制逻辑保持⼩⽽快 • 复杂的交互使控制单元成为硬件设计中最具挑战性的事情, 尤其是在流⽔线处理器中
Trap Modified FSM
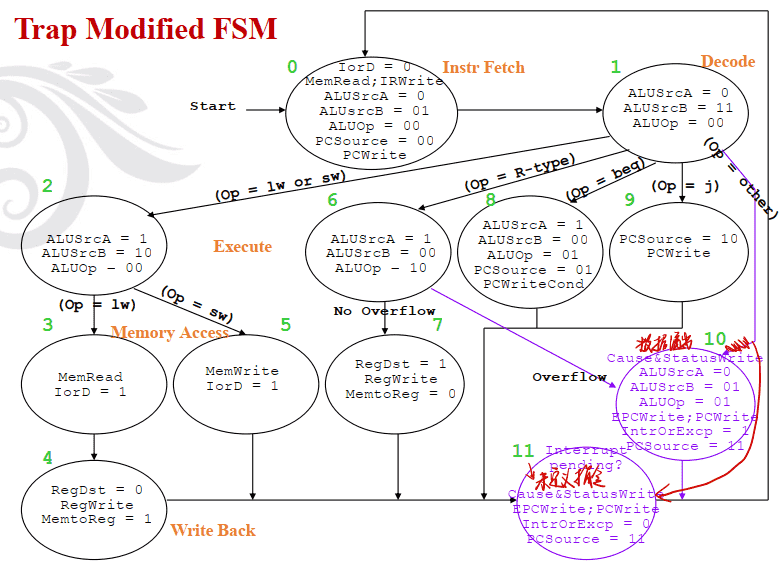
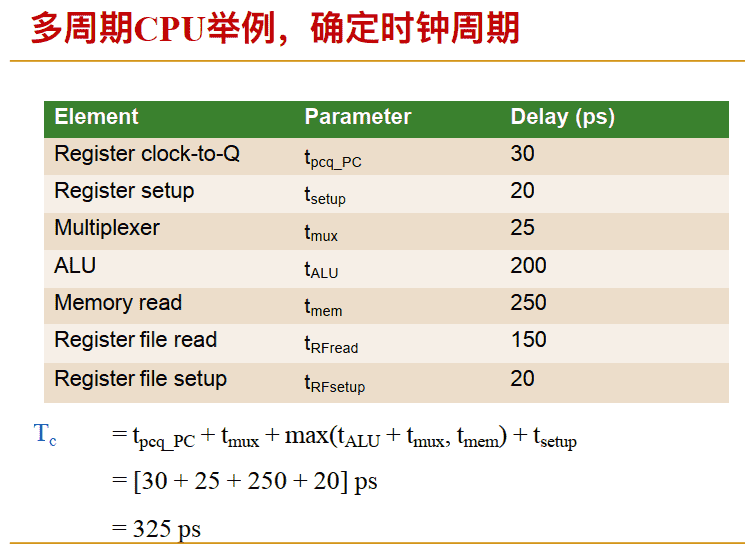
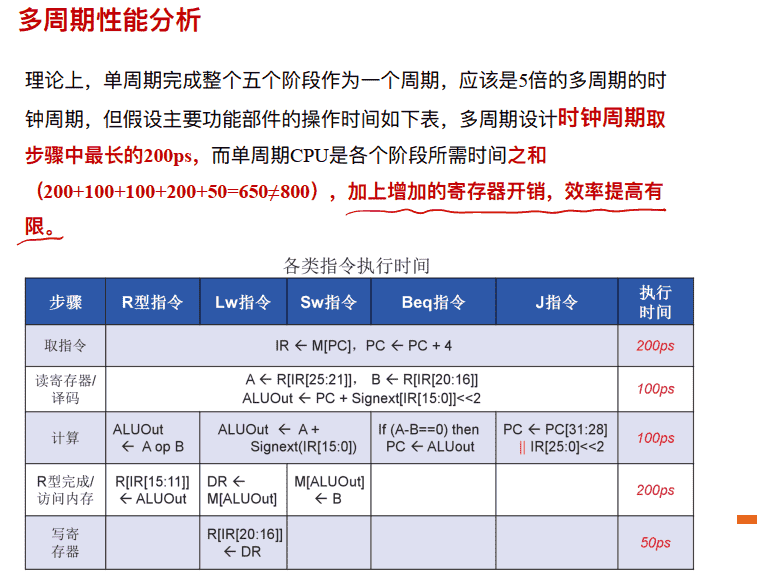
例子:多周期和单周期性能分析
多周期性能分析
- 与单周期CPU对⽐, 分成了多个阶段 + 时钟周期减少 – High CPI每个指令所需周期数增加了
- CPI 取决于指令 • Branches / Jumps: 3 cycles • ALU: 4 cycles • Stores: 4 cycles • Loads: 5 cycles •CPI 算平均CPI, 取决于权重
- ⽐如: • 20% loads, 15% stores, 20% branches, 45% ALU CPI= 0.20 * 5 + 0.15 * 4 + 0.20 * 3 + 0.45 * 4 = 4.0
单周期
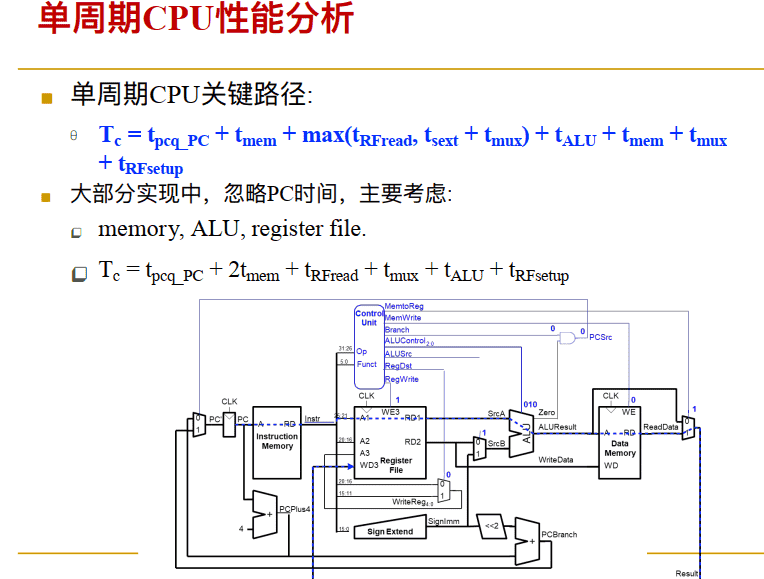
单周期CPU性能分析举例
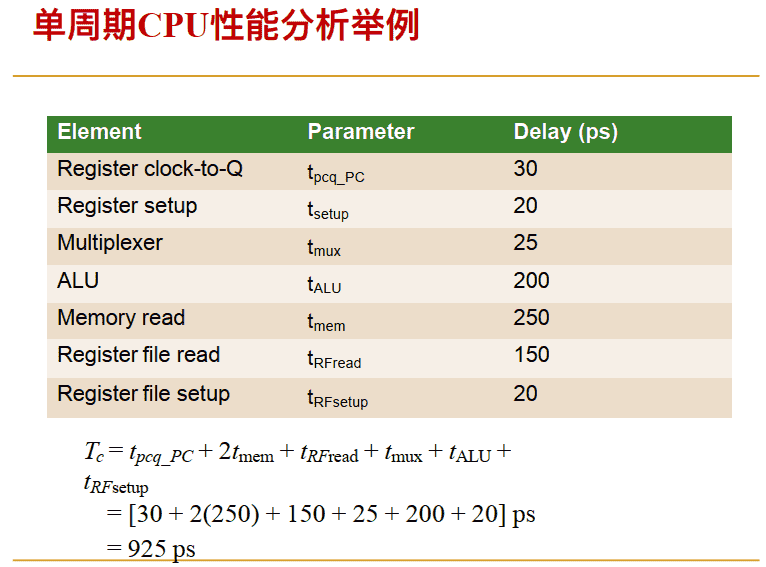
Example: ⼀个程序有 100 billion 条指令, 在单周期CPU上执⾏:
Execution Time = number of instructions x CPI x Tc = (100 × 10^9)(1)(925 × 10^-12 s)= 92.5 seconds
多周期